ParallelComputingJPPF
(quoted from Parallel Computing definition in Wikipedia)
Parallel computing is a form of computation in which many calculations are carried out simultaneously, operating on the principle that large problems can often be divided into smaller ones, which are then solved concurrently ("in parallel").
Traditionally, computer software has been written for serial computation. To solve a problem, an algorithm is constructed and implemented as a serial stream of instructions. These instructions are executed on a central processing unit on one computer. Only one instruction may execute at a time, after that instruction is finished, the next is executed.
Parallel computing, on the other hand, uses multiple processing elements simultaneously to solve a problem. This is accomplished by breaking the problem into independent parts so that each processing element can execute its part of the algorithm simultaneously with the others. The processing elements can be diverse and include resources such as a single computer with multiple processors, several networked computers, specialized hardware, or any combination of the above.
There are several different forms of parallel computing: bit-level, instruction level, data, and task parallelism. JEM decides to face this topic using JPPF (Java Parallel Processing Framework), which implements mainly task parallelism.
A JPPF grid is made of three different types of components that communicate together:
- clients are entry points to the grid and enable developers to submit work via the client APIs
- servers are the components that receive work from the clients, dispatch it to the nodes, receive the results fom the nodes, and send these results back to the clients
- nodes perform the actual work execution
To understand how the work is distributed in a JPPF grid, and what role is played by each component, we will start by defining the two units of work that JPPF handles.
- A task is the smallest unit of work that can be handled in the grid. From the JPPF perspective, it is considered atomic
- A job is a logical grouping of tasks that are submitted together, and may define a common service level agreement (SLA) with the JPPF grid.
The SLA can have a significant influence on how the job's work will be distributed in the grid
Parallel computing is not main goal of JEM but, for sure, parallel computing plays a main role on batch execution, to reduce elapsed time of batches, JEM decides to delegate this work to JPPF grid, implementing specific task (both for Apache ANT and for SpringBatch) to submit jobs on grid.
Here is architecture how it works:
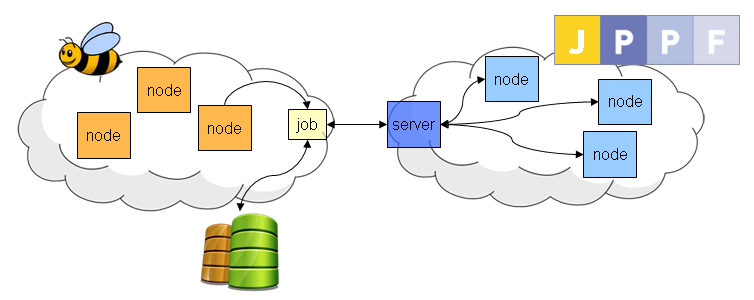
To address workload on JPPF grid, JEM implements a JPPF client (well-configured) which is connected to JPPF Server. To configure well the client, there 3 methods:
- create a properties file, as indicated on JPPF documentation, that is used by a data description. The name of this data description is not configurable and must be
JPPF-CONFIG - set
addressattribute of XML element used in JCL (attribute overrides properties file, if defined) - create a JEM resource, JPPF type, and address it by a
datasourceJCL definition (resource properties overrides both properties file and element attributes, if defined)
Tasks with business logic to execute on JPPF grid could be both java.lang.Runnable or org.jppf.server.protocol.JPPFTask, which has got more features (as cancel or timeout notifications). In eithers, the business logic must be coded inside of run method.
All resources defined on JCL (data descriptions, datasets, data sources, etc) will be brought on grid, available for task by usual JNDI context. Data description resources, used in tasks, allow you to access to JEM Global File System without mount it on grid. All streams are redirected to JPPF client (then inside of JEM job) which can access to files. An exception is when a data description is defined together with a datasource (i.e. for FTP connection). All other resources (JDBC, HTTP, JMS, FTP) will be used from grid, connecting directly to resources.
To access to JNDI context from task, it is mandatory to use the static method UniqueInitialContext.getContext(), which can get safe the initial context cross threads (because JPPF server is a multi-threading framework).
Standard output and error streams, produced by task, are redirected to job in execution on JEM node and stored on output of job.
Depending on business use cases, a task can do many things. JEM and JPPF try to help the business logic execution on grid, providing some features. Usually a task needs data to perform own business logic.
In a parallel environment you should split all data that you needs in several pieces (or chunks) that every task can read and use. JEM can provide this feature, creating several piece of a file, assigning one to every task. This works only with data descriptions that represent a single file, because a random access file is used. But usually it's not enough to split in parts with the same length because data often are different length. Passing to JEM a delimiter char, JEM can split the file using this delimiter so the reading from task is always consistent.
Because parallel tasks are anyway seen as a unique unit of work, and because usually a task writes data for further computings, JEM provides the features to split a output stream in different pieces to gie to tasks, and their ending to merge all results in the data description defined for that.
All these features will be described on the next sections.
To use JPPF in Apache ANT on JEM environment, there is a specific Apache ANT task org.pepstock.jem.jppf.StepJPPF.
This task accepts 3 attributes:
-
runnable: is mandatory attribute that represents fully class name to execute on JPPF grid. Could be bothjava.lang.Runnableororg.jppf.server.protocol.JPPFTask. -
datasource: is optional attribute that represents the name JPPF resource defined in JCL and used to get JPPF servers configurations. -
address: is optional attribute that represents the list of JPPF servers. This list is used by client to connect JPPF server. The list is composed by addresses (in formatip-address:portorhost:port), comma separated. -
parallelTaskNumber: is optional attribute that represents how many task you want to execute in parallel on grid. Default is number of available processors. -
delimiter: is optional attribute that represent the character to use to split file in chunks. Default isSystem.getProperty("line.separator"). This can have 2 formats:-
java escape char: for example\rsays to use LF as delimiter for chunks -
hexadecimal byte: for example0x00says to use x'00' as delimiter for chunks
-
-
delimiterString: is optional attribute that represent the string to use to split file in chunks. -
chunckableDataDescription: is optional attribute that represent the name of data description to be splitted in several pieces for tasks. Data description must exist and indicates a single file. To calculate the length of chunks, it divides the length of file for number of parallel task (argument of Apache ANT task) and searches the delimiter to have the consistent chunks. This calculation can reduce the number of tasks to execute, overriding the value passed by Apache ANT task. -
mergedDataDescription: is optional attribute that represent the name of data description to be used where it will merge the result of all tasks, after their execution. It merges only if all tasks end correctly, without any exception.
Following some examples which explain HOW-TO.
<taskdef name="jppf" classname="org.pepstock.jem.jppf.StepJPPF"/>
<target name="execute">
<jppf runnable="test.MyJPPFTask" parallelTaskNumber="5" datasource="jppf">
<dataSource name="jppf" resource="JPPFLocalhost"/>
</jppf>
</target><taskdef name="jppf" classname="org.pepstock.jem.jppf.StepJPPF"/>
<target name="execute">
<jppf runnable="test.MyJPPFTask" parallelTaskNumber="5" address="localhost:11111, localhost:11112">
</jppf>
</target><taskdef name="jppf" classname="org.pepstock.jem.jppf.StepJPPF"/>
<target name="execute">
<jppf runnable="test.MyJPPFTask" parallelTaskNumber="5">
<dataDescription name="JPPF-CONFIG" disposition="SHR">
<dataSet>
#jppf.ssl.enabled=true
jppf.discovery.enabled=false
jppf.drivers=main
main.jppf.server.port=11111
main.jppf.server.host=localhost
</dataSet>
</dataDescription>
</jppf>
</target><taskdef name="jppf" classname="org.pepstock.jem.jppf.StepJPPF"/>
<target name="execute">
<echo message="Entering jppf task..." />
<jppf runnable="org.pepstock.jem.jppf.test.MyRunnable" parallelTaskNumber="5" datasource="jppf"
chunkableDataDescription="INPUT" delimiter="\r">
<dataSource name="jppf" resource="JPPFLocalhost"/>
<dataDescription name="INPUT" disposition="SHR">
<dataSet name="gdg/jemtest(0)"/>
</dataDescription>
</jppf>
</target>Here is java source code of task:
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
@Override
public void run() {
try {
InitialContext ic = UniqueInitialContext.getContext();
Object o1 = (Object) ic.lookup("INPUT");
InputStream is = (InputStream)o1;
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line = null;
while((line = reader.readLine()) != null){
System.out.println(line);
}
is.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}<taskdef name="jppf" classname="org.pepstock.jem.jppf.StepJPPF"/>
<target name="execute">
<echo message="Entering jppf task..." />
<jppf runnable="org.pepstock.jem.jppf.test.MyRunnable" parallelTaskNumber="5" datasource="jppf"
mergedDataDescription="OUTPUT">
<dataSource name="jppf" resource="JPPFLocalhost"/>
<dataDescription name="OUTPUT" disposition="NEW">
<dataSet name="gdg/jemtest(+1)"/>
</dataDescription>
</jppf>
</target>Here is java source code of task:
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
@Override
public void run() {
try {
InitialContext ic = UniqueInitialContext.getContext();
StringBuffer sb = new StringBuffer("This is what I want to write");
Object o2 = (Object) ic.lookup("OUTPUT");
OutputStream os = (OutputStream)o2;
BufferedOutputStream bos = new BufferedOutputStream(os);
bos.write(sb.toString().getBytes());
bos.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}To use JPPF in SpringBatch on JEM environment, there is a specific SpringBatch tasklet org.pepstock.jem.jppf.JPPFTasklet.
The tasklet accepts all data descriptions (as a normal JEM tasklet) and a specific bean org.pepstock.jem.jppf.JPPFBean, with the following information:
-
runnable: is mandatory attribute that represents fully class name to execute on JPPF grid. Could be bothjava.lang.Runnableororg.jppf.server.protocol.JPPFTask. -
datasource: is optional attribute that represents the name JPPF resource defined in JCL and used to get JPPF servers configurations. -
address: is optional attribute that represents the list of JPPF servers. This list is used by client to connect JPPF server. The list is composed by addresses (in formatip-address:portorhost:port), comma separated. -
parallelTaskNumber: is optional attribute that represents how many task you want to execute in parallel on grid. Default is number of available processors. -
delimiter: is optional attribute that represent the character to use to split file in chunks. Default isSystem.getProperty("line.separator"). This can have 2 formats:-
java escape char: for example\rsays to use LF as delimiter for chunks -
hexadecimal byte: for example0x00says to use x'00' as delimiter for chunks
-
-
delimiterString: is optional attribute that represent the string to use to split file in chunks. -
chunckableDataDescription: is optional attribute that represent the name of data description to be splitted in several pieces for tasks. Data description must exist and indicates a single file. To calculate the length of chunks, it divides the length of file for number of parallel task (argument of Apache ANT task) and searches the delimiter to have the consistent chunks. This calculation can reduce the number of tasks to execute, overriding the value passed by Apache ANT task. -
mergedDataDescription: is optional attribute that represent the name of data description to be used where it will merge the result of all tasks, after their execution. It merges only if all tasks end correctly, without any exception.
Following some examples which explain HOW-TO.
<beans:bean id="jppf" class="org.pepstock.jem.jppf.JPPFTasklet">
<beans:property name="bean" ref="jppf.bean" />
<beans:property name="dataSourceList">
<beans:list>
<beans:ref local="datasource"/>
</beans:list>
</beans:property>
</beans:bean>
<beans:bean id="jppf.bean" class="org.pepstock.jem.jppf.JPPFBean">
<beans:property name="runnable" value="test.MyJPPFTask" />
<beans:property name="address" value="localhost:11111" />
<beans:property name="parallelTaskNumber" value="5" />
<beans:property name="datasource" value="jppf" />
</beans:bean>
<beans:bean id="datasource" class="org.pepstock.jem.springbatch.tasks.DataSource">
<beans:property name="name" value="jppf" />
<beans:property name="resource" value="JPPFLocalhost" />
</beans:bean><beans:bean id="jppf" class="org.pepstock.jem.jppf.JPPFTasklet">
<beans:property name="bean" ref="jppf.bean" />
<beans:property name="dataDescriptionList">
<beans:list>
<beans:ref local="JPPF-CONFIG"/>
</beans:list>
</beans:property>
</beans:bean>
<beans:bean id="jppf.bean" class="org.pepstock.jem.jppf.JPPFBean">
<beans:property name="runnable" value="test.MyJPPFTask" />
<beans:property name="parallelTaskNumber" value="5" />
</beans:bean>
<beans:bean id="jppf" class="org.pepstock.jem.jppf.JPPFTasklet">
<beans:property name="bean" ref="jppf.bean" />
<beans:property name="dataSourceList">
<beans:list>
<beans:ref local="datasource"/>
</beans:list>
</beans:property>
</beans:bean>
<beans:bean id="jppf.bean" class="org.pepstock.jem.jppf.JPPFBean">
<beans:property name="runnable" value="test.MyJPPFTask" />
<beans:property name="parallelTaskNumber" value="5" />
<beans:property name="datasource" value="jppf" />
<beans:property name="chunkableDataDescription" value="INPUT" />
<beans:property name="delimiter" value="\r" />
</beans:bean>
<beans:bean id="datasource" class="org.pepstock.jem.springbatch.tasks.DataSource">
<beans:property name="name" value="jppf" />
<beans:property name="resource" value="JPPFLocalhost" />
</beans:bean>
<beans:bean id="INPUT" class="org.pepstock.jem.springbatch.tasks.DataDescription">
<beans:property name="name" value="INPUT" />
<beans:property name="disposition" value="SHR" />
<beans:property name="datasets">
<beans:list>
<beans:bean class="org.pepstock.jem.springbatch.tasks.DataSet">
<beans:property name="name" value="gdg/jemtest(0)" />
</beans:bean>
</beans:list>
</beans:property>
</beans:bean>Here is java source code of task (the same task used for Apache ANT):
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
@Override
public void run() {
try {
InitialContext ic = UniqueInitialContext.getContext();
Object o1 = (Object) ic.lookup("INPUT");
InputStream is = (InputStream)o1;
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line = null;
while((line = reader.readLine()) != null){
System.out.println(line);
}
is.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}<beans:bean id="jppf" class="org.pepstock.jem.jppf.JPPFTasklet">
<beans:property name="bean" ref="jppf.bean" />
<beans:property name="dataSourceList">
<beans:list>
<beans:ref local="datasource"/>
</beans:list>
</beans:property>
</beans:bean>
<beans:bean id="jppf.bean" class="org.pepstock.jem.jppf.JPPFBean">
<beans:property name="runnable" value="test.MyJPPFTask" />
<beans:property name="parallelTaskNumber" value="5" />
<beans:property name="datasource" value="jppf" />
<beans:property name="mergedDataDescription" value="OUTPUT" />
</beans:bean>
<beans:bean id="datasource" class="org.pepstock.jem.springbatch.tasks.DataSource">
<beans:property name="name" value="jppf" />
<beans:property name="resource" value="JPPFLocalhost" />
</beans:bean>
<beans:bean id="OUTPUT" class="org.pepstock.jem.springbatch.tasks.DataDescription">
<beans:property name="name" value="OUTPUT" />
<beans:property name="disposition" value="NEW" />
<beans:property name="datasets">
<beans:list>
<beans:bean class="org.pepstock.jem.springbatch.tasks.DataSet">
<beans:property name="name" value="gdg/jemtest(+1)" />
</beans:bean>
</beans:list>
</beans:property>
</beans:bean>Here is java source code of task (the same task used for Apache ANT):
/* (non-Javadoc)
* @see java.lang.Runnable#run()
*/
@Override
public void run() {
try {
InitialContext ic = UniqueInitialContext.getContext();
StringBuffer sb = new StringBuffer("This is what I want to write");
Object o2 = (Object) ic.lookup("OUTPUT");
OutputStream os = (OutputStream)o2;
BufferedOutputStream bos = new BufferedOutputStream(os);
bos.write(sb.toString().getBytes());
bos.close();
} catch (Exception e) {
throw new RuntimeException(e);
}
}To use JPPF in SpringBatch on JEM environment, there is a specific SpringBatch tasklet org.pepstock.jem.jppf.JPPFTasklet.
With the extensible XML authoring (for all detailed information please see here), a new XML tag has been created and you can use as following:
<jem:jppf-tasklet id="test">
<jem:jppf-configuration runnable="org.pepstock.jem.testjppf.SimpleJPPFTask" address="localhost:11111" parallelTaskNumber="5"/>
</jem:jppf-tasklet>jppf-configuration element configures the connection to JPPF grid. It's also possible to use a common resource (for JPPF) as following:
<jem:jppf-tasklet id="test">
<jem:jppf-configuration runnable="org.pepstock.jem.testjppf.SimpleJPPFTask" parallelTaskNumber="5"/>
<jem:dataSource name="JPPF" resource="JPPFLocalhost"/>
</jem:jppf-tasklet>It is also possible to configure JPPF by a properties file (using all properties metioned by JPPF configuration documentation), using datadescription, as following:
<jem:jppf-tasklet id="test">
<jem:jppf-configuration runnable="org.pepstock.jem.testjppf.SimpleJPPFTask" parallelTaskNumber="5"/>
<jem:dataDescription name="JPPF-CONFIG" disposition="SHR">
<jem:dataSet name="jppf.config" />
</jem:dataDescription>
</jem:jppf-tasklet>Inside of jppf-tasklet, you can configure all datadescriptions, datasets, locks and datasources necessary for your business logic, as following:
<jem:jppf-tasklet id="test">
<jem:jppf-configuration runnable="org.pepstock.jem.testjppf.JPPFTaskDatasource" address="localhost:11111"/>
<jem:dataSource name="JUNIT_JDBC_JEM" resource="JUNIT_JDBC_JEM"/>
</jem:jppf-tasklet>At runtime, a task can have some information about itself, information helpful to create a custom logic to divide data or other to perform actions.
The class, callable simply with TaskData task = TaskInfo.getTaskData(), provides:
- Index: position of task in tasks list of JPPF job
- Total: tasks list size of JPPF job
-
isFirst:
trueif task is the first in tasks list -
isLast:
trueif task is the last in tasks list