This work has done as the part of project in Naver BoostCamp AI Tech 3rd. This project aims to preprocess, annotate, validate the raw dataset collected from korean wiki. Herein, we provide the raw data, annotated data via huggingface datasets library. Since only about two weeks are given to complete the overall process, the result may seem somehow sloppy. However, we provide English version short technical paper for those who consider to construct natural langue dataset but have no idead how to proceed. Eventhough our work primarily is about relation extraction task and some provided materials such as guidelines are written in Korean, we believe our trial and errors can help people avoid same troubles we have faced.
- you need to install
datasetsbeforehand :pip install datasets
from datasets import load_dataset
dataset = load_dataset("kimcando/KOR-RE-natures-and-environments")>>> dataset['train'][0]
{'Unnamed: 0': 0, 'sentence': '흙 또는 토양(土壤)은 암석이나 동식물의 유해가 오랜 기간 침식과 풍화를 거쳐 생성된 땅을 구성하는 물질이다.',
'subject_entity': "{'word': '흙', 'start_idx': 0, 'end_idx': 0, 'type': 'RES'}",
'object_entity': "{'word': '토양', 'start_idx': 5, 'end_idx': 6, 'type': 'RES'}",
'label': 'res:alter_name',
'file_name': "('흙.txt', 'aJsku6MJ1m_p5ApaGJwqnBtchlVq-_.txt.ann.json')", 'sent_idx': 0, 'id': 0}
- You can ignore Unnamed, file_name, sent_idx, id attributes.
주제 : 자연환경
네이버 부스트캠프 AI Tech 3기 NLP 3조(삼각김박임)
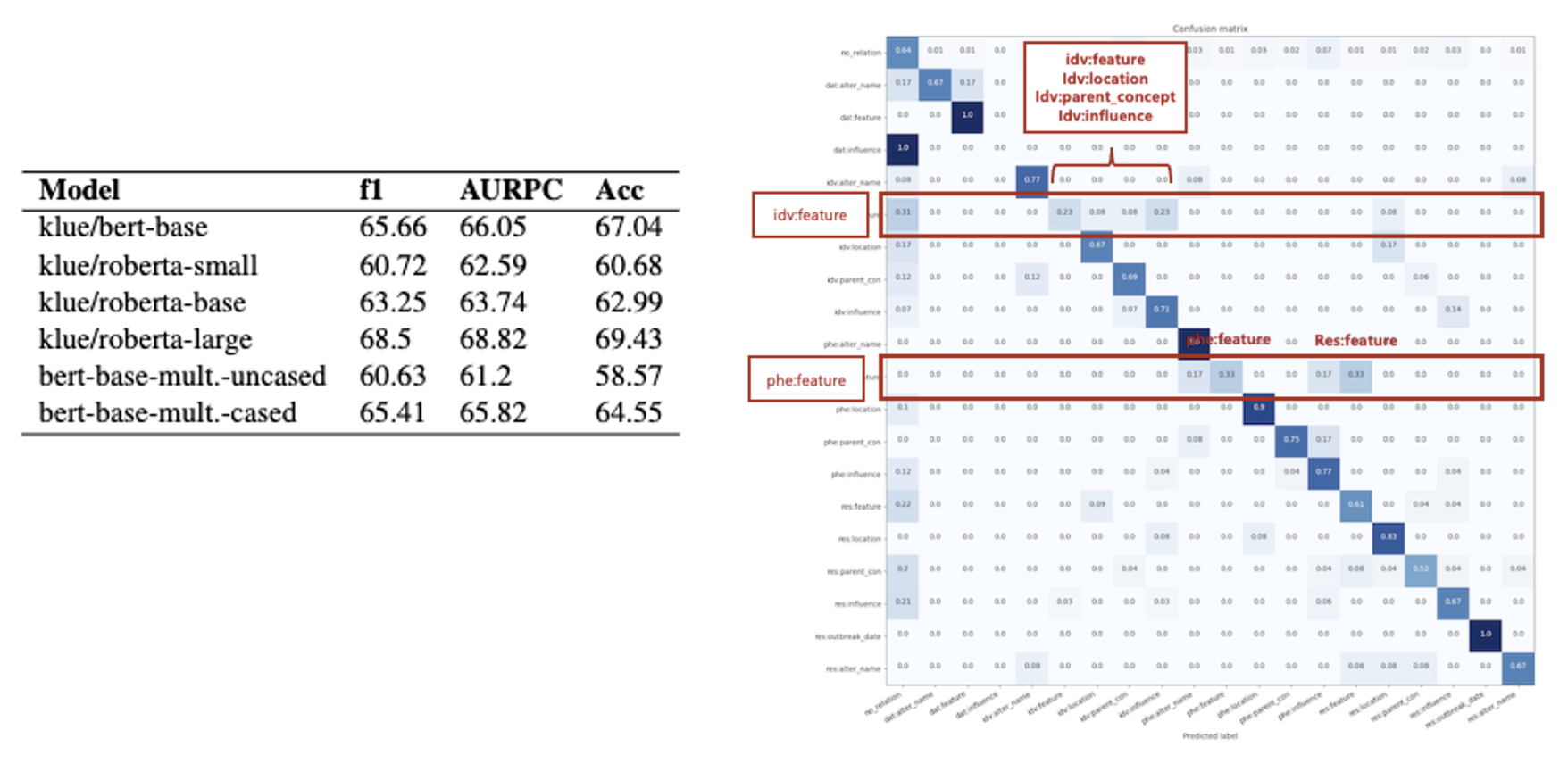
본 프로젝트는 관계 추출 테스크에 적합한 데이터셋을 제작하는 것입니다. 더 나아가 데이터셋 제작에 활용될 수 있는 relation map과 가이드라인도 함께 작성하는 것을 목표로 합니다. 각 팀은 한국어 위키피디아에서 수집된 주제별 원시 데이터에서 <주어, 관계, 목적어> Triplet 쌍을 라벨링합니다. 이를 위해 데이터셋 주제에 적합한 entity와 relation을 정의하고 라벨링한 후, 팀 내부 교차 검증을 통해 Fleiss’ Kappa를 기준으로 작업자간 일치도(IAA, Inter-Annotator Agreement)를 측정합니다. 저희 팀의 주제는 🌳자연환경🌳으로 총 20개의 ‘주어:관계’를 설정했으며, 총 2,163개의 triplet을 생성하였습니다. 본 데이터는 100개의 triplet에 대해 교차 검증이 수행되었고 Fleiss’ Kappa score 0.546로 Moderate agreement 정도의 신뢰도를 가지며, 본 데이터를 klue/roberta-large로 학습한 결과 f1 score 68.50의 베이스라인 성능을 얻었습니다.
| Wrap-up Report | Relation map | Guideline |
|---|---|---|
| link | link |
| 김상렬 | 김소연 | 김은기 | 박세연 | 임수정 |
|---|---|---|---|---|
 |
 |
 |
 |
|
| SangRyul | kimcando | xuio-0528 | maylilyo | sujeongim |
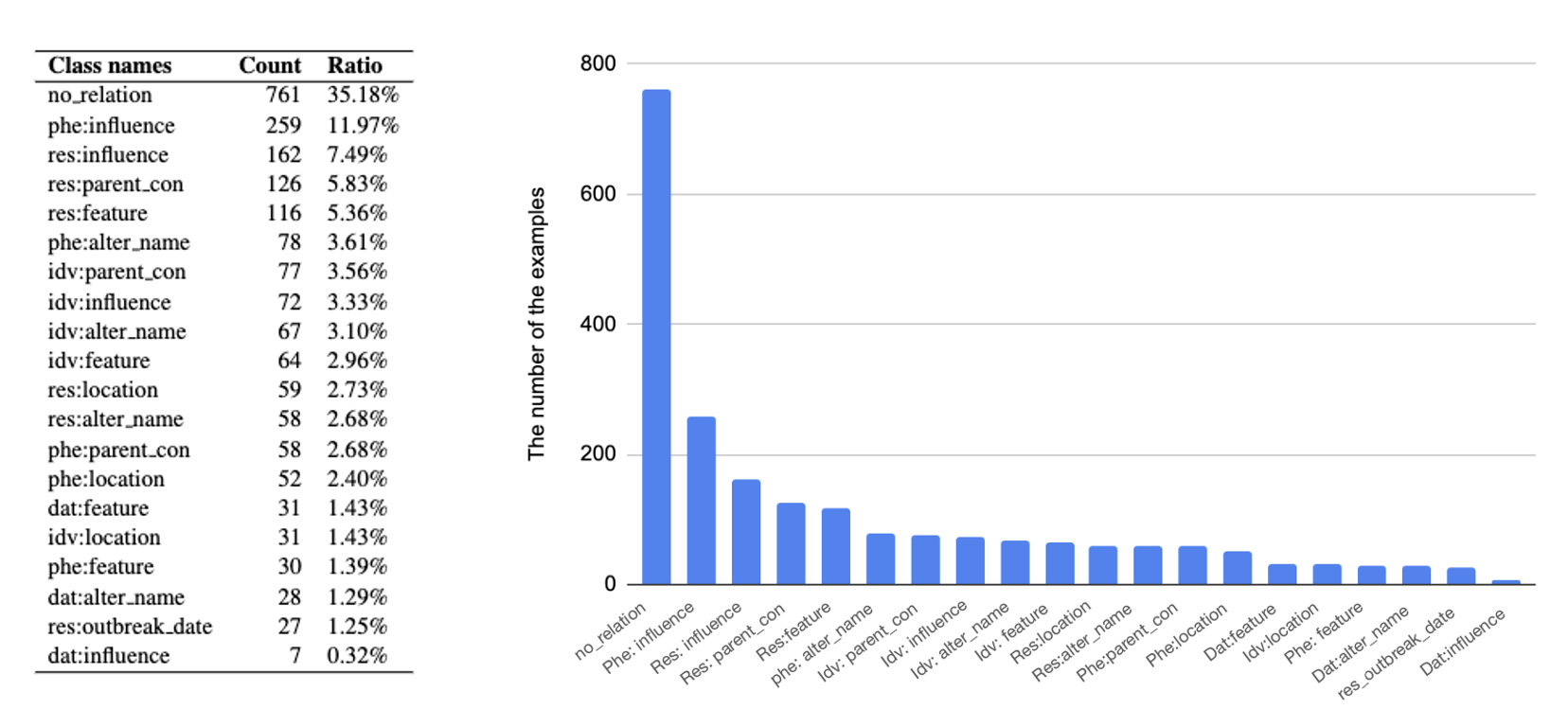
- 총 데이터 개수 : 2,163개
- ‘주어:관계’ : 20개
- Field 설명: huggingface Dataset card 참고
대멸종이 일어나면서 백악기와 중생대의 막을 내렸다. -> 백악기:subject & 대멸종: object & 관계:
DAT:influence연약권에서는 지진파의 속도가 약간 감소하기 때문에 저속도층이라고 부른다. -> 저속도층: subject &연약권: object & 관계:RES:alternate_name
- 주어, 목적어 모두 가능(DAT, IDV, PHE, RES)
- 목적어만 가능(LOC, POH, NOH)
| Entities | Tag | 설명 |
|---|---|---|
| Date | DAT | 날짜, 시기와 연관된 특정 시기와 기간을 나타내며, DAT(Date)로 표기합니다. |
| Individual | IDV | 어떤 생물종/생물군의 이름을 나타냅니다. 여기서 생물의 정의는 생존할 수 있는 최소단위를 의미합니다. IDV(Individual)로 표기합니다. |
| Phenominon | PHE | 어떤 현상을 지칭하는 이름을 나타냅니다. 여기서 현상은 자연환경/자원(RES)이나 개체(IDV) 등에서 발생하는 특정한 변화(status)를 지칭합니다. PHE(Phenominon)로 표기합니다. |
| Resource | RES | 모든 자연환경과, 자연에서부터 산출된 자원을 나타냅니다. RES(Resource)로 표기합니다. |
| Location | LOC | 장소, 서식지와 연관된 모든 data를 나타내며, LOC(Location)로 표기합니다. |
| POH | POH | 위에 해당하지 않는 모든 명사를 나타냅니다. POH로 표기합니다. |
| NOH | NOH | 위에 해당하지 않는 모든 수사를 나타냅니다. 주로 특징(feature)를 나타내기 위해 사용합니다. NOH로 표기합니다. |
| Relations | Description |
|---|---|
| feature | Object는 Subject의 특징 |
| location | Object는 Subject의 위치 |
| parent_concept | Object는 Subject의 상위 개념 |
| influence | Object는 Subject에 영향을 미침 |
| outbreak_date | Object는 Subject의 발생(발견)날짜 |
| alternate_name | Object는 Subject의 다른 명칭 |
| no_relation | - |
- Fleiss Kappa score: 0.546 (Moderate agreement)
| # of raters | # of subjects | # of categories | PA | PE |
|---|---|---|---|---|
| 5 | 100 | 20 | 0.5800 | 0.0739 |
- 전체 2,163개의 데이터셋에 대해
sklearn의train_test_split()으로 stratify하게 train:val=0.8:0.2로 분할해서 성능 측정
| Member | Role |
|---|---|
| 김상렬 | Tagtog 관리, annotation |
| 김소연 | 프로젝트 리드, Wrap-up report, technical paper 작성, 데이터 post processing, 크로스 체크, 모델 파인튜닝, annotation |
| 김은기 | 가이드라인 작성, annotation |
| 박세연 | relation map 작성, annotation |
| 임수정 | IAA 계산, annotation |
자연환경 데이터셋은 CC BY-SA 3.0 라이선스 하에 공개되어 있습니다.
