Warning: This project allows a Large Language Model (LLM) to execute code and perform actions on the host machine, which can be potentially destructive and dangerous. Use this software at your own risk. The authors and contributors of this project are not responsible for any damage or data loss that may occur from using this software. It is strongly recommended to run this software in a controlled environment, such as a virtual machine or a container, to mitigate potential risks.
This is a generic version of the Station Explorer Assistant (SEA) project. The core of it is OpenAI's GPT-4.1 model that runs a local code interpreter using OpenInterpreter. It is essentially a web interface to the OpenInterpreter code interpreter. Comments about options for using alternative LLM inference endpoints are provided in the app.py script.
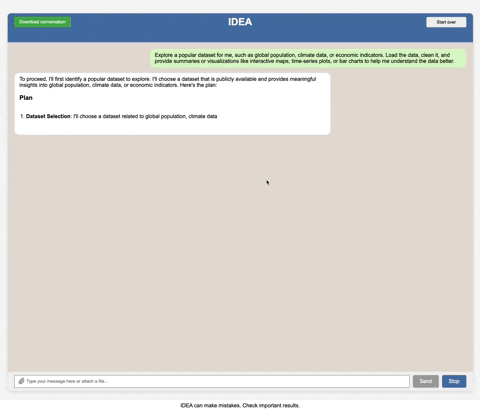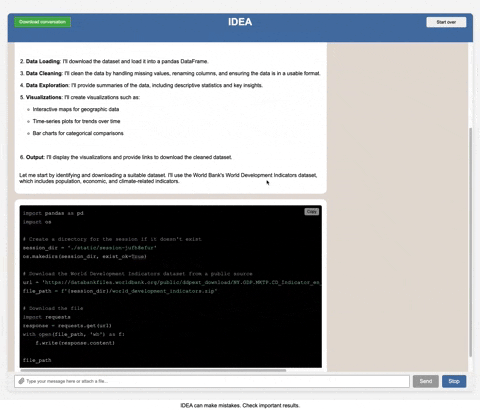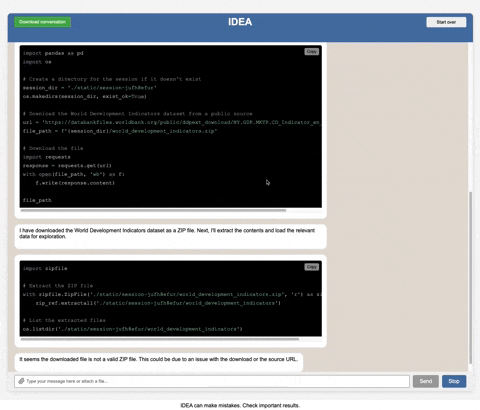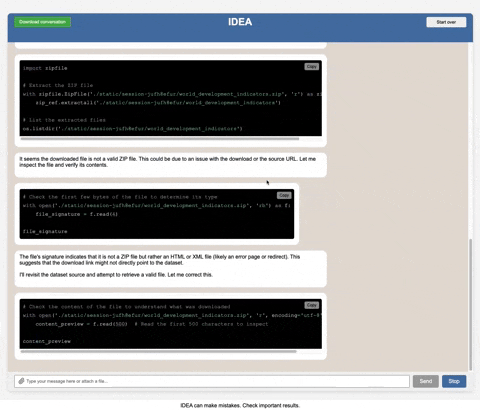
This is a single-user development tool, not a production-ready multi-user application. It includes basic authentication but is designed for one user at a time. Even with authentication, multiple simultaneous users will interfere with each other's sessions and data. It lacks many features typically found in enterprise production systems such as:
- Multi-user support with role-based access
- Database-backed user management
- Advanced security features (2FA, audit logs, etc.)
- Conversation history persistence across server restarts
- Enterprise-grade security guardrails
- Production-level error handling and monitoring
- Enterprise support
Security Warning: While this tool includes basic authentication, it is intended primarily for controlled environments. If deploying on a public server:
- Use strong, unique passwords
- Implement HTTPS
- Consider additional network security (VPN, IP whitelisting)
- Monitor access logs
- Keep the system updated
The Docker container provides some isolation, but should not be considered a complete security solution for highly sensitive environments.
This project serves as a starting point for developers looking to build their own AI-powered tools, but requires additional security hardening for sensitive production environments.
- Data Exploration: Easily search and filter any data
- Data Visualization: Generate plots and tables to visualize results.
- Data Download: Export data in any format for further study.
- Data Analysis: Automatically run analysis routines to generate and validate results.
- Data Upload: Upload data files for analysis.
- Live example: Station Explorer Assistant (SEA) project
- Publication preprint: Building an Intelligent Data Exploring Assistant (IDEA) for Geoscientists

- Docker & Docker Compose: Ensure Docker is installed on your system.
- API Key for LLM Inference: You need an API key from OpenAI or another LLM service provider.
To clone the IDEA-toZ branch (recommended for the Lost City of Z project):
git clone --branch IDEA-toZ https://github.com/uhsealevelcenter/IDEA.git
cd IDEACreate a .env file in the project root. You have two options:
- Option A: Rename the provided
example.envto.envand configure the required variables:OPENAI_API_KEY=YOUR_API_KEY_HERE # Authentication Configuration AUTH_USERNAME=admin AUTH_PASSWORD=your_secure_password_here
- Option B: Manually create a
.envfile with the necessary variables.
Important Security Notes:
- Change the default password before deploying to any environment
- Use a strong, unique password for the
AUTH_PASSWORD - Keep your
.envfile secure and never commit it to version control
Inside the frontend directory, create a config.js file. You can either copy from config.example.js or create one manually. (This file does not contain any secrets; it simply sets environment parameters.) This file is not checked in to the repo to avoid confusion with the production environment. It is a hacky solution but it works for now. The most important thing is that on the actual production server, the environment field in the config.js file is set to "production" and local is set to "local".
For local development, the repository includes a Docker Compose file (docker-compose-local.yml) and a helper script (local_start.sh). This setup supports live code reloading on the backend and mounts the source for immediate feedback (any code changes on the backend will be reflected immediately).
Run the helper script:
./local_start.shThis script will:
- Stop any running Docker containers defined in
docker-compose-local.yml. - Build and start the containers (including backend, frontend, nginx, and redis).
- Tail the logs of the backend container for quick debugging.
Note: The first time you run this, it will take a while because it has to download the docker image and install the dependencies.
- Backend (web): Runs the API with hot-reload enabled (
uvicorn app:app --reload). - Frontend: A static server (using Python's
http.server) running on port 8000. Useful for direct access and testing. http://localhost - NGINX: Reverse-proxy and static file server available on port 80.
- Redis: In-memory store for caching, running on port 6379.
You should now be able to run IDEA locally and make changes to the code. Visit http://localhost to access the application.
First Time Login:
- You'll be redirected to a login page at
http://localhost/login.html - Use the credentials you set in your
.envfile:- Username:
admin(or your custom username) - Password: The password you set in
AUTH_PASSWORD
- Username:
- After successful login, you'll be redirected to the main application
Authentication Features:
- Session Management: Login tokens are valid for 24 hours
- Logout: Use the logout button in the navigation bar
- Auto-redirect: If your session expires, you'll be automatically redirected to login
- Mobile Support: Logout option available in the mobile hamburger menu
The production setup uses a separate Docker Compose configuration (docker-compose.yml) along with the production_start.sh script.
Ensure your production .env file includes secure authentication credentials:
OPENAI_API_KEY=your_production_api_key
# Authentication Configuration - USE STRONG PASSWORDS!
AUTH_USERNAME=your_admin_username
AUTH_PASSWORD=your_very_secure_production_password
# Other production variables
LOCAL_DEV=0
PQA_HOME=/app/data
PAPER_DIRECTORY=/app/data/papersCritical Security Steps:
- Use strong, unique passwords - Never use default passwords in production
- Secure your
.envfile - Ensure proper file permissions (600) and restrict access - HTTPS Only - Always use HTTPS in production (configure your reverse proxy/load balancer)
- Network Security - Ensure the application is only accessible through your intended network configuration
- Regular Updates - Keep dependencies and base images updated
The production_start.sh script will:
- Stop any running services defined in
docker-compose.yml - Build and run the new containers in detached mode
- Apply your production environment variables
./production_start.shProduction Access:
- Users will need to login with the credentials specified in your production
.envfile - Consider implementing additional security measures like IP whitelisting or VPN access
- Monitor login attempts and session activity for security purposes
- Single-User Design: IDEA is designed for ONE USER AT A TIME
- Simultaneous Usage Warning: If multiple users access the application simultaneously using the same login credentials, they will share:
- The same conversation history
- The same file uploads and session data
- The same interpreter instance and code execution context
- Unpredictable Behavior: Multiple simultaneous users can cause data corruption, unexpected responses, and interfering code executions
- Recommendation: Ensure only one person uses the application at a time, or deploy separate instances for different users
.
├── app.py # Main application entry point (backend)
├── Dockerfile # Docker container build configuration
├── docker-compose.yml # Production Docker Compose configuration
├── docker-compose-local.yml # Local Docker Compose configuration
├── local_start.sh # Local development startup script
├── production_start.sh # Production deployment script for the backend
├── requirements.txt # Python dependencies
├── data/ # Directory storing datasets, benchmarks, and additional data
├── frontend/ # Frontend static assets (HTML, CSS, JS)
├── nginx.conf # NGINX configuration for reverse proxy and static files, used only for local development and set to mimic production
└── utils/
└── system_prompt.py # Configuration file for the system prompt (LLM)
system_prompt.py is the system prompt for the LLM. It is used to set the behavior of the LLM. It is probably the most important file in the project. You can alter the behavior of the LLM by editing this file and adjust it to your own needs.
- Data Directory: Contains subdirectories for benchmarks, metadata, altimetry, and papers. papers is the directory containing the peer reviewed papers that are indexed by PaperQA2.
When develping locally, you can simply add new publications to the
data/papersdirectory and newly added PDFs will be automatically indexed upon first relevant question that invokes the use of thepqacommand (e.g. asking the AI to perform literature review). - Note: In production, you cannot simply copy the data to
data/paperson your local machine because that directory is not mounted in the container in production. You would have to copy the data to the production server and then copy the data directly to the container at the same location (e.g./app/data/papers).
The settings for PaperQA2 indexing are in data/.pqa/settings/my_fast.json and data/.pqa/settings/pqa_settings.py. These files define the model and parameters used to index the papers. You can change the settings to use a different model or different parameters. And then in custom_instructions.py, you can change the system prompt to use the new settings (e.g. my_fast or pqa_settings).
To replicate our results for the Mars InSight mission from our paper named Building an intelligent data exploring assistant for geoscientists, you must use the system_prompt_InSight.py file as your system prompt. To do that, you need to change the import in app.py from from utils.system_prompt import sys_prompt to from utils.system_prompt_InSight import sys_prompt.
The project behavior is controlled by several environment variables in the .env file:
Secrets (must be in .env file, never commit to repo):
OPENAI_API_KEY: Your API key provided by OpenAIAUTH_USERNAME: Username for application login (default:admin)AUTH_PASSWORD: Password for application login (default:password123)
Configuration settings:
LOCAL_DEV: Set to1for local development mode; set to0for productionPQA_HOME: Path to store Paper-QA settings, typically/app/dataPAPER_DIRECTORY: Path to the papers directory, typically/app/data/papers
Authentication System Details:
- The application uses a simple username/password authentication system
- Login sessions are valid for 24 hours
- All API endpoints are protected and require authentication
- Sessions are stored in memory (will be lost on server restart)
- Important: Authentication provides access control but NOT user isolation - all authenticated users share the same data and sessions
- Dockerfile: Uses multi-stage builds to install dependencies in a virtual environment and then copies only the necessary runtime files.
- Volumes: Ensure persistence—
persistent_datafor production and local bind-mounts (such as./frontendto/app/frontend) for rapid development. - NGINX Container: Serves static files and acts as a reverse proxy on port 80. Its configuration is contained in
nginx.conf. This is only used for local development and is set to mimic production.
Contributions, issue reports, and feature requests are welcome! Please open an issue or a pull request with your changes.

Prototype (v0.1.0) https://doi.org/10.5281/zenodo.15605301
This project is licensed under the MIT License.