Analysis Plugins
The objective is to integrate an analysis mechanism that will run different tests, will report a status for each of them with a meaningful comment. The mechanism provided by opal will be analysis independent and analysis routines will be provided by plugins. A generic analysis plugin will be based on Github repo (routines will be downloaded from Github, repositories are configurable).
Improve the data quality by reusing and sharing data quality inspection routines.
- Square2 – A Web Application for Data Monitoring in Epidemiological and Clinical Studies
- Outlier Treatment with R
- dlookr R package
- validate R package
Describe simply who is doing what and how to obtain the result.
| # | Who | What | How | Result |
|---|---|---|---|---|
| 1 | ||||
| 2 | ||||
| ... |
- Plugin
- GWT UI
- R server
Despite Opal only support R as data processing backend, it would be good to have an data processing engine independent analysis plugin definition. Then a R specific SPI will be designed.
The data analysis flow will:
- on startup, opal discovers the
opal-analysisplugins and makes them available in the UI (list of plugins with their associated schema form) - user goes to a table page where he/she can find a new tab called "Analysis"
- the "Analysis" tab offers:
- to prepare an analysis by selecting a routine, settings its parameters and specifying (option) the subset of the table on which the routine is to be executed
- to view the previous analysis with their associated report: status, message, times and report in markdown or in pdf
- an analysis batch (set of routines with parameters) can be saved for reuse.
- when an analysis batch is sent:
- a project task is created
/project/{prj}/_analyse - a R session is created, the table (or its subset, represented by a view wrapper) is then pushed to the R session as a tibble
- the R analysis service is then triggered with the tibble symbol and the R session provided
- each of the R analysis routine must return a result including: status, message, times and report in markdown or in pdf. These results are persisted (data files or orientdb?)
- the user can follow the progress of the analysis batch in the "Tasks" tab
- a project task is created
The analysis SPI (and its R specific version) will define:
-
AnalysisTemplatethat describes the analysis routine (name, title, description (markdown), JSON schema form) -
Analysisrepresents an instance of an analysis request, with a name, associated template name, and parameters -
AnalysisResultreports the results of anAnalysis(timestamps, status, output message, report location). Sometimes a single analysis has multiple parameters that leads to multiple sub-results. In this case there is a global result (if one sub-result is Failed, then global result is Failed as well) and a list of sub-results.
The data analysis plugin implementations will have access to the convenient classes that allows to perform R operations from Opal (R script, data assignment, file transfers).
A generic R-based analysis plugin implementation could be provided. This implementation could download R routines from one or more github repositories (file layout would follow some naming conventions). This way the same plugin (configured in the opal plugin management page) could propose a set of analysis that is extensible.
| REST | Description |
|---|---|
GET /analysis-plugins |
List available analysis plugins and for each of them the analysis templates |
GET /analysis-plugin/{plg} |
Get a specific analysis plugin DTO |
POST /project/{prj}/commands/_analyse |
Launch a analysis task (can be multiple sub-analysis, but only on one table) |
GET /project/{prj}/analyses |
List all the recorded analyses for the project (filtered by permission) |
GET /project/{prj}/table/{tbl}/analyses |
List all the recorded analyses for the table |
GET /project/{prj}/table/{tbl}/analysis/{id} |
Get a specific table recorded analysis |
GET /project/{prj}/table/{tbl}/analysis/{id}/results |
Get a specific table recorded analysis results |
GET /project/{prj}/table/{tbl}/analysis/{id}/result/{rid} |
Get a specific table recorded analysis result |
A user needs to have the permission to see table values in order to make analysis (pretty much like the reports).
The analysis is executed asynchronously by the task system. See how done with the Report.
The analysis results are to be saved in Opal's internal database (OrientDB). Result files, if any, are to stored separatly in the folder OPAL_HOME/data/analyses/{id}/results/{rid}.
- On Analysis deletion, all associated results shall be deleted
- On Table deletion, all associated analysis with their result shall be deleted
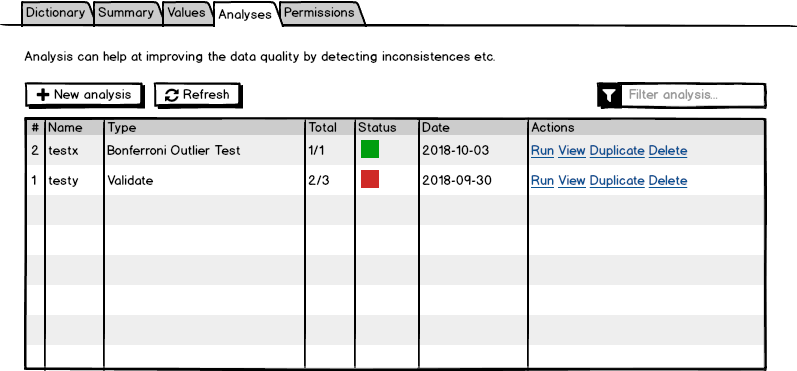
The list is a list of AnalysesResults.
- on Run, the
analysetask is submitted and the user is informed by a notification growl, - on View, the analysis type and parameters are displayed (same as the New Analysis dialog but read-only) with the details of the result,
- on Duplicate, a New Analysis dialog is opened with the same field values,
- on Delete, the analysis result is removed (and associated documents and permissions).
On analysis type selection, the Parameters section is rebuilt from the corresponding schemaform.

Viewing analysis result shows the analysis type and parameters and the last execution results. Depending whether there are sub-results, a Details section shows the status of each of these tests.

Some results can have sub result items:

How can the feature be tested or demonstrated. It is important to describe this in fairly great details so anyone can perform the demo or test.
This should highlight any issues that should be addressed in further specifications, and not problems with the specification itself; since any specification with problems cannot be approved.