

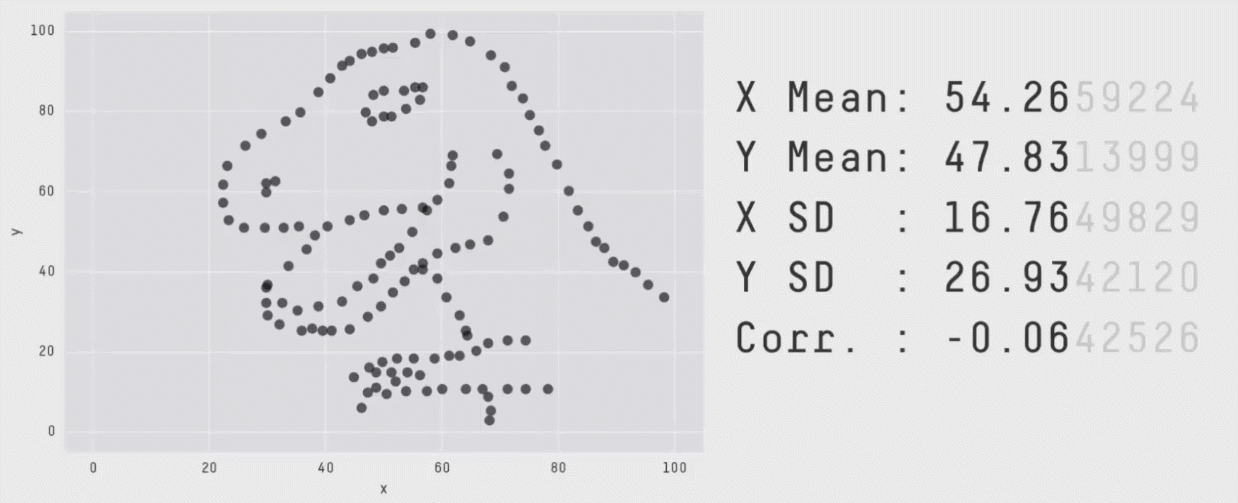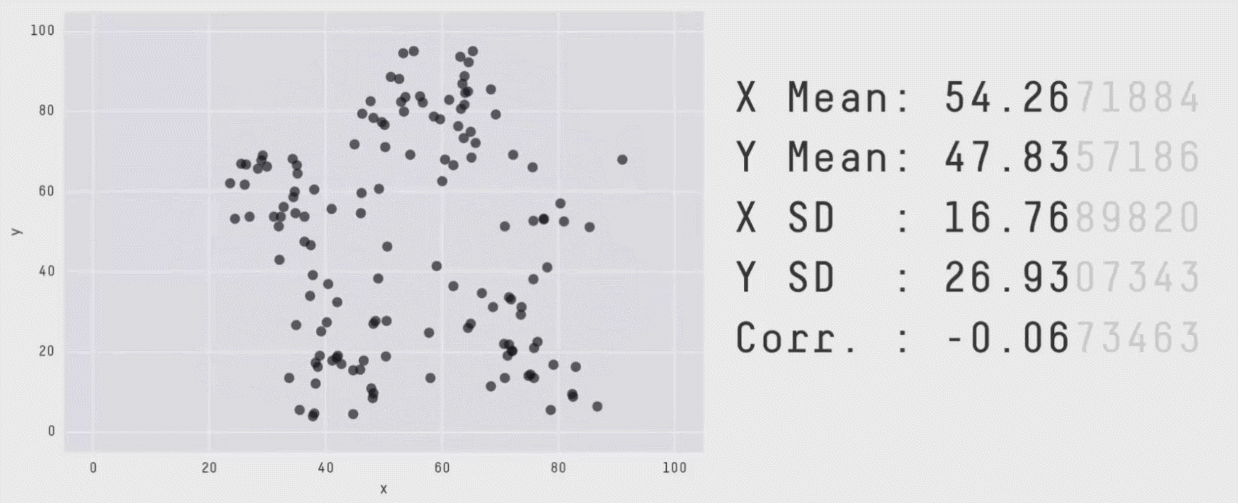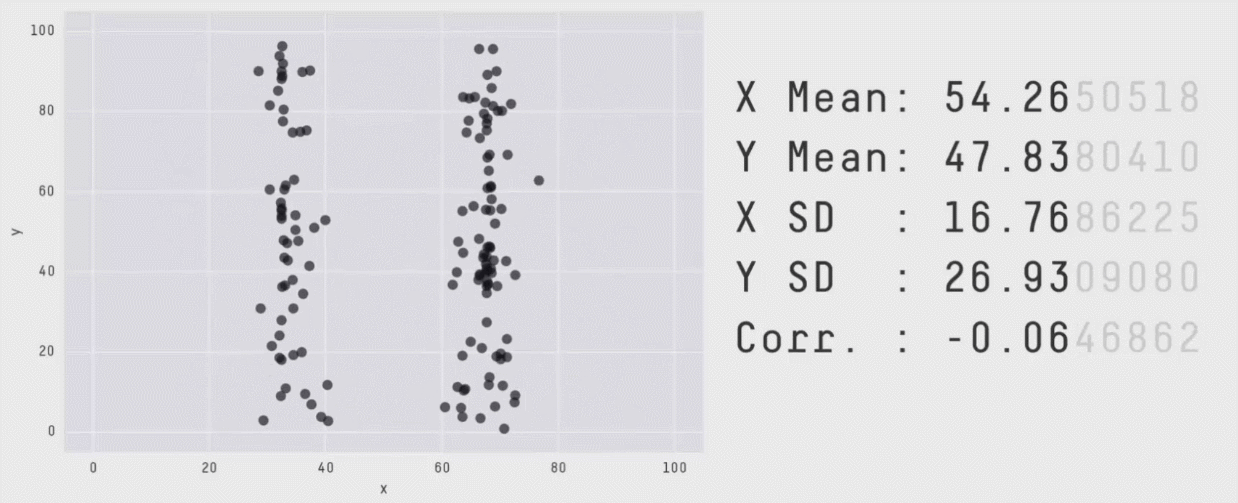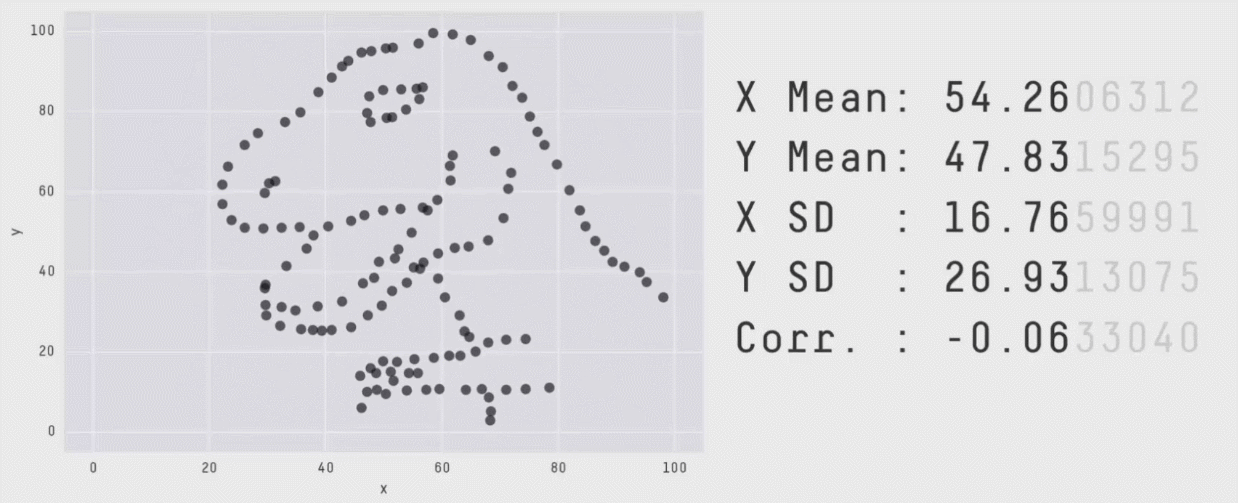
This package wraps the awesome Datasaurus Dozen datasets. The Datasaurus
Dozen show us why visualisation is important – summary statistics can be
the same but distributions can be very different. In short, this package
gives a fun alternative to Anscombe’s
Quartet, available
in R as anscombe.
The original Datasaurus was created by Alberto Cairo in this great blog post.
The other Dozen were generated using simulated annealing and the process is described in the paper Same Stats, Different Graphs: Generating Datasets with Varied Appearance and Identical Statistics through Simulated Annealing by Justin Matejka and George Fitzmaurice.
In the paper, Justin and George simulate a variety of datasets that the same summary statistics to the Datasaurus but have very different distributions.
The latest stable version (0.1.2) is available on CRAN
install.packages("datasauRus")You can get the latest development version from GitHub, so use
devtools to install the package
devtools::install_github("stephlocke/datasauRus")You can use the package to produce Anscombe plots and more.
library(ggplot2)
library(datasauRus)
ggplot(datasaurus_dozen, aes(x=x, y=y, colour=dataset))+
geom_point()+
theme_void()+
theme(legend.position = "none")+
facet_wrap(~dataset, ncol=3)
library(devtools)
test()
#> Loading datasauRus
#> Loading required package: testthat
#>
#> Attaching package: 'testthat'
#> The following object is masked from 'package:devtools':
#>
#> setup
#> Testing datasauRus
#> v | OK F W S | Context
#>
/ | 0 | datasets
- | 1 | datasets
\ | 10 | datasets
v | 22 | datasets [0.4 s]
#>
/ | 0 | Raw files
v | 1 | Raw files
#>
#> == Results =======================================================================
#> Duration: 1.2 s
#>
#> OK: 23
#> Failed: 0
#> Warnings: 0
#> Skipped: 0Anyone getting involved in this package agrees to our Code of Conduct. If someone is breaking the Will Wheaton rule aka Don’t be a dick, or breaking the Code of Conduct, please let me know at steph@itsalocke.com
When you file a bug report, please spend some time making it easy for us to follow and reproduce. The more time you spend on making the bug report coherent, the more time we can dedicate to investigate the bug as opposed to the bug report.
Got an idea for how we can improve the package? Awesome stuff!
Please raise it with some succinct information on expected behaviour of the enhancement and why you think it’ll improve the package.
We really want people to contribute to the package. A great way to start doing this is to look at the help wanted issues and/or contribute an example.
Examples for this package are done in base R or with ggplot2 as an optional example, using the structure:
if(require(ggplot2)){
#ggplot2 code here
}As this is a data package, most of the documentation is sitting in one
file (R/Datasaurus-package.R) so we keep the examples in a separate
directory (inst/examples).
- If there isn’t a file for the dataset you want to write an example
for, you can make one by just calling it
datasetname.R. To reference an example file, add the line@example inst/datasetname.Rin the relevant documentation section ofR/Datasaurus-package.R.
We’re relatively loose on coding conventions.
- Datasets are lower-case with underscores between words
- R code should be formatted with the “Reformat code” option in RStudio
- There are no standards for base R plots
- My preferred ggplot2 themes are
theme_minimalwhere axes labels matter andtheme_voidwhen they do not but I’m OK with the default ggplot2 theming if you want to avoid writing longer ggplot2 code