This project is forked from torch-scae: PyTorch implementation of Stacked Capsule Auto-Encoders.
A joint work with Nader Karayanni.
# clone project
git clone https://github.com/bdsaglam/roymatza/torch-SCAE-handbone-age-assesment
# install project
cd torch-SCAE-handbone-age-assesment
pip install -e .- Download the needed utils from SCAE-utils repo.
# clone project
git clone https://github.com/roymatza/SCAE-utils- Activate the attached conda env (using environment.yml file), and run the following commands to support visualizing the results and progress in the notebook:
jupyter nbextension enable --py widgetsnbextension
jupyter labextension install @jupyter-widgets/jupyterlab-manager-
You can acquire the data needed for the experiments from : https://www.kaggle.com/kmader/rsna-bone-age
-
The torch_scae folder contains the implementation of the SCAE architecture using the lighting module interface. This folder contains all the logic described in the original SCAE paper (AR Kosiorek & al., 2019). The torch_scae_experiments contains specific models configurations for experiments, for example for our experiments we created a folder named 'boneage' which contains all the relevant info specifically defined for the corresponding task (Hyper params,images input sizes , data manipulation files etc...)
- Process the data:
- Using the provided script (process-data.py, edit the script with your folders for the data and run it to get a new folder with the processed data.
- Create the folders needed to get the path "\src\torch_scae\data\boneage\train" and inside it place the processed data.
- Create the path \src\torch_scae\data\boneage\test\test0" and move some arbitrary image to that folder (this is required for the code to have a test data even though it is not used in the notebook).
- Run arrange_folders_by_age.py script with the corresponding train directory with the processed data. The data should be split into labels folders within the same folder.
- After that you can simply run the train.ipynb jupyter notebook from "src" and the experiments are done within the notebook's cells.
Additional Notes:
- Make sure to fill the needed fields in the notebook accordingly such as the paths (marked with TBD in the notebook).
- Checkpoints and tensorboards are saved in "/src/lightning_logs".
- To get the optimal run that we know of, it is needed to manually change a boolean variable is_reg_reset to True inside stacked_capsule_autoencoder.py after several epochs, and then rerun the experiment from the last checkpoint.
PyTorch Lightning is used for training.
python -m torch_scae_experiments.mnist.train --batch_size 32 --learning_rate 1e-4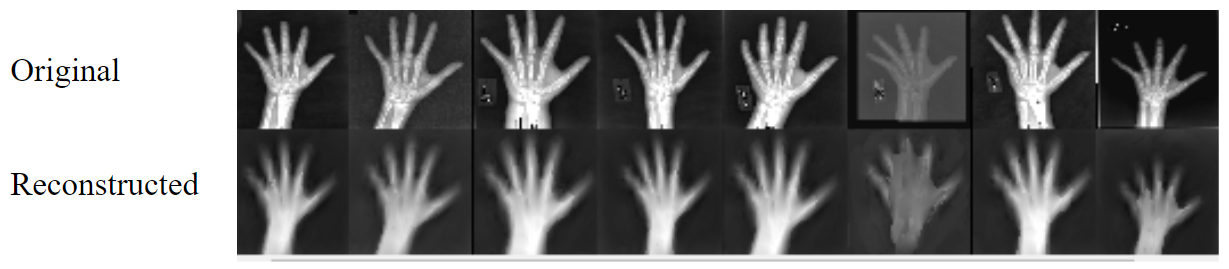
Further information can be found in the project final report.