In this project I tried to to understand how to analyze network data and identify the variables associated with cyber attacks. It aims to improve cyber security by developing a machine learning and rule-based approach to detect cyber attacks. The approach involves analyzing network data to identify potential attacks by identifying correlations between various variables. By leveraging machine learning algorithms and rule-based approaches, this project helps to improve the accuracy and efficiency of cyber attack detection, thereby enhancing the security of digital networks and systems.
Key goal is to understand how attacks happen and what are the important indicators of attack. Specific objectives were:
- Understand how cyber attacks occur and identify important indicators of attacks.
- Implement a monitoring system for attack detection using both rule-based and machine learning approaches.
- Learn how to visualize variables in network data.
- Rule based system: These systems use a set of predefined rules to identify potential attacks based on known attack patterns. For example, a rule might flag an attack if the source to destination time to live (sttl) value is less than 10 and the count of states time to live (ct_state_ttl) value is greater than 100.
- Machine Learning algorithm: These algorithms are trained on a large dataset of network packets and can be used to identify anomalies in real-time network traffic that might indicate an attack. For example, a machine learning model might detect an attack if the destination to source transaction bytes (rate) value is greater than 10,000.
- Human Analysis: Human analysts can use their expertise to interpret the data and understand the context in which the attack is taking place. For example, they may understand that a particular system is undergoing maintenance and can disregard anomalies in the data that might otherwise indicate an attack.
I have used Jupyter Notebook environment and Python codes to run this project. To start with essential libraries were imported as follows:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_context('notebook')
sns.set_style('white')The data is collected by the University of New South Wales (Australia). That includes records of different types of cyber attacks. The dataset contains network packets captured in the Cyber Range Lab of UNSW Canberra. The data is provided in two sets of training and testing data. It was combined to create one set of large data.
## loading the data
training = pd.read_csv("https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMSkillsNetwork-GPXX0Q8REN/UNSW_NB15_training-set.csv")
testing = pd.read_csv("https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMSkillsNetwork-GPXX0Q8REN/UNSW_NB15_testing-set.csv")
print("training ",training.shape)
print("testing ",testing.shape)Here we see an output of the number of rows and columns for the training and testing tables:

Next is to check if all the columns are similar:
# checking if all the columns are similar
all(training.columns == testing.columns)Output is True
We will now create one dataframe by joining training and testing dataframe. We will drop the 'id' column for ease of further analysis:
# creating one-whole dataframe which contains all data and drop the 'id' column
df = pd.concat([training,testing]).drop('id',axis=1)
df = df.reset_index(drop=True)
# print one attack sample
df.head(2)We will see an sample output of the attacks where the column number has reduced to 44:

The dataframe also has a column which is Attack Category. We will check the unique values to understand the types of attack and use it for further analysis.
# creating one-whole dataframe which contains all data and drop the 'id' column
df = pd.concat([training,testing]).drop('id',axis=1)
df = df.reset_index(drop=True)
# print one attack sample
df.head(2)Finally, in this section, let's explore the different types of attacks:
# explore different types of attackes
print(df[df['label']==1]
['attack_cat']
.value_counts()
)
# plot the pie plot of attacks
df[df['label']==1]['attack_cat'].value_counts()\
.plot\
.pie(autopct='%1.1f%%',wedgeprops={'linewidth': 2, 'edgecolor': 'white', 'width': 0.50})Visualizing the output



Following types of attacks are classified in this dataframe:
Fuzzers: Attack that involves sending random data to a system to test its resilience and identify any vulnerabilities.Analysis: A type of attack that involves analyzing the system to identify its weaknesses and potential targets for exploitation.Backdoors: Attack that involves creating a hidden entry point into a system for later use by the attacker.DoS (Denial of Service): Attack that aims to disrupt the normal functioning of a system, making it unavailable to its users.Exploits: Attack that leverages a vulnerability in a system to gain unauthorized access or control.Generic: A catch-all category that includes a variety of different attack types that do not fit into the other categories.Reconnaissance: Attack that involves gathering information about a target system, such as its vulnerabilities and potential entry points, in preparation for a future attack.Shellcode: Attack that involves executing malicious code, typically in the form of shell scripts, on a target system.Worms: A type of malware that spreads itself automatically to other systems, often causing harm in the process.
These nine categories cover a wide range of attack types that can be used to exploit a system, and it is important to be aware of them to protect against potential security threats.
In the rule-based model, we are looking for higher recall rate because we are sensitive to alarm potential threats, and we can not afford to miss attacks (FALSE NEGATIVE). Recall (or True Positive Rate) is calculated by dividing the true positives (actual attacks) by anything that should have been predicted as positive (detected and non-detected attacks).
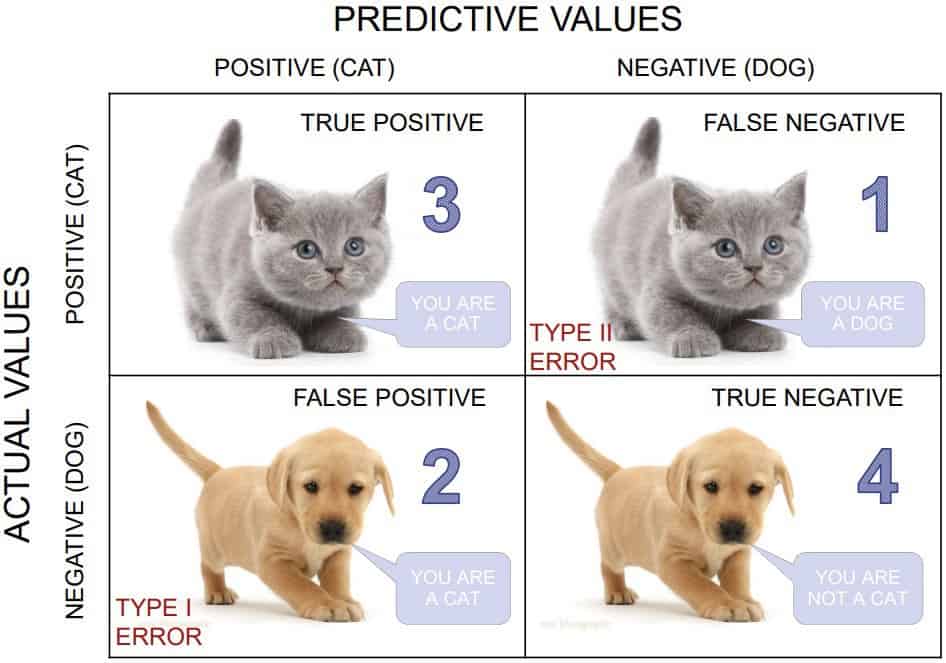 |
|---|
| Learn more about confusion matrix (and image credit): https://keytodatascience.com/confusion-matrix/ |
We will use a decision tree model to create a set of criteria for detecting cyber attacks in our rule-based system. The goal of this first layer of protection is to have a high recall rate, so we conduct a grid search to optimize the model toward maximizing recall.
# separating the target columns in the training and testing data
from sklearn.model_selection import train_test_split
# Split the data into variables and target variables
# let's exclude label columns
X = df.loc[:, ~df.columns.isin(['attack_cat', 'label'])]
y = df['label'].values
# Split the data into train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=11)
# Getting the list of variables
feature_names = list(X.columns)
# print the shape of train and test data
print("X_train shape: ", X_train.shape)
print("y_train shape: ", y_train.shape)
print("X_test shape: ", X_test.shape)
print("y_test shape: ", y_test.shape)
We will now define a parameter grid and work towards best paraters and best score
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
# Define the parameter grid
param_grid = {
'criterion': ['gini', 'entropy'],
'max_depth': [2, 4],
'min_samples_split': [2, 4],
'min_samples_leaf': [1, 2]
}
# Create a decision tree classifier
dt = DecisionTreeClassifier()
# Use GridSearchCV to search for the best parameters
grid_search = GridSearchCV(dt, param_grid, cv=5, scoring='recall')
grid_search.fit(X_train, y_train)
# Print the best parameters and best score
print("Best parameters:", grid_search.best_params_)
print("Best recall score:", grid_search.best_score_)Output

Using the parameters above, adjust the decision tree for high recall rate.
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
clf=grid_search.best_estimator_
#same as
#clf = DecisionTreeClassifier(max_depth=2, min_samples_leaf=1, min_samples_split=2, criterion= 'entropy')
#clf.fit(X_train, y_train)
# Make predictions on the test data
y_pred = clf.predict(X_test)
# Calculate the mean absolute error of the model
recall = recall_score(y_test, y_pred)
print("Recall: ", recall)Output

One of the strengths of a decision tree is to present the sets of rules than can be utilized for rule-based systems.
# plot the tree
from sklearn.tree import export_text
import dtreeviz
print(":::::::> The RULES FOR HIGH RECALL RATE <::::::: \n" ,export_text(clf,feature_names=feature_names))Finally, here we visualize the rules.

Random Forest is a good choice for cyber attack detection due to its high accuracy in classifying complex data patterns. The ability to interpret the results of Random Forest models also makes it easier to validate and understand the decisions it makes, leading to more effective and efficient cyber security measures.
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score
# Create a Random Forest model
rf = RandomForestClassifier(random_state=123)
# Train the model on the training data
rf.fit(X_train, y_train)
# Make predictions on the test data
y_pred = rf.predict(X_test_2)
# Calculate the mean absolute error of the model
acc = accuracy_score(y_test_2, y_pred)
rec = recall_score(y_test_2, y_pred)
per = precision_score(y_test_2, y_pred)
print("Recall: ", rec)
print("Percision: ", per)
print("Accuracy: ", acc)As we can see, the random forest algorithm showed strong performance in cyber attack detection.

To gain better insight into the performance of our prediction model, let's plot a confusion matrix. It is important to note that the majority of our data contains actual attack information, as we filtered out some portion of non-threatening traffic in the previous step.
# plot confusion matrix
cross = pd.crosstab(pd.Series(y_test_2, name='Actual'), pd.Series(y_pred, name='Predicted'))
plt.figure(figsize=(5, 5))
sns.heatmap(cross, annot=True,fmt='d', cmap="YlGnBu")
plt.show()
This allowed us to have a visual representation of the tree and helped to better understanding of how the model is making decisions to detect cyber attacks. The rules presented in the tree can also be used as a reference for developing a rule-based system or for fine-tuning the model for better results. The output also highlighted the most important factors considered by the model for attack detection, which can be useful for further analysis and optimization.