Server site: https://xomicsshiny.bxgenomics.com/
Tutorial: https://interactivereport.github.io/xOmicsShiny/tutorial/docs/index.html
Paper: https://academic.oup.com/bioinformaticsadvances/article/5/1/vbaf097/8145566
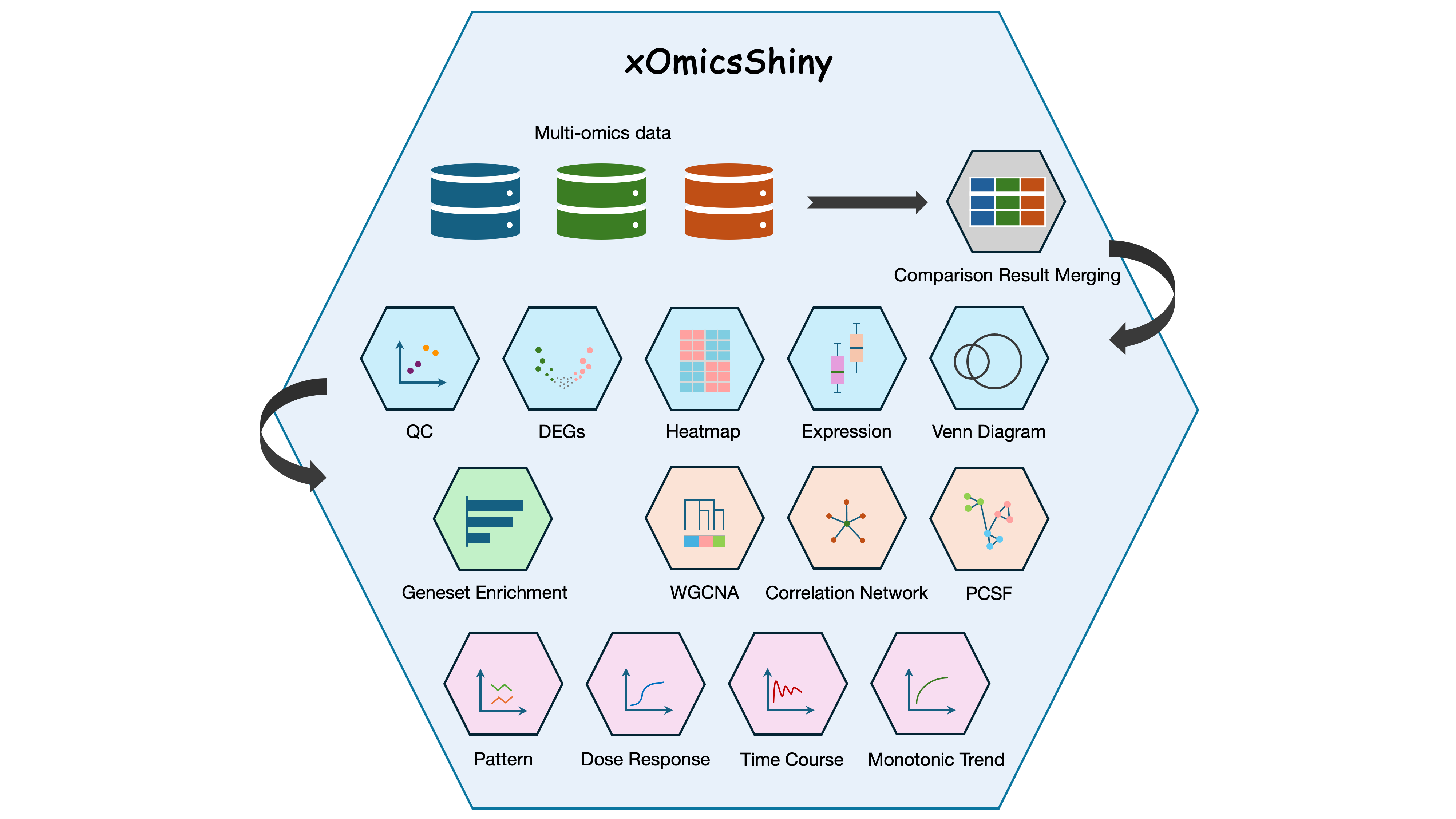
Cover Image: Overview of the xOmicsShiny modules. The Shiny application handles multi-omics data including transcriptomics, proteomics, metabolomics, and lipidomics data. The Comparison Result Merging (Grey) module integrates multi-omics comparison results for downstream analysis. Data exploration modules (Blue) contain QC, DEGs, Heatmap, Expression, and Venn Diagram modules. Geneset Enrichment (Green) module performs GSEA and pathway analysis. Network modules (Bisque) include WGCNA, Correlation Network, and PCSF modules. Pattern and trend analysis (Orchid) consists of Pattern, Dose Response, Time Course, and Monotonic Trend modules.
Users can readily explore xOmicsShiny using our public server (https://xomicsshiny.bxgenomics.com/). We have prepared several public datasets for you:
| Study | Datasets | References |
|---|---|---|
| Aging Mice with High fat (HF) and Control Diet (CD), Multi-omics | AgingHFCD_RNAseq, AgingHFCD_Proteomics, AgingHFCD_Metabolomics | Williams et al., 2022 |
| Cx3cr1-Deficient Mouse Microglia RNA-Seq Demo Data | Mouse Microglia RNA | Gyoneva et al., 2019 |
| LRRK2 Human Neuron Transcriptome and Proteome Data | LRRK2 Neuron RNA and Proteome | Connor-Robson et al., 2019 |
| Human Brain (Cortex/ACG) Proteome in AD and PD | ADPD_cortex_Maxquant, ADPD_ACG_Maxquant, ADPD_cortex_Pdiscover, ADPD_ACG_Pdiscover | Ping et al., 2018 |
| StrokeBrain_TimeCourse Data | StrokeBrain_TimeCourse | Gu et al., 2021 |
Althrough we have provided a public server for users to explore xOmicsShiny, the application can also be installed on your own device. Please follow the instructions below:
We recommend using the renv package to create the environment for xOmicsShiny. We have included a R4.2.2 renv.lock file on GitHub for you to set up renv environment. Below are example codes to set up the renv.
Copy the renv.lock file to your project folder, and go to the project directory (from R command or from R Studio), run the following code:
renv::status()
#The next three lins are optional, but may help speed up the installation process
rHome <- R.home()
renv::init(bare=T,settings=list(external.libraries=file.path(rHome,"library")),restart=T)
options(renv.config.install.transactional = FALSE)
renv::restore()
If there are packages that failed to install, most likely certain programs are missing on your system, please read the error message and try to install the programs, then come back to R to install the packages.
(Not recommended), alternatively, you can try to install all the packages manually from R command line in your system.
#Install CRAN packages
cran_packages=c("shiny", "shinythemes", "shinyalert", "shinyjqui", "shinyjs", "coop", "cluster", "devtools",
"plotly", "reshape2", "tidyverse", "gplots", "ggpubr", "svgPanZoom", "WGCNA","drc", "heatmaply","dendextend",
"gridExtra", "ggrepel", "RColorBrewer", "pheatmap", "rgl", "car", "colourpicker", "VennDiagram", "factoextra",
"openxlsx", "visNetwork", "cowplot", "circlize", "svglite", "Hmisc", "ggrastr", "ggpmisc","ggprism","parallel",
"ggExtra", "networkD3", "vctrs", "ragg", "textshaping", "stringi", "plyr", "png", "psych", "broom", "rclipboard")
#Note: Hmisc is not required to run the Shiny app but is needed to prepare network data from expression matrix.
install.packages(cran_packages, repos="http://cran.r-project.org/") #choose repos based on your location if needed
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install(c("Mfuzz", "biomaRt", "ComplexHeatmap", "pathview", "fgesa", "org.Hs.eg.db", "org.Mm.eg.db", "org.Rn.eg.db"))
#Install PCSF
devtools::install_github("IOR-Bioinformatics/PCSF", repos=BiocInstaller::biocinstallRepos(),
dependencies=TRUE, type="source", force=TRUE)
The config.csv in the project folder is required by the system. We have included an example configure file on GitHub. You can modify the file to fit your system.
- server_dir: the directory to hold project Rdata files which can be loaded in the URL as ?server_file=project_ID
- test_dir: Not use, can ignore
- gmt_file_info: the csv file listing all the gmt files used in gene set enrichment. See below for more details.
(Optional) If you have a list of data files for the system to display as “Saved Projects in CSV file”, save the RData is data/ folder under the project folder, and include a file called saved_projectsNEW.csv in the data/ folder. See the example saved_projectsNEW.csv on GitHub.
For more instructions, see the full tutorial here.
If you would like to upload your own data, please follow the instructions below to prepare your input files.
The application supports various omics types, including RNA-seq, Proteomics, Metabolomics, Lipidomics, etc. To upload your own data, users need to prepare the following files. See an example here containing files generated from a published paper.
- Sample MetaData File: At leaset
sampleidandgroupare required.sampleidshould match those used in expression data, andgroupholds group names of samples. Additional metadata columns about samples are optional. - Expression Data File: Full data matrix, with each row is a gene/protein/metabolite, and each column is a data. The column names should match the ones in Sample MetaData file.
- Comparison Data File: This file stores differential expression (DE) anlaysis results. It requires the following columns:
UniqueIDcontains the gene/protein/metabolite names. This column allows duplicated names as the same gene may be involved in different comparisons. Thetestcolumn indicates the DE comparison name. TheAdj.P.Value,P.Value, andlogFCcolumns store DE analysis results. - Gene/Protein Name File (Optional): This optional file creates a match between gene names, such as from ENSEMBL ID to Gene Symbol. It requires six columns:
id,UniqueID,Gene.Name,Protein.ID, andGeneType.
After preparing the above files, users can open the Shiny server, choose Dataset -> Select Dataset -> Upload Data Files (csv), upload the four files, then click Submit Data. It will take the server some time to process the data, and after that, users can explore the data with ease.
The application is under MIT license.