The method uncovers hidden themes as semantic structures that are frequently discussed in the documents to explore unfamiliar domains. It may also be used to identify features as topics for subsequent tasks, e.g., applying the method on the hotel reviews corpus may result in topics representing food quality, menu, table service, pricing, etc. It calculates the co-occurrence frequencies among words to organize topics as ordered collections of words and documents as ordered collections of topics. As an unsupervised approach, the topics are unlabeled and rather represented by their highest probability words. The method reads input as a document per line and outputs two files: document-topic distribution and topic-word distribution.
To explore the dynamics of political poll reviews for gaining nuanced insights into voter interests.
The input can be any text to explore. For demonstration purposes, we use BBC news article headlines as sample documents. Below are 10 example headlines taken from the dataset, which can be found in the file data/input.csv
| Headlines |
|---|
| India calls for fair trade rules |
| Sluggish economy hits German jobs |
| Indonesians face fuel price rise |
| Court rejects $280bn tobacco case |
| Dollar gains on Greenspan speech |
| Mixed signals from French economy |
| Ask Jeeves tips online ad revival |
| Rank 'set to sell off film unit' |
| US trade gap hits record in 2004 |
| India widens access to telecoms |
The latent topics identified are represented by the most significant words and their probabilities. It is similar to clustering in the sense that the words are grouped as topics and labeled unintuitively as topic 0, topic 1, etc. However, unlike clustering, the words have probabilities of relevance to the topic. Using these probabilities, only the top few words (10 in config.json) are used to represent a topic i.e., topic-word distribution. For the three topics:
| Topic Name | Words and Probabilities |
|---|---|
| Topic 0 | ('deal', 0.039125056962437336)('profit', 0.03261506412342946)('profits', 0.026105071284421584)('Japanese', 0.019595078445413708)('takeover', 0.01308508560640583)('lifts', 0.01308508560640583)("India's", 0.01308508560640583)('high', 0.01308508560640583)('Parmalat', 0.01308508560640583)('China', 0.01308508560640583) |
| Topic 1 | ('economy', 0.04184945338068379)('hits', 0.03488614998955504)('fuel', 0.03488614998955504)('Yukos', 0.02792284659842629)('growth', 0.02792284659842629)('Japan', 0.02792284659842629)('German', 0.020959543207297537)('$280bn', 0.013996239816168788)('French', 0.013996239816168788)('prices', 0.013996239816168788) |
| Topic 2 | ('jobs', 0.024660229998155092)('firm', 0.024660229998155092)('gets', 0.024660229998155092)('India', 0.018510546706844596)('sales', 0.018510546706844596)('new', 0.018510546706844596)('oil', 0.018510546706844596)('BMW', 0.018510546706844596)('trade', 0.012360863415534098)('rise', 0.012360863415534098) |
The complete distribution is written to data/output-data/topic-word-distribution.txt
Topic Distribution Per Document: Each document is assigned probabilities of representing a topic based on the topic association of its words. These probabilities indicate the extent to which each document relates to specific topics. For example, document 0 can be 45% topic 0, 45% topic 1, and 10% topic 2.
In case a reader is interested in only reading more about topic 0, he/she may only focus on the documents where topic 0 is the major topic.
| Document | Topic 0 | Topic 1 | Topic 2 |
|---|---|---|---|
| Document 0 | 0.125 | 0.5 | 0.375 |
| Document 1 | 0.375 | 0.25 | 0.375 |
| Document 2 | 0.125 | 0.75 | 0.125 |
| Document 3 | 0.375 | 0.25 | 0.375 |
| Document 4 | 0.7142857142857143 | 0.14285714285714285 | 0.14285714285714285 |
| Document 5 | 0.42857142857142855 | 0.2857142857142857 | 0.2857142857142857 |
| Document 6 | 0.125 | 0.375 | 0.5 |
| Document 7 | 0.25 | 0.0.5 | 0.25 |
| Document 8 | 0.375 | 0.375 | 0.25 |
| Document 9 | 0.14285714285714285 | 0.14285714285714285 | 0.7142857142857143 |
| ... |
Written in file data/output-data/document-topic-distribution.txt
The method runs on a small virtual machine provided by a cloud computing company (2 x86 CPU core, 4 GB RAM, 40GB HDD).
It is the vanilla implementation of the Latent Dirichlet Allocation technique built from scratch; therefore, only basic libraries, i.e., numpy, pandas, random, and string, are needed to read data and generate random numbers.
- Update config.json to read method configurations in JSON format and update as desired.
- Setup the environment using requirements.txt through command
pip install -r requirements.txt - Put your data in data/input.csv
- Execute the notebook LDA-collapsed-gibbs-sampling.ipynb to get results
- Put your data in data/input.csv
- Execute the first notebook prepare-data.ipynb to transform the data into integer encoding
- Execute the main notebook `LDA-collapsed-gibbs-sampling.ipynb to get results
This method represents the Latent Dirichlet Allocation (LDA) topic modeling approach. It uses collapsed Gibbs sampling (LDA with collapsed Gibbs sampling) as the inference technique, which is an efficient extension of Gibbs sampling. The inference technique decides the most suitable topic for the sampled word, given the current state of the model, where the state of the model is determined by its document-topic distribution (having probabilities of each topic in each document) and topic-word distribution (having probabilities of each word in each topic). When a word switches its topic, i.e., its most suitable topic in the current state is different from its present topic (assigned in the previous iteration), it results in changing the state of the model. In each iteration, the inference technique samples each word to estimate its most suitable topic given the current state of the model. At the end of the iteration, the document-topic and topic-word probabilities are recomputed, and the model's state is updated.
The model starts with random initialization, i.e., the words are assigned to topics at random to help generate the initial probabilities for representing the initial state of the model. In the initial iterations the word switch their topics more rigorously, which reduces in the subsequent iterations as more and more words settle in their respective topics. Using the Markov chain Monti Carlo (MCMC) approach, the next state of the model is determined from the current state of the model, converging on a stable distribution. Allowing collapsed Gibbs sampling with enough iterations (in a few thousand), the words are expected to settle down in their respective topics. Although starting from any random state, the model converges to similar probability distributions; however, a better initial state helps to converge in fewer iterations. As an unsupervised method, the topics are not labeled but rather represented by their highest probability (top presentable) words. Each topic is an ordered list of words, where the words are organized by their probabilities with the topic (calculated based on the co-occurrence frequency of the word with all the other words in the topic) in decreasing order.
The method has two hyperparameters, i.e.,
Topic modeling is also a soft clustering approach (derived from the concept of soft sets in mathematics), as all words belong to all topics and all topics belong to all documents with varying probabilities. However, for the sake of clarity, only higher probabilities are considered. Thus, in general, words having a higher probability for a topic have lower probabilities for all other topics, except for polysemous words. They can be among the highest probability words for multiple topics, where each occurrence is surrounded by its contextually correlated words.
Topic models are generally represented by a plate-notation diagram as shown below source. The rectangles (also called plates in the diagram) represent loops, while the circles represent variables. The
and
Where, w is the sampled word from d^{th} document, whose probability is computed for topic t in
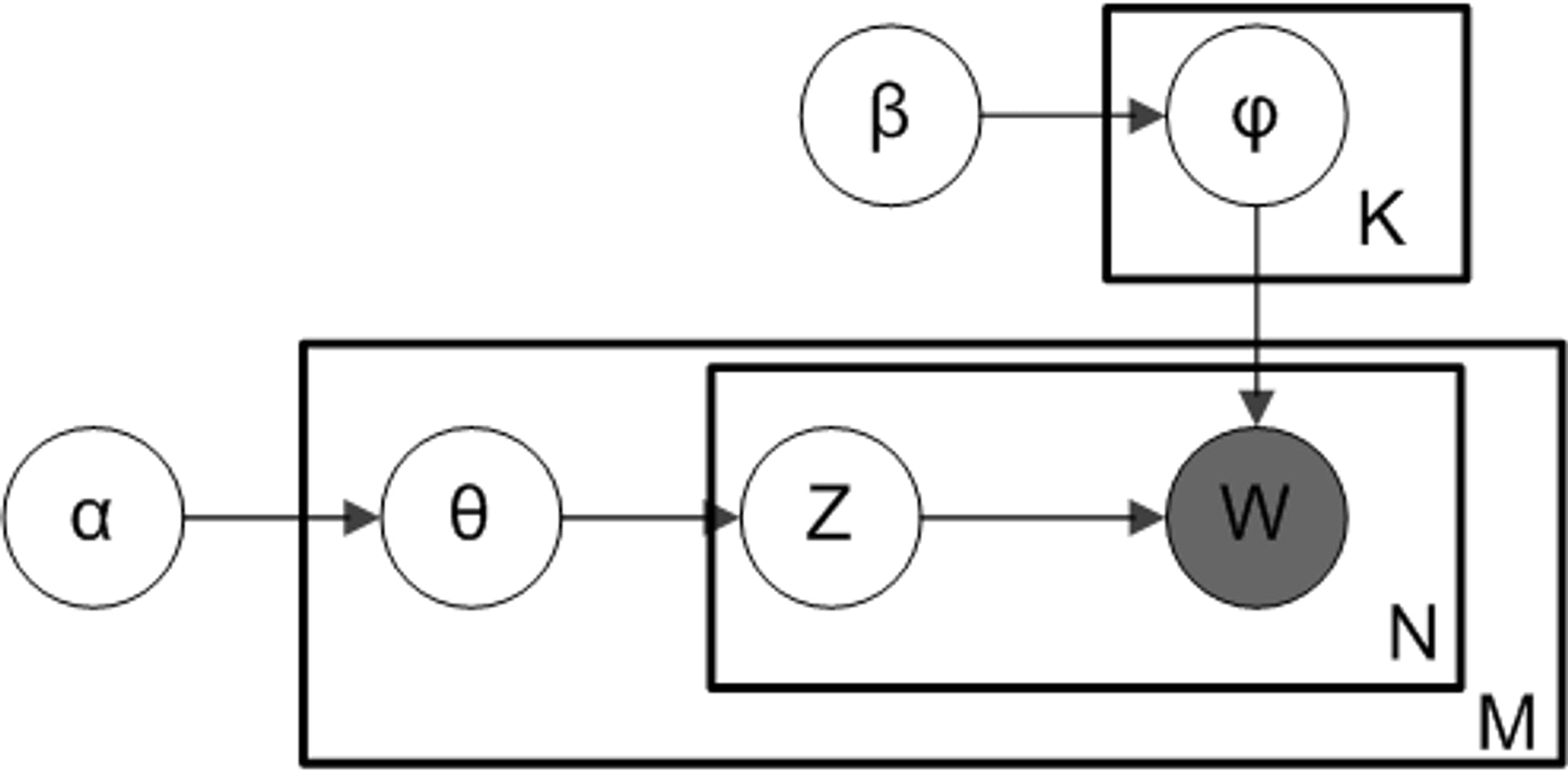
The Vanilla implementation offers higher transparency and thus more control over the internal decisions of the method.
M. Taimoor Khan (taimoor.khan@gesis.org)