![]()
Tapestry
🌐 Open-Source Web Search Backend Framework via Plug-and-Play Configuration
- Overview
- Support
- Quick Start
- API Reference
- Client Tests
- Demo
- How do Tapestry work?
- Project Structures
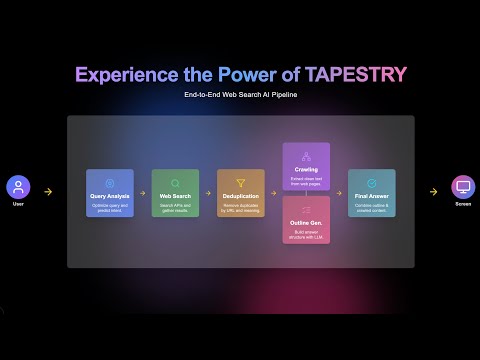
Tapestry is an open-source backend framework designed to build customizable AI web search pipelines. Tapestry allows developers to flexibly combine plug-and-play modules, including search engines, domain-specific crawling, LLMs, and algorithms for improving search performance (e.g., deduplication, query rewriting).

| Engine | API Key | Search | Youtube Search | News Search | Scholar Search | Shopping |
|---|---|---|---|---|---|---|
| Serper | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Serp | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Brave | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| DuckDuckGo | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ |
- OpenAI, Anthropic, Gemini
This guide provides instructions for running the Tapestry service using Docker or Kubernetes.
Before launching the service, you must configure your environment variables. All settings are managed through a .env file in the envs directory.
-
Copy the Example Configuration:
Create your environment file by copying the provided template.cp envs/example.env envs/.env
-
Edit the
.envFile:
Open the newly created.envfile and fill in the required values, such as your API keys and database credentials.- For a detailed explanation of each variable, refer to the guide at
envs/README.md. - Important: The
POSTGRES_HOSTvariable must be set correctly for your deployment environment:- For Docker:
POSTGRES_HOST=postgres - For Kubernetes:
POSTGRES_HOST=tapestry-postgres
- For Docker:
- For a detailed explanation of each variable, refer to the guide at
This is the recommended method for local development and testing.
-
Ensure your
.envfile is configured as described above, withPOSTGRES_HOST=postgres. -
Run the launch script:
The script handles directory setup and starts all services using Docker Compose.bash scripts/run.sh
The script uses the
.envfile in the project root by default. -
Accessing the Service: The API will be available at
http://localhost:9012. You can change the port via theAPP_PORTvariable in your.envfile.
For deployment in a Kubernetes cluster.
-
Ensure your
.envfile is configured as described above, withPOSTGRES_HOST=tapestry-postgres. Also, ensureLOG_DIRandPOSTGRES_DATA_DIRare absolute paths that exist on your Kubernetes nodes. -
Run the deployment script:
This script automates the entire deployment process.bash scripts/run_k8s.sh [K8S_IP] [SERVICE_PORT] [POSTGRES_PORT] [NODE_PORT]
Script Arguments:
K8S_IP: The IP address of your Kubernetes cluster (defaults to127.0.0.1).SERVICE_PORT: The internal port for the application service (defaults to9012).POSTGRES_PORT: The port for the PostgreSQL service (defaults to5432).NODE_PORT: The external port (NodePort) to access the service (defaults to30800).
Example:
bash scripts/run_k8s.sh 127.0.0.1 9012 5432 30800
-
Accessing the Service: The API will be available at
http://[K8S_IP]:[NODE_PORT](e.g.,http://127.0.0.1:30800).
POST /websearch
-
query|string| Required: The search query string. -
language|string| Optional, defaults to"en": Response language. ISO 639-1 two-letter language code (e.g., en, ko, ja). -
search_type|string| Optional, defaults to"auto":auto: The LLM automatically infers the search type from the query.general: Uses only indexed content from general search results for answering.news: Uses only indexed content from news search results for answering.scholar: Uses only indexed content from scholarly search results for answering. If the search engine does not support this, it falls back togeneralsearch.youtube: Extracts and uses only YouTube video links from video search results for answering. If the search engine does not support this, it falls back togeneralsearch.
-
persona_prompt|string| Optional, defaults toNone: Persona instructions for the LLM. -
custom_prompt|string| Optional, defaults toNone: Additional custom instructions to inject into the LLM. -
messages|array| Optional, defaults toNone: Previous conversation history. Must follow the format:[{"role": "user", "content": ""}, {"role": "assistant", "content": ""}, ...]. -
target_nuance|string| Optional, defaults to"Natural": Desired response nuance. -
use_youtube_transcript|bool| Optional, defaults toFalse: If YouTube results are included, use transcript information. -
top_k|int| Optional, defaults toNone: Use the topksearch results. -
stream|bool| Optional, defaults toTrue: Return the response as a streaming output.
The API returns a streaming JSON response with the following status types:
processing: Indicates the current processing step.streaming: Returns incremental answer tokens as they are generated (ifstream=true).complete: Final answer and metadata.
- Processing
{"status": "processing", "message": {"title": "Web search completed"}}- Streaming
{"status": "streaming", "delta": {"content": "token_text"}}- Complete
{
"status": "complete",
"message": {
"content": "<final_answer_string>",
"metadata": {
"queries": ["<query1>", "<query2>", ...],
"sub_titles": ["<subtitle1>", "<subtitle2>", ...]
},
"models": [
{
"model": {"model_name": "<model_name>", "model_vendor": "<model_vendor>", "model_type": "<model_type>"},
"usage": {"input_token_count": 0, "output_token_count": 0}
},
...
]
}
}You can test the API using the provided client script.
-
Run the client:
python tests/client.py --query "what is an ai search engine?" -
Configure the Endpoint:
Before running, opentests/client.pyand ensure theSERVER_URLvariable points to the correct endpoint for your environment:- Docker:
http://127.0.0.1:9012/websearch - Kubernetes:
http://127.0.0.1:30800/websearch(or yourK8S_IPandNODE_PORT).
- Docker:
Note:
GitHub does not support embedded YouTube videos in README files.
Please click the image below to watch the demo on YouTube.
Tapestry provides a Gradio-based Web UI for interactive web search and chatbot experience.
-
Local Run:
bash gradio/run_demo.sh
You can set the port and API address:
GRADIO_PORT=8888 API_URL=http://my-api:9000/websearch bash gradio/run_demo.sh
-
Docker Run:
bash gradio/run_docker_demo.sh
You can also set the port and API address:
GRADIO_PORT=8888 API_URL=http://my-api:9000/websearch bash gradio/run_docker_demo.sh
For more details, please refer to
gradio/README.md.
GET /health: Health check endpoint.POST /websearch: Main QA endpoint with a streaming response.
Tapestry/
├── main.py # Main FastAPI server
├── src/ # Core source code (models, search, db, utils, etc.)
├── gradio/ # Gradio Web UI
├── tests/ # Test clients & API guide
├── envs/ # Environment variable examples and docs
├── configs/ # Configuration files
├── k8s/ # Kubernetes manifests
├── scripts/ # Automation scripts (run.sh, run_k8s.sh)
├── benchmark/ # Benchmark scripts
├── misc/ # Miscellaneous (images, gifs)
├── requirements.txt # Python dependencies
├── Dockerfile # Docker build file
├── docker-compose.yaml # Docker Compose file
├── LICENSE # License
└── .gitignore # Git ignore rules