{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Frameworks, Tools and libraries
- Visualisation
- Snippets
- Books
- Papers
- Datasets
- Infographic
- Cheat Sheets
- Interview Questions
- Notebooks
- GitHub Repos
- Podcasts
- Communities
- Apache Hadoop
- Apache Spark
- Bokeh
- D3
- Flink
- ggplot
- Jupyter Docker Images
- Jupyter
- Kaggle
- Matplotlib
- Numpy
- Pandas Profiling
- Pandas
- Plotly Python Graphing Library
- r-project
- Scikit-learn
- SciPy
- Seaborn
docker run --rm \
-v ~:/home/jovyan/work \
-p 8888:8888 \
-p 4040:4040 \
-p 4041:4041 \
jupyter/pyspark-notebookimport pyspark
from pyspark.sql import SparkSession
#spark context
sc = pyspark.SparkContext('local[*]')
#spark session
spark = SparkSession.builder.appName('App name').getOrCreate()
# do something to prove it works
rdd = sc.parallelize(range(1000))
rdd.takeSample(False, 5)!pip install py_d3 -q%load_ext py_d3%%d3
<div id="my_dataviz"></div>
<script>
//your code here
</script>- Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing
- MapReduce: Simplified Data Processing on Large Clusters
- The PageRank Citation Ranking: Bringing Order to the Web
- MapReduce: Simplified Data Processing on Large Clusters
- The Google File System
- Amazon’s Dynamo
- Bigtable: A Distributed Storage System for Structured Data
- A Few Useful Things to Know about Machine Learning
- Random Forests
- A Relational Model of Data for Large Shared Data Banks
- Map-Reduce for Machine Learning on Multicore
- Pasting Small Votes for Classification in Large Databases and On-Line
- Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank
- Spanner: Google’s Globally-Distributed Database
- Megastore: Providing Scalable, Highly Available Storage for Interactive Services
- F1: A Distributed SQL Database That Scales
- APACHE DRILL: Interactive Ad-Hoc Analysis at Scale
- A New Approach to Linear Filtering and Prediction Problems
- Top 10 algorithms on Data mining
| Preview | Description |
|---|---|
 |
A visual guide to Becoming a Data Scientist in 8 Steps by DataCamp (img) |
 |
Mindmap on required skills (img) |
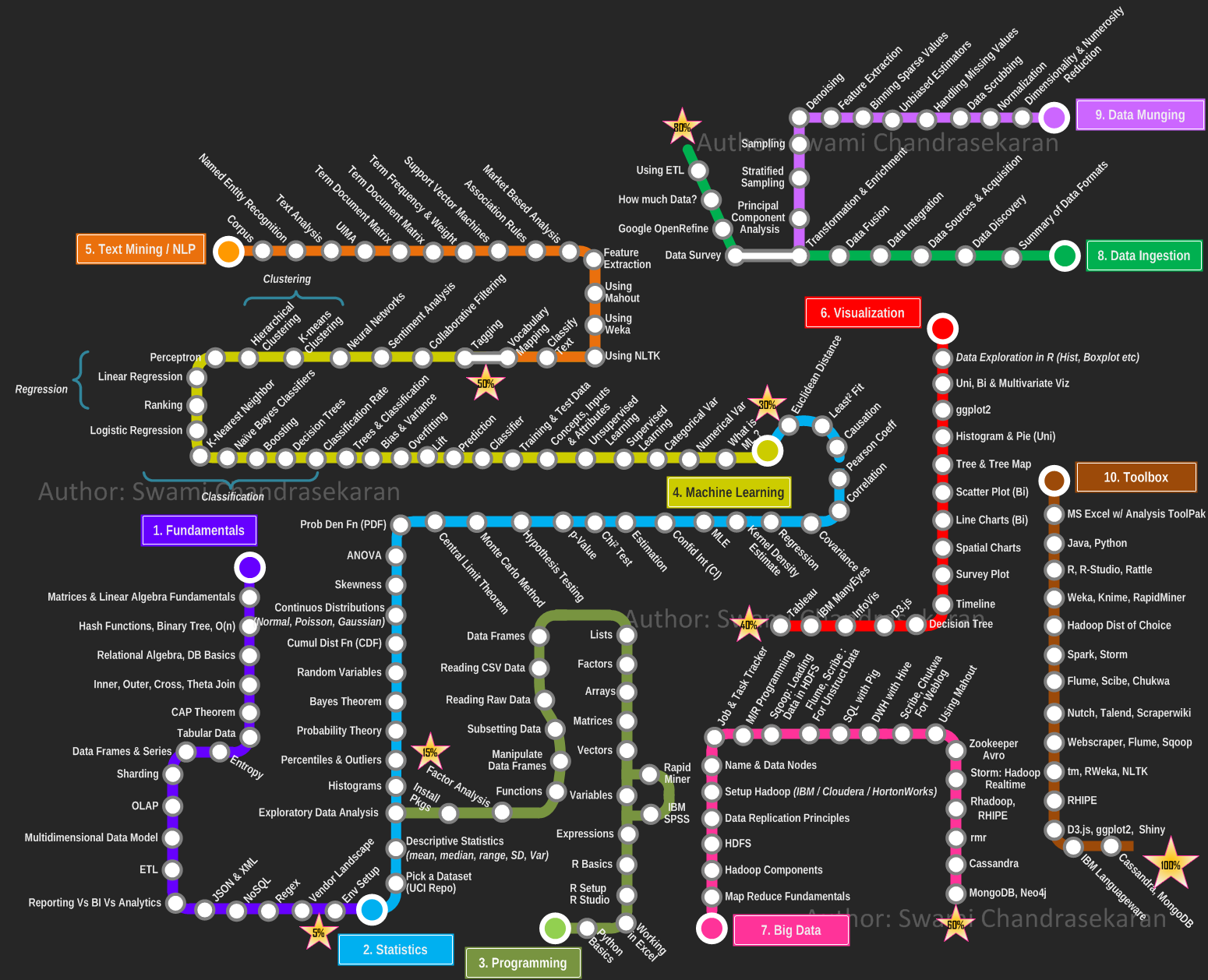 |
Swami Chandrasekaran made a Curriculum via Metro map. |
 |
by @kzawadz via twitter |
 |
By Data Science Central |
 |
From this article by Berkeley Science Review. |
 |
Data Science Wars: R vs Python |
 |
How to select statistical or machine learning techniques |
 |
Choosing the Right Estimator |
 |
The Data Science Industry: Who Does What |
 |
Data Science Venn Diagram |
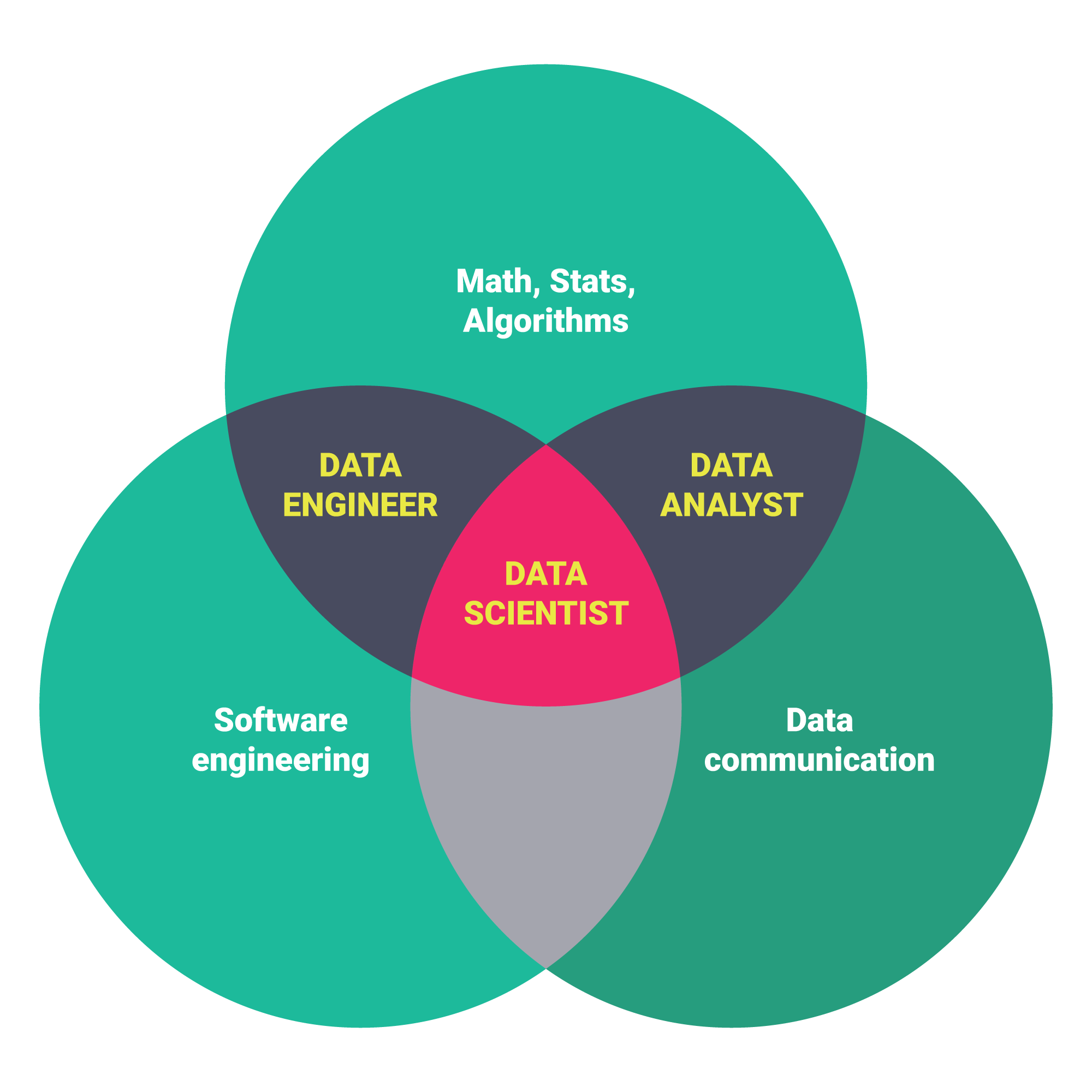 |
Different Data Science Skills and Roles from this article by Springboard |
 |
A simple and friendly way of teaching your non-data scientist/non-statistician colleagues how to avoid mistakes with data. From Geckoboard's Data Literacy Lessons. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
- Awesome Data Science
- Data Science Resources
- Data science blogs
- Machine Learning for Software Engineers
- Data Science Specialization resources
- Data Science Specialization notes
- Python Data Science Tutorials
- R Data Science Tutorials
- Machine Learning & Deep Learning Tutorials
- Learn Data Science open resources
- List of Data Science/Big Data Resources
- General Assembly's Data Science course materials
- Scikit-learn Tutorial
- theano-tutorial
- IPython Theano Tutorials
- ISLR-python
- Awesome R
- Evaluation of Deep Learning Frameworks
- Amazon Web Services — a practical guide
-
Quora
-
Reddit
- How To Prepare For A Machine Learning Interview
- 40 Interview Questions asked at Startups in Machine Learning / Data Science
- 21 Must-Know Data Science Interview Questions and Answers
- Top 50 Machine learning Interview questions & Answers
- Machine Learning Engineer interview questions
- Popular Machine Learning Interview Questions
- What are some common Machine Learning interview questions?
- What are the best interview questions to evaluate a machine learning researcher?
- Collection of Machine Learning Interview Questions
- 121 Essential Machine Learning Questions & Answers
- Top 50 Spark Interview Questions and Answers for 2018