The objective of this project is to develop a machine learning model that can accurately predict the maximum visibility distance in a given location and weather condition. The model should take into account various weather parameters such as humidity, temperature, wind speed, and atmospheric pressure, as well as geographical features such as elevation, terrain, and land cover. The model should be trained on a large dataset of historical weather and visibility data, and validated using a separate test dataset. The ultimate goal is to provide a tool that can help improve safety and efficiency in various applications such as aviation, transportation, and outdoor activities.
- Python
- FastAPI
- Machine learning algorithms
- Docker
- MongoDB
- AWS S3
- Azure
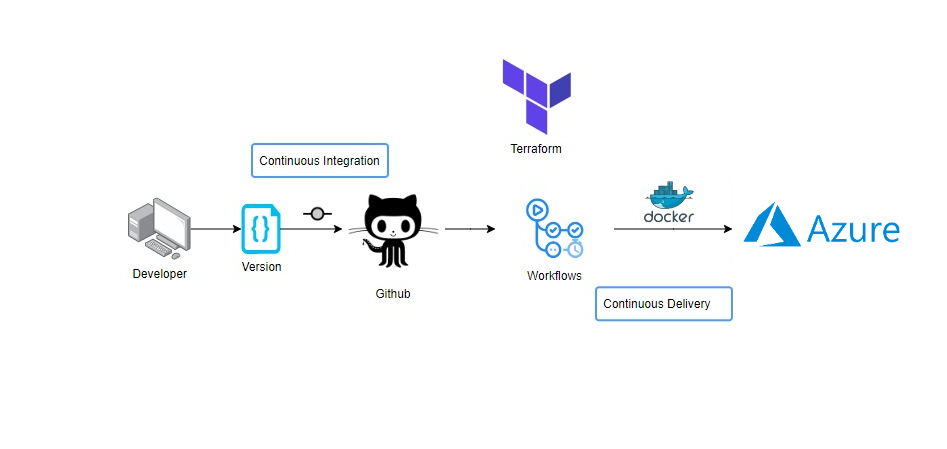
- Github Actions
Before you run this project make sure you have MongoDB Atlas account and you have the shipping dataset into it.
Step 1. Cloning the repository.
git clone https://github.com/Machine-Learning-01/Customer_segmentation.git
Step 2. Create a conda environment.
conda create --prefix venv python=3.7 -y
conda activate venv/
Step 3. Install the requirements
pip install -r requirements.txt
Step 4. Export the environment variable
export AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID>
export AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY>
export AWS_DEFAULT_REGION=<AWS_DEFAULT_REGION>
export MONGODB_URL= <MONGODB_URL>
Step 5. Run the application server
python app.py
Step 6. Train application
http://localhost:5000/train
Step 7. Prediction application
http://localhost:5000/predict
- Check if the Dockerfile is available in the project directory
- Build the Docker image
docker build --build-arg AWS_ACCESS_KEY_ID=<AWS_ACCESS_KEY_ID> --build-arg AWS_SECRET_ACCESS_KEY=<AWS_SECRET_ACCESS_KEY> --build-arg AWS_DEFAULT_REGION=<AWS_DEFAULT_REGION> --build-arg MONGODB_URL=<MONGODB_URL> .
- Run the Docker image
docker run -d -p 5000:5000 <IMAGE_NAME>
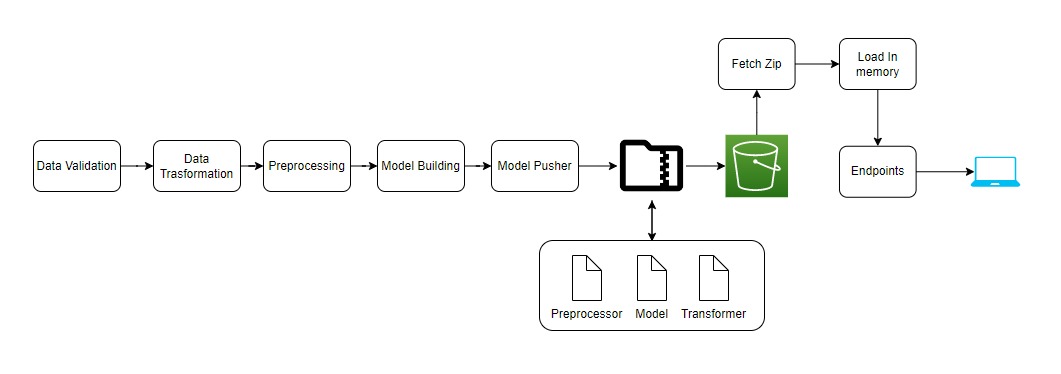
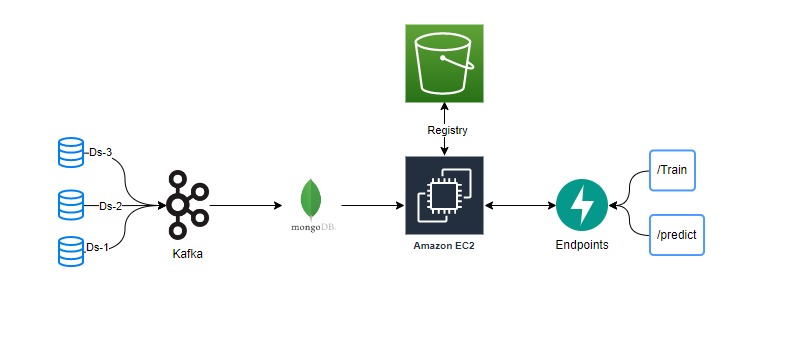
From these above models after hyperparameter optimization we selected these two models which were K-Means for clustering and Logistic Regression for classification and used the following in Pipeline.
- GridSearchCV is used for Hyperparameter Optimization in the pipeline.
Components : Contains all components of Machine Learning Project
- Data Ingestion
- Data Validation
- Data Transformation
- Data Clustering
- Model Trainer
- Model Evaluation
- Model Pusher
Custom Logger and Exceptions are used in the Project for better debugging purposes.
- This Project can be used in real-life by Users.