In this notebook, a vocabulary set of highly interpretive terms is built, which a classification model uses to predict the sentiment of a movie review. The data set consists of 50,000 IMDb movie reviews, where each review is labelled as positive or negative. A subset of this data set was used in a Kaggle competition: Bag of Words Meets Bags of Popcorn. Specifically, a classifier based on Regularized Logistic Regression (i.e., Binomial Ridge Regression) is implemented.
The final vocabulary selected for interpretation and prediction has 994 terms. Here are some example terms:
bad, worst, great, waste, awful, excellent, best, no, terrible, love, nothing,
worse, boring, wonderful, even, of_best, stupid, of_worst, well, horrible,
minutes, poor, at_all, perfect, crap, so_bad, also, money, plot, amazing, loved,
supposed, very, just, one_of, beautiful, avoid, script, ridiculous, why,
not_even, highly, poorly, acting, life, favorite, superb, 1, only, lame,
brilliant, annoying, wasted, pathetic, pointless, instead, enjoyed, cheap,
today, must_see, save, dull, oh, both, always, unless, any, don't, will,
laughable, very_well, could, years, least, fantastic, 2, badly, world, or,
fails, still, couldn't, heart, mess, make, performance, performances, to_make,
definitely, how_bad, garbage, reason, to_be, family, attempt, redeeming,
avoid_this, fun, especially, anything
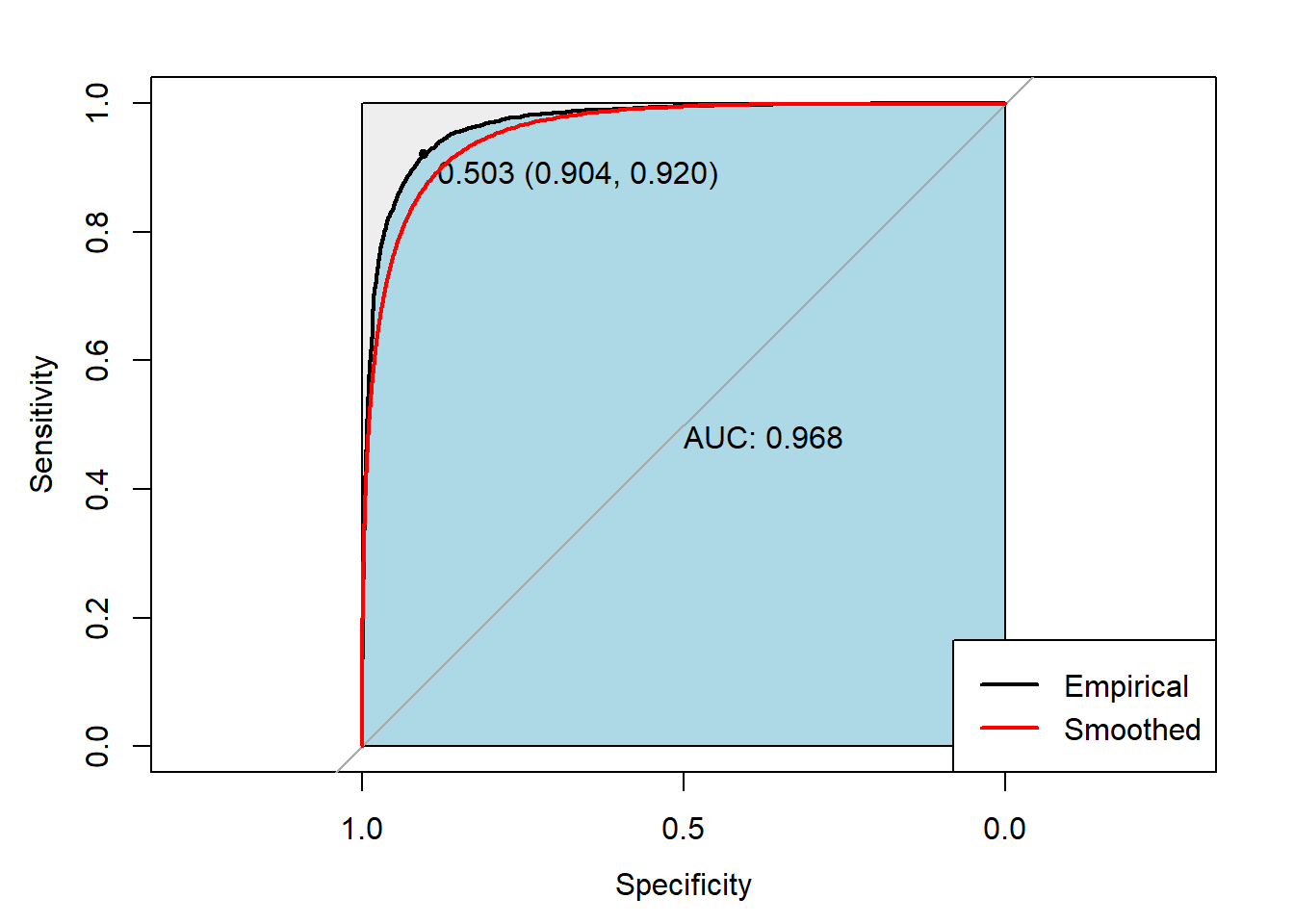
The Ridge Logistic Classifier performed sufficiently well with an AUROC score of 0.9684. So, it correctly predicted the sentiments of nearly 97% of the IMDb reviews in the test data.