This project develops a robust Visual Question Answering (VQA) system by integrating the CLIP (Contrastive Language–Image Pre-training) model with a Retrieval-Augmented Generation (RAG) framework. The system performs semantic matching between textual queries and visual content while generating contextually rich, knowledge-enhanced responses.
By combining computer vision and natural language processing techniques, the model advances multimodal understanding to solve real-world problems effectively.
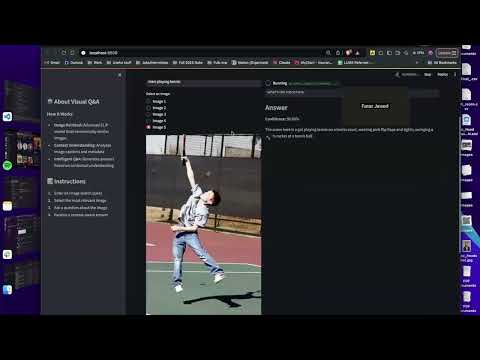
Watch the working demo of the app here:
📄 View the poster presentation here:
Click to open poster on Google Drive
- Image Encoding: Uses ResNet50 to extract visual features.
- Text Encoding: Uses DistilBERT to encode textual queries.
- Shared Embedding Space: Projects both image and text embeddings into a shared 256-dimensional space.
- Contrastive Learning: Optimizes cosine similarity to align correct image-text pairs and separate incorrect ones.
- External Knowledge Retrieval:
- Extracts keywords from CLIP-generated captions.
- Queries external knowledge bases (DBPedia) for enriched context.
- Stores and retrieves embeddings efficiently using the Chroma vector database.
- RAG Framework: Employs large language models (OpenAI's GPT) to synthesize retrieved knowledge with visual data into detailed, context-aware answers.
- Multimodal learning combining visual and textual data for enhanced understanding.
- Integration of external knowledge to enrich answer quality and relevance.
- Hyperparameter optimization to improve model performance and accuracy.
- Education: Enables interactive learning experiences through visual content-based Q&A.
- Healthcare: Provides contextual analysis of medical images to support diagnostics.
- Semantic Search: Enhances search relevance in e-commerce and other domains by leveraging combined text-image understanding.
This project showcases the potential of integrating multimodal AI technologies to bridge the gap between computer vision and natural language processing. It demonstrates how combining powerful embeddings, external knowledge retrieval, and advanced generation techniques can create sophisticated, knowledge-enriched VQA systems for real-world impact.