Udacity AWS Machine Learning Engineer Nanodegree (ND189)
P5 Amazon Bin Image Dataset object counting, a demonstration of end-to-end machine learning engineering skills on AWS
All the techniques listed below can be seamlessly applied to large-scale datasets, including terabyte-scale training data, ensuring efficient processing and scalability without overwhelming infrastructure resources. Together, they form a comprehensive machine learning development workflow — covering ETL, EDA, data ingestion, training (with tuning, debugging, and profiling), inference, monitoring, and etc.
-
For demonstration purposes, a subset of 10,441 samples with 5 classes was selected from the original dataset of over 500,000+ entries.
-
Exploratory Data Analysis (EDA) was performed using AWS Athena
CTASand Trino SQL queries on the 10K metadata JSON files. The 10,441 JSON files were efficiently consolidated into 21 SNAPPY-compressed Parquet files in just 3.6 seconds. -
AWS Glue-Spark job scripts were developed locally using Docker with AWS Glue Docker images hosted on Docker Hub or Amazon ECR Public Gallery and VS Code (IDE) for further EDA tasks, such as generating visualizations of the class distribution and other data insights.
-
To prepare the dataset for training, AWS SageMaker's ScriptProcessor was utilized in combination with a custom Docker image uploaded to AWS ECR. The
10K datasetwas successfully converted into WebDataset.tarfiles for streamlined data loading during training. -
WebDataset (a subclass of PyTorch IterableDataset) is leveraged with the
'pipe'command to stream data directly from S3 to the SageMaker training instance(s). This approach enables efficient handling of terabyte-scale datasets without needing to copy the entire dataset to the training instance(s) at once. As a result, there’s no need for instances with large storage or external mounts like EFS, significantly reducing infrastructure costs. Additionally, this method offers a cost-effective alternative to using Amazon FSx, as it only incurs a fraction of the cost while still enabling large-scale data processing.-
FastFileinput mode streams data in real-time and is cost-effective. However, when streaming smaller files directly from Amazon S3, the overhead of dispatching a new GET request for each file becomes significant relative to the file transfer time (even with a highly parallel data loader and prefetch buffer). This results in lower overall throughput forFastFile Mode, causing an I/O bottleneck during training. (Refer to the officail blog post about SageMakerInput Mode.) -
In reality, the Amazon Bin Image Dataset consists of 500K sample file pairs, with a total size of around 60GB — falling comfortably within the 50-100GB range — so we can use
File Mode, which copies the entire dataset to the training instance before the training begins. However, for the purpose of this project, we are simulating tens of terabytes of data.
-
-
AWS SageMaker Distributed Data Parallel (SMDDP) framework is combined with WebDataset for distributed training. SMDDP efficiently manages tasks such as model replication across GPU nodes, asynchronous training, and synchronization of model weights across nodes. Meanwhile, WebDataset handles the shuffling, transforming, node-wise data splitting, and batching of training data, ensuring seamless data distribution for each node during training.
-
SageMaker features like debugging, profiling, logging with CloudWatch, model deployment, inference, endpoint scaling, production variants, and monitoring were demonstrated in previous course projects and hands-on exercises, such as the P3 Dog Breed Image Classification project.
-
Technical tips:
- The
WebDatasetclass inherits from PyTorch'sIterableDataset, which isn't compatible with the standard PyTorchDataLoader. Instead, use theWebLoaderfrom WebDataset to create and iterate batches of streamed data. - To implement early stopping for distributed training, for example, when validation loss doesn't improve for 5 epochs, use SMDDP's
dist.all_reduce(tensor_early_stop, op=dist.ReduceOp.MAX)to notify all nodes to stop. - To address class imbalance in large streamed training datasets, we can leverage big data analytics tools during pre-processing to calculate class weights, which can then be passed to the training instance as a hyperparameter.
- Wandb (Weights and Biases) is used for experiment tracking and visualizing machine learning training runs, which allows us to log training information, such as loss, accuracy, and other metrics, as well as visualize training curves in real-time.
- Check the pricing and AWS Service Quotas at the account level when selecting SageMaker EC2 instances. By default, there is no quota for GPU spot instances available.
- You can run SageMaker locally using your preferred IDE, which helps you avoid the costs associated with SageMaker Studio. Just configure your AWS config and credentials files on your local machine, ensure that your SageMaker session starts with the correct profile, and retrieve the appropriate execution role.
- The
- Local conda env
- Windows 11 (OS), VS Cdoe (IDE), AWS SageMaker / Glue / Athena / S3 / ECR / IAM / CloudWatch, Wandb, Docker
- Folder structure:
/starter ├── # ETL, EDA, training/tuning/deployment/etc. notebooks └── `AWS Athena Trino SQL.md` # Athena CTAS and queries /docker_workspace # folder attached to the local Glue-Spark Docker container └── `aft-vbi-pds.ipynb` # PySpark analysis of the metadata /docker_process └── `dockerfile` # To create a custom image for SageMaker Processor /scripts_process └── `convert_to_webdataset_10k.py` # Major preprocessing script for SageMaker Processor /scripts_train ├── `train_v1.py` # Major training script for SageMaker Torch estimator └── `train_draft.py` ## Refer to the draft script for detailed comments /scripts_inference └── # deployment scripts /examples └── # experiments /data # in the `.gitignore` file └── # local data /secrets # in the `.gitignore` file └── # AWS account numbers, profile names, etc.; wandb secret
-
Check the PySpark EDA notebook on a subset of the metadata (10K out of 500K JSON files from the original dataset)
-
Demo video: Query and consolidate a large number of small JSON files with AWS Athena

Check the AWS Athena Trino SQL -
Demo video: Develop local AWS Glue Spark jobs with Docker and VS Code
Check the Text format tutorial
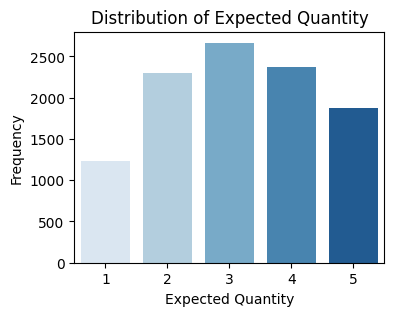
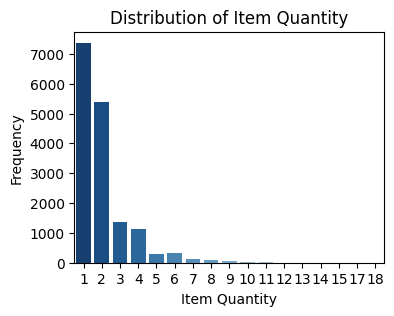
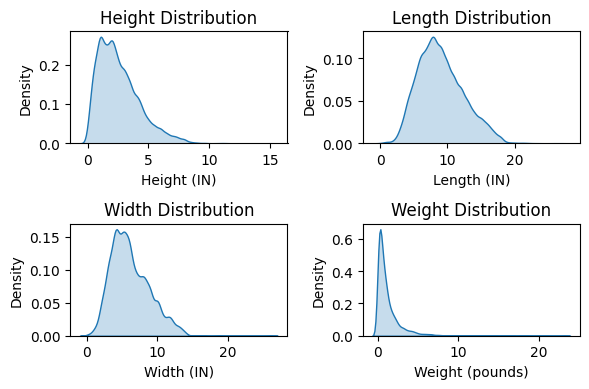
-
-
From the target (expected quantity) distribution plot, we can see that there is class imbalance. Additionally, the item quantity distribution plot shows that most items only have one or two images.
-
Shuffle the dataset, then split it into train, validation, and test sets. Use WebDataset to convert pairs of
.jpgand.jsonfiles into.tarfiles, where each file contains a shard with (__key__, jpg, class) data — e.g., a shard size of 1,000 samples. Ultimately, the 10,441 samples are saved as 7, 2, and 2.tarfiles for the train, validation, and test sets, respectively, and stored in an S3 bucket with the prefixs3://p5-amazon-bin-images/webdataset/train/,~/val/and~/test/.-
✅ Check the docker file to build the custom image for SageMaker Processor
-
✅✅ Check the processing notebook and script
- In the processing script
def convert_dataset(type_prefix, ## e.g. "train/" file_list, maxcount=1000): ## number of items per shard shard_prefix = type_prefix[:-1] + "-shard-" ## e.g. file name: "train-shard-000000.tar" with wds.ShardWriter(f"{shard_prefix}%06d.tar", maxcount=maxcount) as sink: for image_id,label in file_list: image_key = f'{input_prefix_images}{image_id}.jpg' try: # Ensure the corresponding JSON file exists image_data = read_s3_file(input_bucket, image_key) except Exception as e: print(f"⚠️ Skipping image '{image_key}' due to error: {e}") continue # Save as WebDataset sample sink.write({ "__key__": f"{image_id}", "image": image_data, "label": label, })
- In the processing script
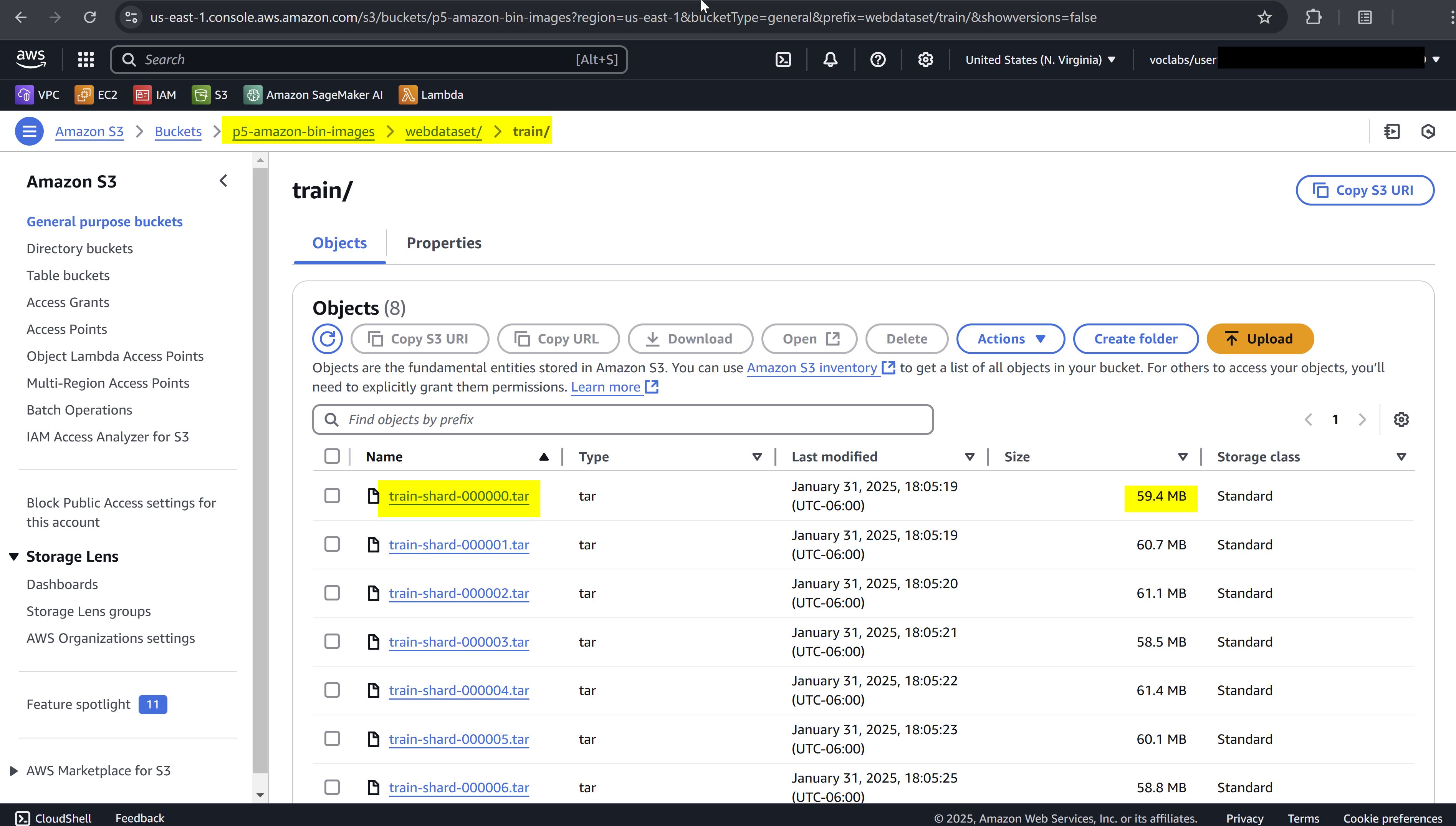
-
-
During training, we can stream the data from S3 to the training instances by passing the dataset paths as hyperparameters. In the training script, we use WebDataset
DataPipelineandWebLoaderto stream, buffle, shuffle, split by node (GPUs), transform, batch the data.data_base_path = "s3://p5-amazon-bin-images/webdataset/" train_data_path = data_base_path + "train/train-shard-{000000..000007}.tar"
path = f"pipe:aws s3 cp {task.config.train_data_path} -" train_dataset = ( wds.DataPipeline( wds.SimpleShardList(path), # at this point we have an iterator over all the shards wds.shuffle(1000), wds.split_by_node, # at this point, we have an iterator over the shards assigned to each worker wds.tarfile_to_samples(), # this shuffles the samples in memory wds.shuffle(1000), # this decodes image and json wds.to_tuple('image', 'label'), wds.map_tuple( train_transform, label_transform, ), wds.shuffle(1000), wds.batched(task.config.batch_size), ) ) num_batches = task.config.train_data_size // (task.config.batch_size * dist.get_world_size()) task.train_loader = ( wds.WebLoader( train_dataset, batch_size=None, num_workers=task.config.num_cpu, ).unbatched() .shuffle(1000) .batched(task.config.batch_size) ## A resampled dataset is infinite size, but we can recreate a fixed epoch length. .with_epoch(num_batches) )
-
Use SageMaker Distributed Data Parallel (SMDDP) framework for distributed training
-
✅✅✅ Check the SageMaker notebook and the training script
- Beginning of the script
import smdistributed.dataparallel.torch.distributed as dist from smdistributed.dataparallel.torch.parallel.distributed import DistributedDataParallel as DDP dist.init_process_group( backend="smddp", ## SageMaker DDP, replacing "nccl" timeout=timedelta(minutes=5), ## default 20 minutes? )
- When creating the neural network
def create_net(task): ... task.model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(task.model) ## PyTorch DDP ## Wrap model with SMDDP task.model = DDP(task.model.to(task.config.device), device_ids=[torch.cuda.current_device()]) ## single-device Torch module
- In the main function
create_net(task) ## SMDDP: Pin each GPU to a single distributed data parallel library process. torch.cuda.set_device(dist.get_local_rank()) task.model.cuda(dist.get_local_rank())
- Test and save model on one node only
if dist.get_rank()==0: print("🟢 Start testing...") eval(task, phase='test') print("🟢 Start saving the trained model...") save(task)
-
-
Use WebDataset to convert and stream datasets to the training instances from S3
-
Use 2
ml.g4dn.xlargeGPU instances for training and HPOAWS SageMaker HPO Warm Pools improve hyperparameter optimization efficiency, especially in distributed training, by reusing instances between jobs, reducing provisioning time, lowering latency, and optimizing resource use. This is particularly valuable for distributed training, where large instance clusters are reused, speeding up experimentation and cutting costs while enabling faster convergence on optimal hyperparameters.
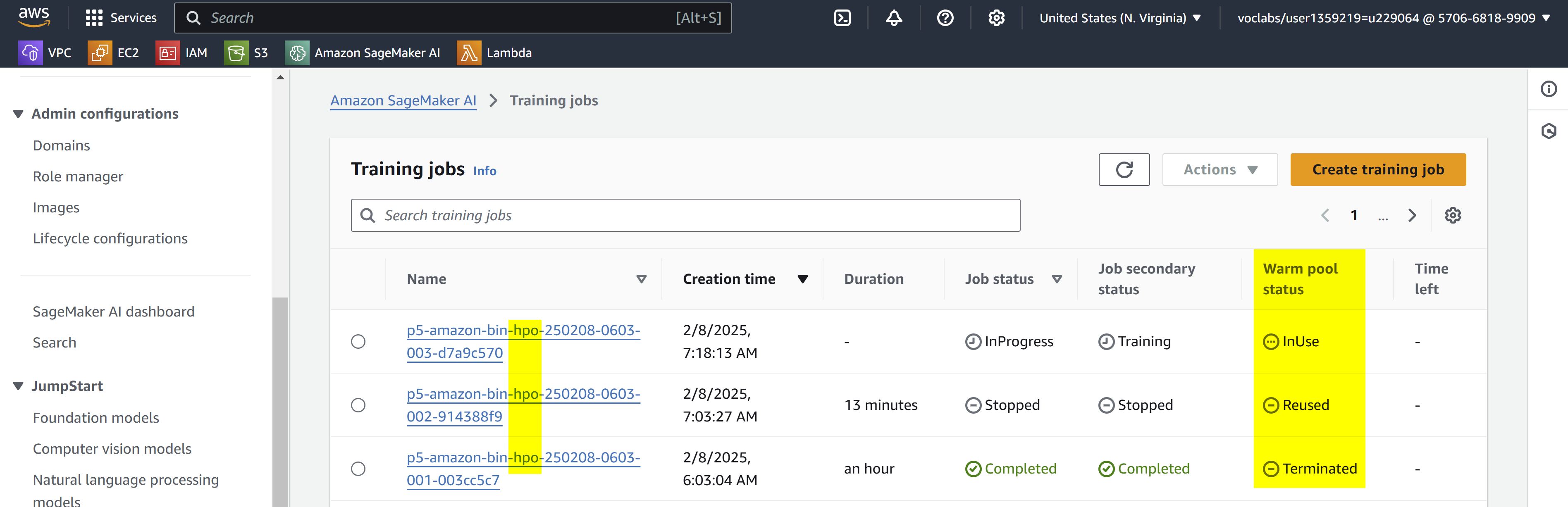
-
Use wandb to visulize the training curves.
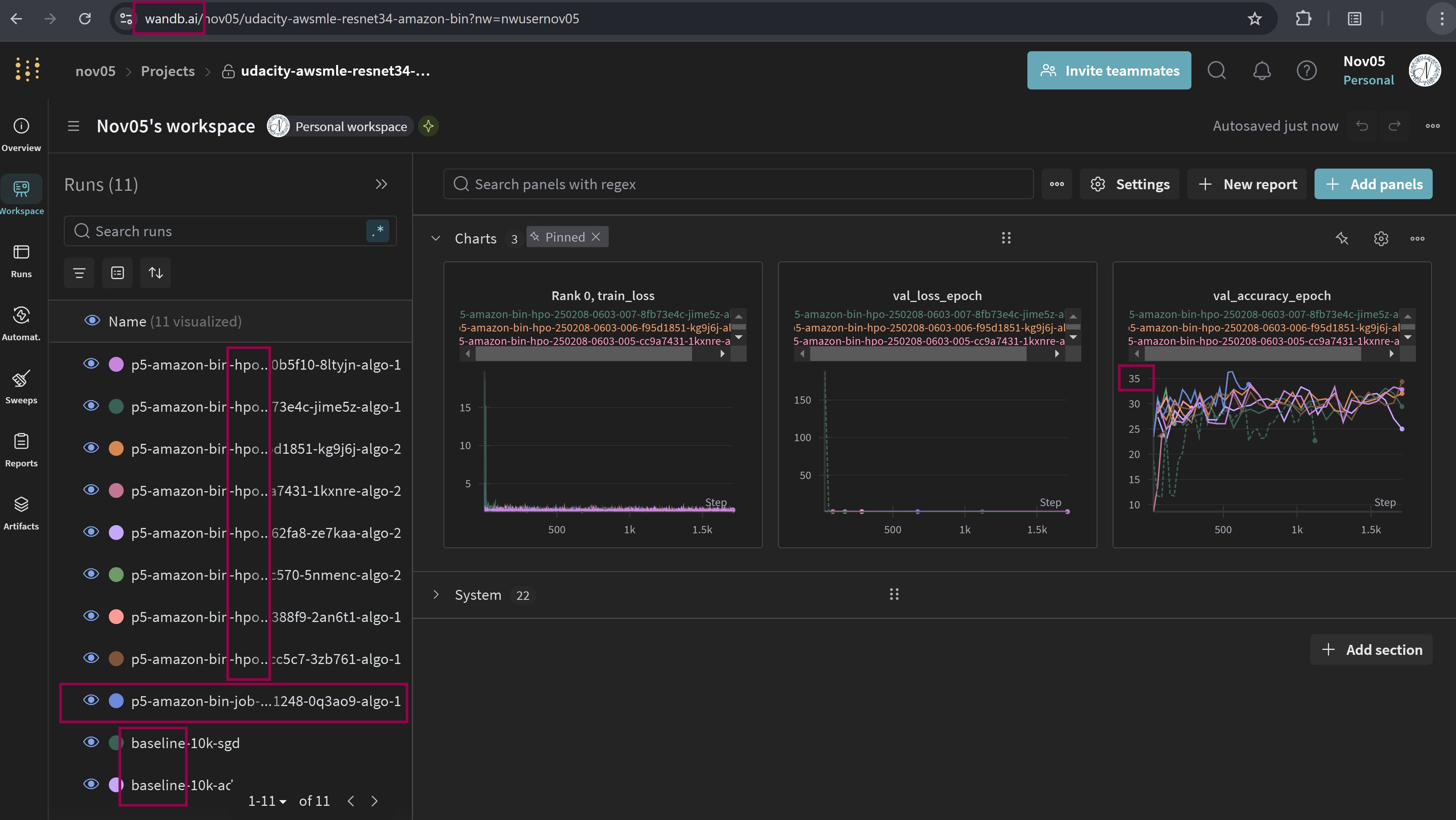
-
Check AWS CloudWatch logs

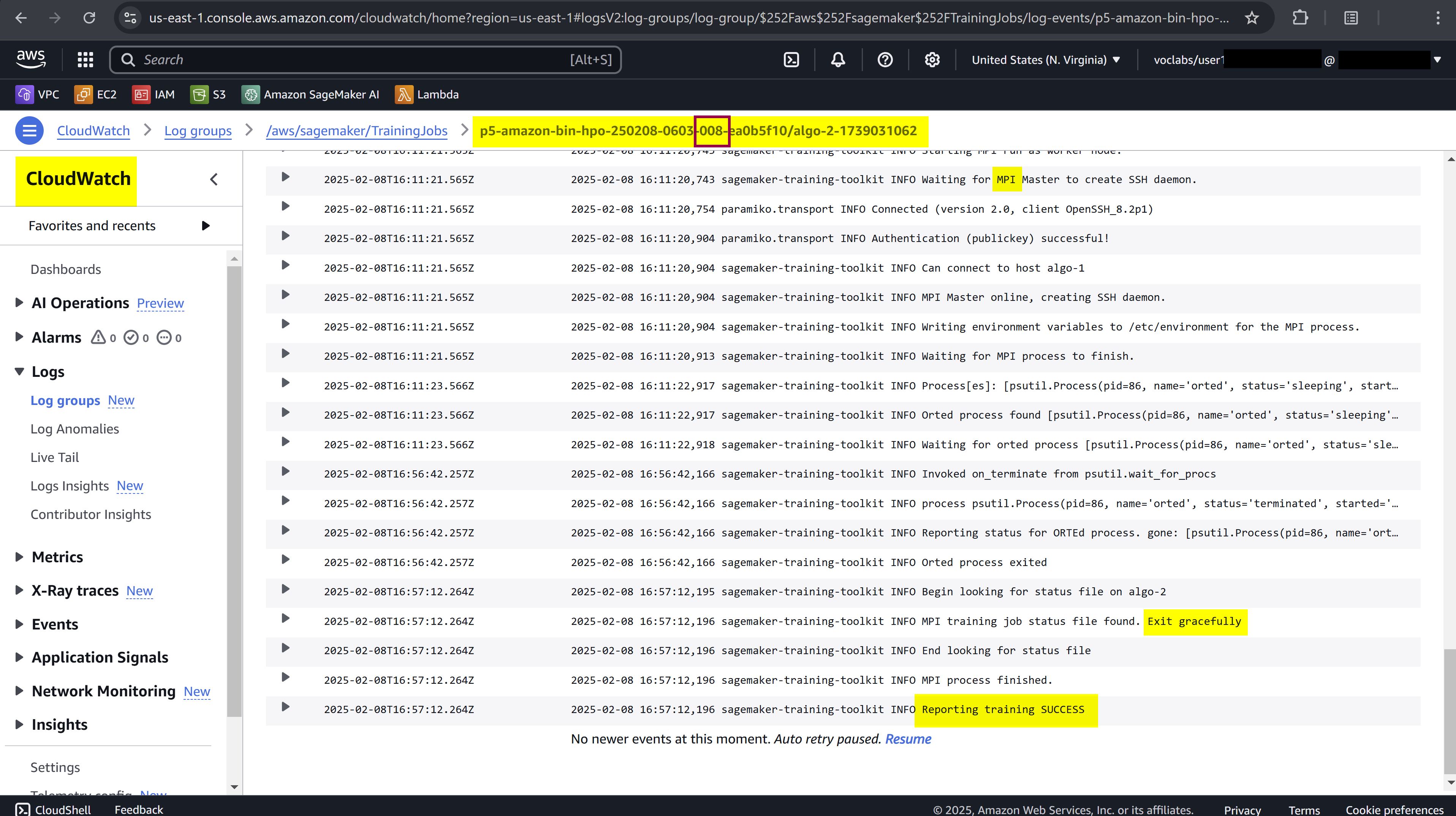
Take note of the MPI logs. According to the official documentation, the SageMaker Distributed Data Parallel library uses the Message Passing Interface (MPI), a widely used standard for communication between nodes in high-performance clusters, along with NVIDIA’s NCCL library for GPU-level communication.
- In the training notebook:
from sagemaker.pytorch import PyTorch estimator = PyTorch( ... distribution={"smdistributed": {"dataparallel": { "enabled": True}}}, )
- In the training notebook:
-
Find the best hyperparameter job from HPO. You can deploy from the job name, or from the model S3 URI.
%20-%20Vi.jpg)
Note:
-
Model performance and training accuracy are not the focus of this project, as outlined in the project proposal. Instead, the objective is to build a machine learning training pipeline for handling relatively large datasets in AWS.
-
Since I focused primarily on mocking big data ETL and distributed training in this project, and have already gained experience with debugging and profiling (as well as wandb sweeping, deployment, inference, etc.) in previous projects, I'll be skipping those steps here. (Check the notebooks from P3 dog breed image classification.)
-
That said, I’d like to mention the training results using 10K out of 500K samples. The best accuracy achieved was around 36%, compared to 55.67% achieved by others using the full 500K dataset. My speculation is that this is likely close to the best possible result from such a small dataset (1/50th of the original). Given that this is a demo project with limited resources, I’ll leave the results as they are.
-
Please refer to the source code notebooks, scripts, and project notes for much more technical details. Here, I’m only providing a high-level overview of the work, as including everything would make the
README.mdtoo lengthy. Lol.
-
-
For this project, due to account limitations, I used my own AWS account for the Athena and ECR services, which cost around $2. I used the course credits for the rest, with most of the costs coming from SageMaker instances. I was experimenting and debugging SageMaker Distributed Training with two
ml.g4dn.xlargeGPU instances ($0.526 per hour each), which amounted to about $16, and the HPO job added around $12.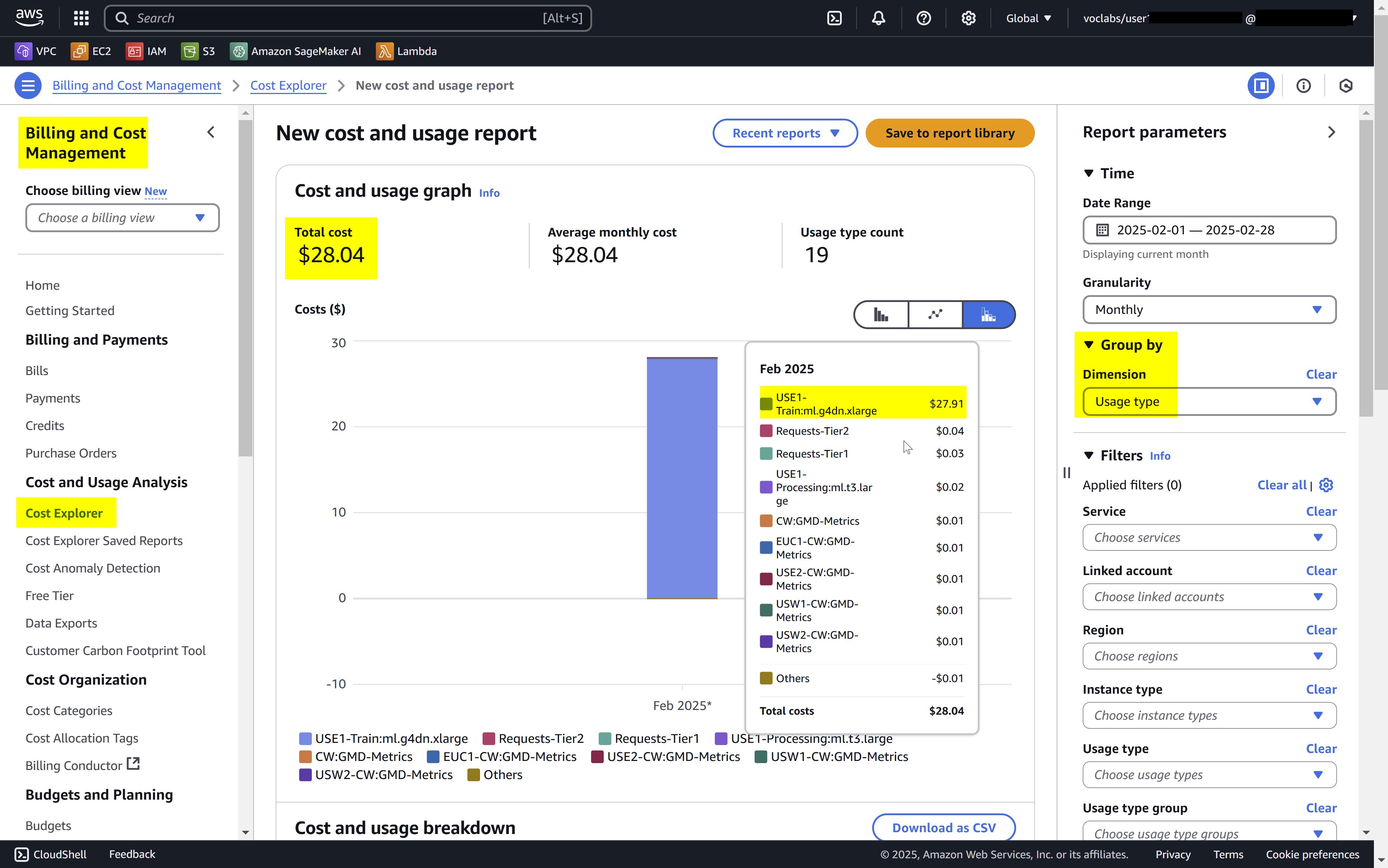
.jpg)
-
By default, there is no GPU spot instance quota available at the account level. You need to submit increase requests through AWS Service Quotas and wait for AWS approval.
- GitHub Issues (closed): How to Implement Early Stopping with WebDataset in SageMaker Distributed Data Parallel (SMDDP) Framework? #446
- SageMaker input mode and WebDataset
- SageMaker PyTorch distributed training
- Different Levels of AWS Resources for Machine Learning Model Training and Deployment
- Tutorial: Create custom docker image for SageMaker data processing jobs, create AWS ECR private repo, and upload the image to the repo
✅ All other notes for the nanodegree on Google Drive
-
In distribution centers, bins often carry multiple objects, making accurate counting important for inventory and shipments. This project focuses on building a model that can count the number of objects in a bin from a photo, helping to track inventory and ensure correct deliveries.
-
Machine learning in image processing has evolved significantly over the past few decades. Early approaches in the 1960s and 1970s relied on basic statistical methods and hand-crafted features to analyze images. In the 1990s, support vector machines (SVMs) and k-nearest neighbors (k-NN) became popular for tasks like image classification.
The real revolution came with the rise of deep learning in the 2010s, particularly through convolutional neural networks (CNNs), pioneered by Yann LeCun in the late 1990s. AlexNet's win in the ImageNet competition in 2012 demonstrated the power of deep CNNs for large-scale image recognition, leading to a boom in deep learning research. This was followed by more advanced models like VGG, ResNet, and EfficientNet.
Today, transfer learning and pre-trained models are commonly used to tackle image processing tasks, significantly reducing the time and resources needed for training. Emerging techniques like GANs (Generative Adversarial Networks) are now being used for image generation and manipulation. The field continues to advance with innovations in architectures, optimization, and real-time image processing.
- The dataset is huge and the training might take long time.
- The images are blurry, in different sizes, with noises such as tapes over the bin. Objects in the bin are different products in all kinds of shapes and size, and might overlap each other. All these increase the difficulty in prediction.

- The focus of this project is on building a machine learning training pipeline in AWS, with model performance not being a concern.
- For this project, I'll use ResNet34 and train it from scratch, likely for only a few epochs, since accuracy isn't the goal.
- Leverage AWS SageMaker features like Pipe Mode, distributed training, and hyperparameter tuning for faster training. Additionally, use Spot Instances to optimize costs if possible.
- I will use the
Amazon Bin Image Dataset, which contains 535,234 images of bins holding one or more objects. These objects include 459,476 different products in various shapes and sizes. Each image is accompanied by a metadata file that provides details like the number of objects, image dimensions, and object type. Our task is to classify the number of objects in each bin. - For this project, I will only use images of bins containing fewer than 6 objects (0–5 objects, corresponding to 6 classes).
-
Random class baseline (accuracy): 20.08%
-
Largest class baseline (accuracy): 22.27%
-
ResNet34 + SGDR (accuracy): 53.8% (2018, Pablo Rodriguez Bertorello, Sravan Sripada, Nutchapol Dendumrongsup)
This team also stated that they were able to improve model accuracy by 80% using a CNN compared to an SVM, achieving an overall 324% improvement over random. -
ResNet34 + SGD (accuracy): 55.67% (2018, Eunbyung Park)
Accuracy (%) RMSE (Root Mean Square Error) 55.67 0.930 Quantity Per class accuracy(%) Per class RMSE 0 97.7 0.187 1 83.4 0.542 2 67.2 0.710 3 54.9 0.867 4 42.6 1.025 5 44.9 1.311
- Accuracy: whether predicted object numbers matches the actual numbers
- RMSE (Root Mean Squared Error): Indicates how close the predicted object numbers are to the actual values, with larger errors being penalized more.
- If the model begins training and shows steady improvements in accuracy with each epoch, we can confirm that the training pipeline is functioning properly, which meets the project's goal. There's no need to train until the highest accuracy is achieved, as accuracy isn't the concern for this project.
- Exploratory Data Analysis (check the notebook)
- Limit the project to only use images of bins containing fewer than 6 objects (0~5 objects, 6 classes).
- There are over 500,000 images in the dataset. After sampling the image sizes, I found that they range from 40 to 120 KB, while the JSON files range from 1 to 3 KB each. This means the total size of the image data is between 20 and 60 GB, and the JSON data is between 0.5 and 1.5 GB. Hence we choose fast file mode, or pipe mode as the training data input mode.
https://docs.aws.amazon.com/sagemaker/latest/dg/model-access-training-data.html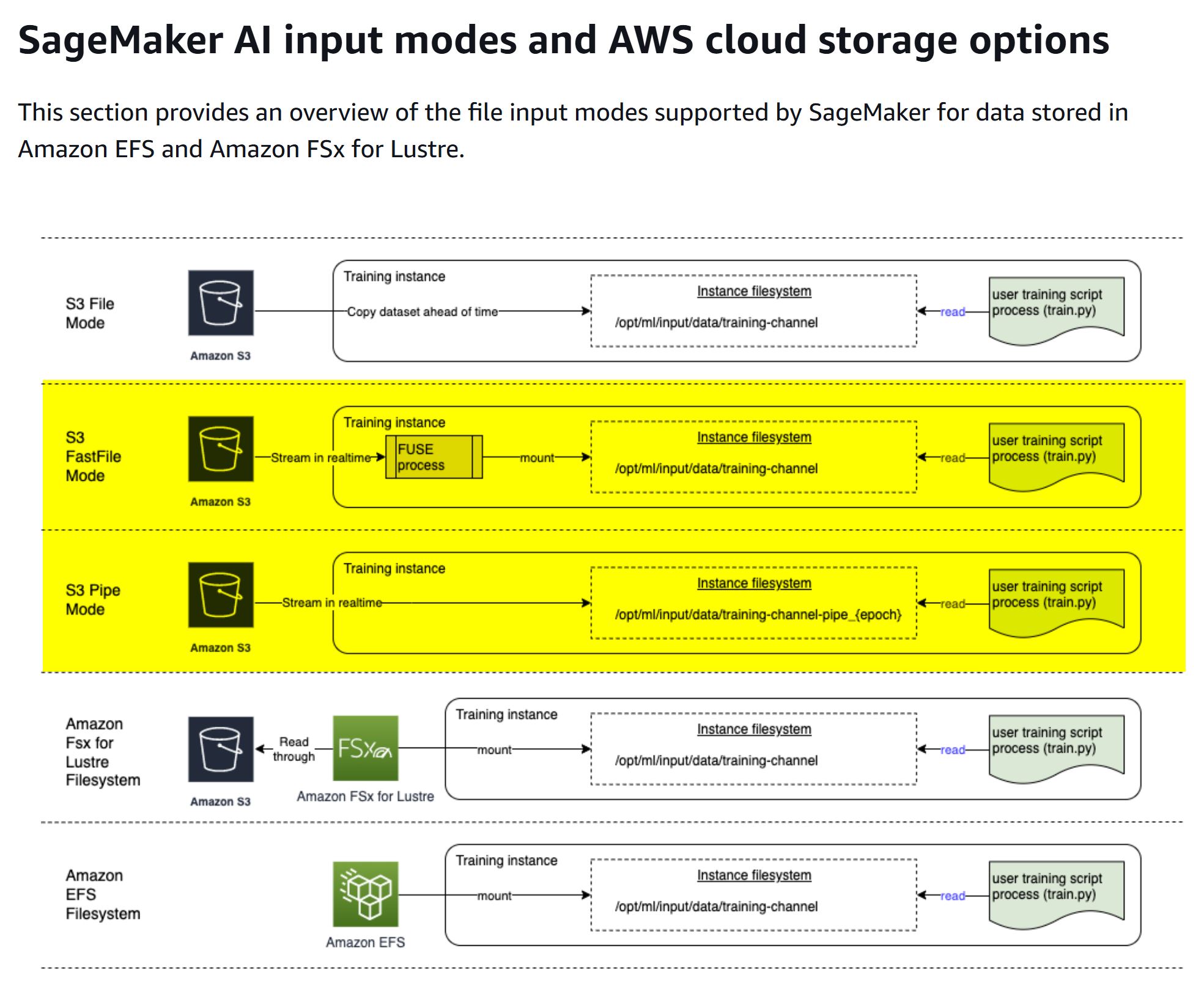
- The original dataset actually fits Scenario C: your dataset is too large for File mode, or has many small files (which you can’t serialize easily), or you have a random read access pattern. Hence, FSx for Lustre would be a great choice. However, the estimated throughput cost would be around $300 for 60GB of data, so I’ve decided not to use it as input mode.
https://aws.amazon.com/blogs/machine-learning/choose-the-best-data-source-for-your-amazon-sagemaker-training-job/
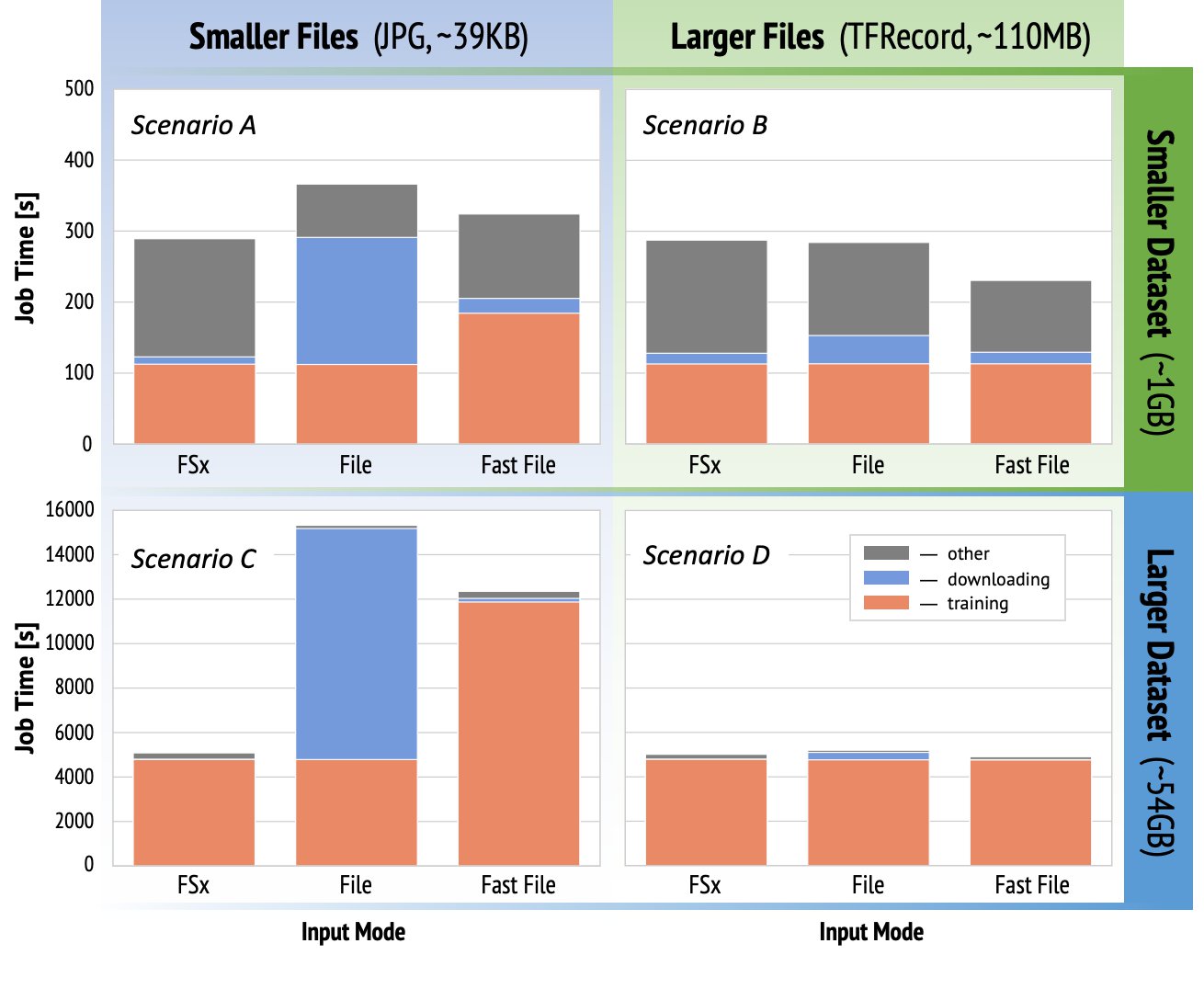
- To prototype the training data input process, we can use the 10,441 images listed in the
file_list.jsonfrom the starter repository. - Use SageMaker script mode with an AWS GPU instance like
g4dn.xlargeand enable multi-instance training. - Hyperparameters tuning
- Deploy endpoint
- Testing the endpoint
- Clean up resources
Distribution centers often use robots to move objects as a part of their operations. Objects are carried in bins which can contain multiple objects. In this project, you will have to build a model that can count the number of objects in each bin. A system like this can be used to track inventory and make sure that delivery consignments have the correct number of items.
To build this project you will use AWS SageMaker and good machine learning engineering practices to fetch data from a database, preprocess it, and then train a machine learning model. This project will serve as a demonstration of end-to-end machine learning engineering skills that you have learned as a part of this nanodegree.
To complete this project we will be using the Amazon Bin Image Dataset. The dataset contains 500,000 images of bins containing one or more objects. For each image there is a metadata file containing information about the image like the number of objects, it's dimension and the type of object. For this task, we will try to classify the number of objects in each bin.
To perform the classification you can use a model type and architecture of your choice. For instance you could use a pre-trained convolutional neural network, or you could create your own neural network architecture. However, you will need to train your model using SageMaker.
Once you have trained your model you can attempt some of the Standout Suggestion to get the extra practice and to turn your project into a portfolio piece.
To finish this project, you will have to perform the following tasks:
- Upload Training Data: First you will have to upload the training data to an S3 bucket.
- Model Training Script: Once you have done that, you will have to write a script to train a model on that dataset.
- Train in SageMaker: Finally, you will have to use SageMaker to run that training script and train your model
Here are the tasks you have to do in more detail:
To build this project, you wlll have to use AWS through your classroom. Below are your main steps:
- Open AWS through the classroom on the left panel (Open AWS Gateway)
- Open SageMaker Studio and create a folder for your project
We have provided a project template and some helpful starter files for this project. You can clone the Github Repo.
- Clone of download starter files from Github
- Upload starter files to your workspace
To build this project you will have to use the Amazon Bin Images Dataset
- Download the dataset: Since this is a large dataset, you have been provided with some code to download a small subset of that data. You are encouraged to use this subset to prevent any excess SageMaker credit usage.
- Preprocess and clean the files (if needed)
- Upload them to an S3 bucket so that SageMaker can use them for training
- OPTIONAL: Verify that the data has been uploaded correctly to the right bucket using the AWS S3 CLI or the S3 UI
Familiarize yourself with the following starter code
sagemaker.ipynbtrain.py
Complete the TODO's in the train.py script
- Read and Preprocess data: Before training your model, you will need to read, load and preprocess your training, testing and validation data
- Train your Model: You can choose any model type or architecture for this project
Complete the TODO's in the sagemaker.ipynb notebook
- Install necessary dependencies
- Setup the training estimator
- Submit the job
An important part of your project is creating a README file that describes the project, explains how to set up and run the code, and describes your results. We've included a template in the starter files (that you downloaded earlier), with TODOs for each of the things you should include.
- Complete the
READMEfile
Standout suggestions are some recommendations to help you take your project further and turn it into a nice portfolio piece. If you have been having a good time working on this project and want some additional practice, then we recommend that you try them. However, these suggestions are all optional and you can skip any (or all) of them and submit the project in the next page.
Here are some of suggestions to improve your project:
- Model Deployment: Once you have trained your model, can you deploy your model to a SageMaker endpoint and then query it with an image to get a prediction?
- Hyperparameter Tuning: To improve the performance of your model, can you use SageMaker’s Hyperparameter Tuning to search through a hyperparameter space and get the value of the best hyperparameters?
- Reduce Costs: To reduce the cost of your machine learning engineering pipeline, can you do a cost analysis and use spot instances to train your model?
- Multi-Instance Training: Can you train the same model, but this time distribute your training workload across multiple instances?
Once you have completed the standout suggestions, make sure that you explain what you did and how you did it in the README. This way the reviewers will look out for it and can give you helpful tips and suggestions!
- 2025-02-08 project submission
LinkedIn post - 2025-01-21 tutorial: How to run local Glue Spark jobs with Docker and VS Code
- 2025-01-17 tutorial: Query and consolidate a large number of small JSON files with AWS Athena
- 2025-01-09 project proposal