This project is an AI-powered web scraper that utilizes OpenAI's API, BrightData's Scraping Browser, Selenium, and other libraries to extract and process website data. It is designed to bypass CAPTCHA challenges and interact with web pages dynamically. The extracted content can be processed with a large language model (LLM) for structured data extraction.
- Automated Web Scraping: Uses Selenium and BrightData's Scraping Browser to access and extract content.
- CAPTCHA Handling: Overcomes website CAPTCHA challenges using BrightData's Scraping Browser.
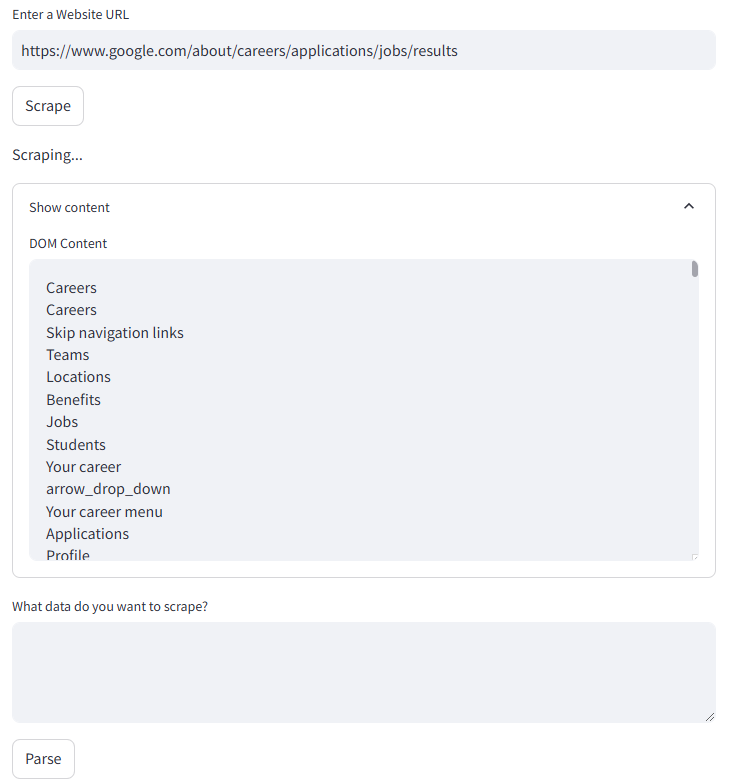
- Content Cleaning: Removes unnecessary elements such as scripts and styles from the extracted HTML.
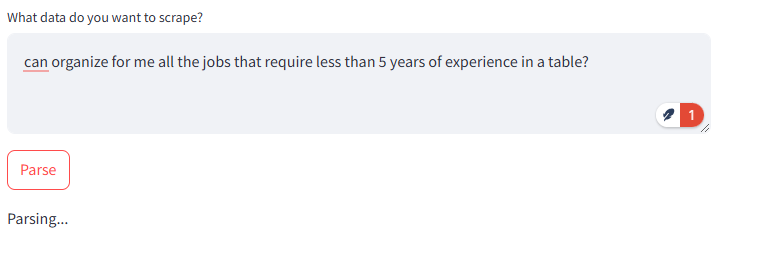
- AI-Powered Parsing: Uses OpenAI's API to process and analyze extracted content.
- Streamlit UI: Provides a simple user interface for inputting website URLs and processing scraped data.
Ensure you have Python installed (version 3.7+ recommended).
- Clone this repository:
git clone https://github.com/naoufalcb/AI-Web-Scraper cd ai-web-scraper - Install dependencies:
pip install -r requirements.txt
- Set up environment variables:
- Adjust the
.envfile in the root directory. - Add your BrightData Scraping Browser WebDriver URL:
SBR_WEBDRIVER=your_scraping_browser_webdriver_url
- Add your OpenAI API key:
GITHUB_TOKEN=your_openai_api_key
- Adjust the
streamlit run main.py
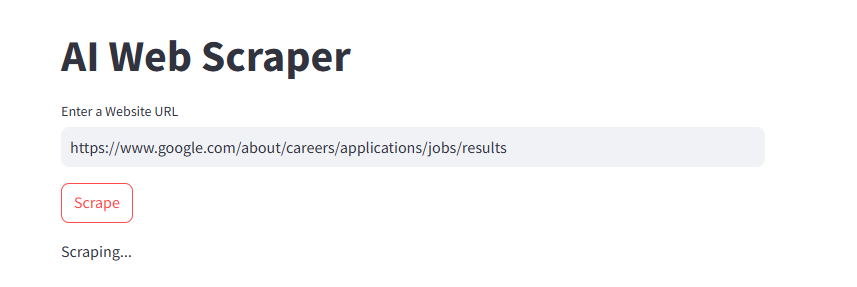
├── scrape.py # Web scraping functions
├── main.py # Streamlit UI
├── llm.py # AI-powered parsing functions
├── requirements.txt # Required dependencies
├── .env # Environment variables
- Streamlit: UI for interacting with the scraper.
- Selenium: Automates browser interactions.
- BeautifulSoup4: Parses and cleans HTML content.
- BrightData Scraping Browser: Enables CAPTCHA bypass and advanced scraping.
- OpenAI API (via LangChain): Processes extracted content.
- Python-dotenv: Manages environment variables.
- Ensure that your BrightData Scraping Browser and OpenAI API credentials are correctly set up in the
.envfile.
This project is licensed under the MIT License.
📧 Email: nchabaa3@gmail.com