![]()
PercGAN: A computationally inexpensive approach to high fidelity stereo audio sample generation.
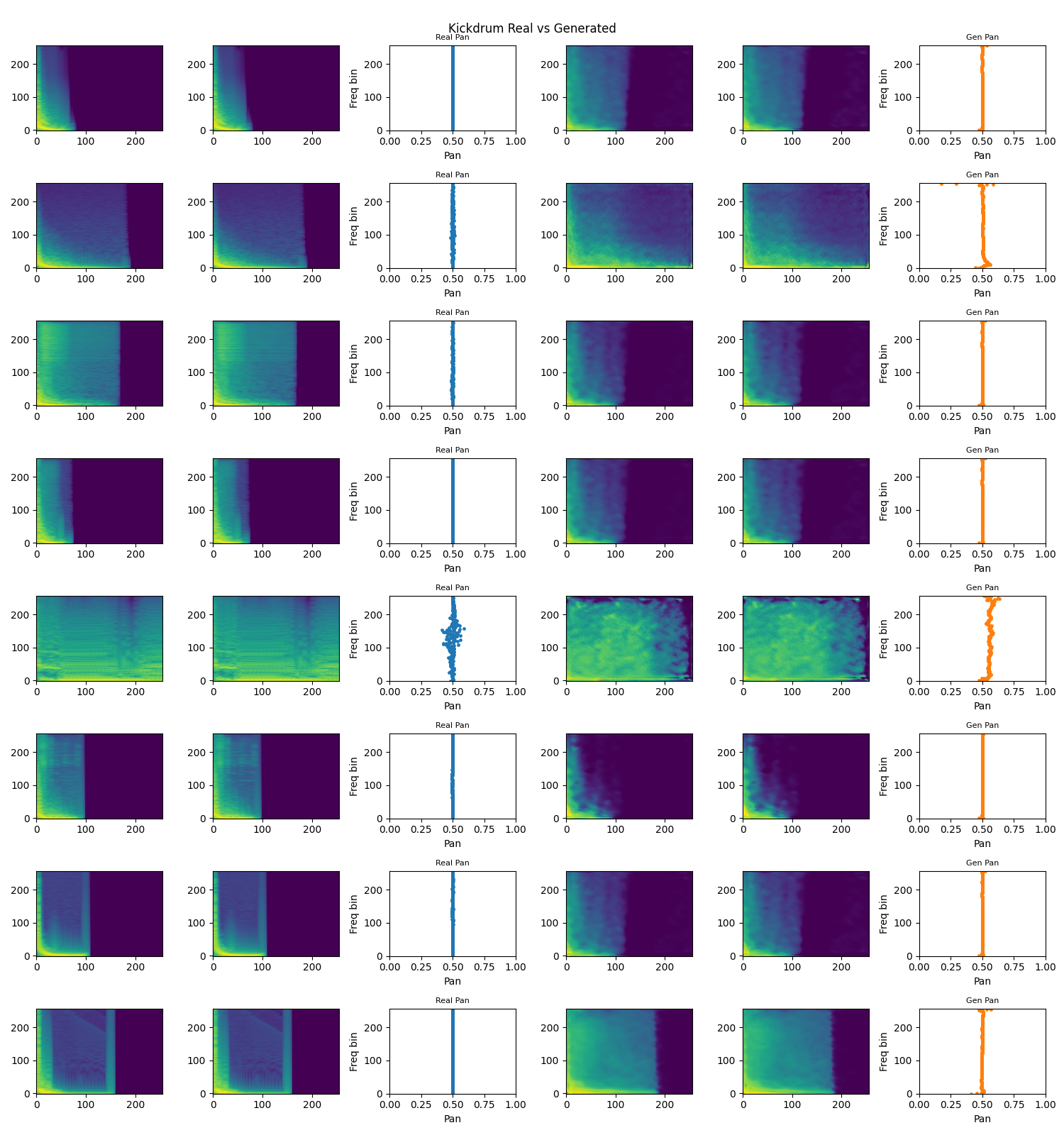
Kick drum generation model trained on curated kick drum samples.
Kick vs. Generated Comparison:
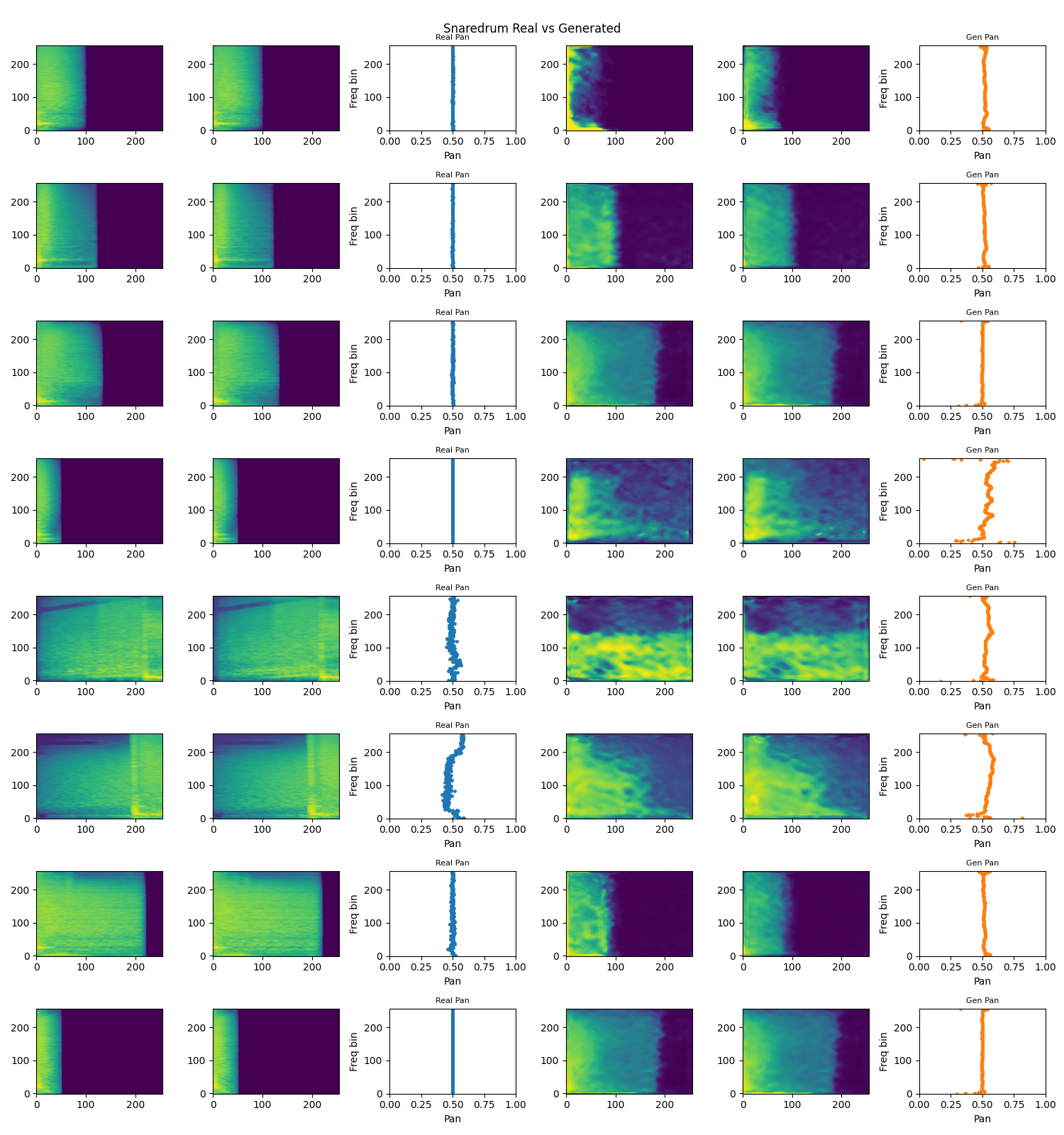
Snare drum generation model, focused on producing punchy, tight snare sounds.
Snare vs. Generated Comparison:
- Optional but highly recommended: Set up a Python virtual environment.
- Audio loader package
librosarequires an outdated version of Numpy
- Audio loader package
- Install requirements by running
pip3 install -r requirements.txt
Use the generation script with command line arguments:
# Generate 2 kick drum samples with default output path
python src/generate.py --type kick --count 2
# Generate 5 snare samples with custom output path
python src/generate.py --type snare --count 5 --output_path my_samplesParameters:
--type: Type of audio to generate (kickorsnare)--count: Number of samples to generate (integer value)--output_path: Directory to save generated audio files (default: "outputs")
PercGAN combines these audio generation techniques:
- Mel-Spectrogram Representation: For efficient learning of frequency patterns
- Progressive Growing: Training on increasingly higher resolution spectrograms
- Style-Based Generation: Using StyleGAN for better style control
- Multi-Scale Spectral Losses: Specialized frequency, decay, and coherence losses
- Griffin-Lim Reconstruction: Converting spectrograms back to audio
To train on your own audio samples:
- Collect one-shot audio samples (<1.5 seconds each)
- Update the model parameters in
src/utils/model_params.json - Encode your samples with
src/data_processing/encode_audio_data.py - Train with
src/stereo_sample_gan.py - Generate new samples with the unified generation script
This project is licensed under the MIT License - see the LICENSE file for details.