Addressing the overall well-being of underserved communities has been a missing part of puzzle in Big Data Science. Every individual should have an equal opportunity to reach their full potential in every sphere of their life, but reality is far behind this. Since so many individuals lack the opportunity to improve their lifestyle, the expulsion of health disparity has been emerged as a major worldwide public health objective. This project focuses on the analysis of the reasons for the prevalence of these problems in a rural community in India and thus preventing those at low cost and high speed.
To unveil this, the content of the text data that has been obtained by conducting surveys and informal interviews from underserved communities in India, are analyzed using two different approaches: (i) Using Word2Vec which helps in understanding the relevant related keywords from the data and (ii) A Text Classification approach using a simple Artificial Neural Network (ANN), whose result is then visualized using a WordCloud. Textual data contains abundant qualitative information that are not easy to undergo a statistical analysis unlike quantitative data. The findings say that, for our data, the combination of Text Classification with Word2Vec provides more efficient results than using those modeling approaches individually, as it can find niche topics and associated vocabularies from the interview data. This project report provides an overview on the qualitative research, the techniques that are used to analyze our textual data for obtaining meaningful information, the limitations of those approaches and suggests some possible ways for further study.
This project is divided into two part:
-
Data Preprocessing
- Translate and transcribe the interview data into English language, as the interview data is in Gujarati and Hindi language.
- Prepare the training and interview data into tabular format to make it ready for analysis. Code : prepare_data.py
- Apply different NLP techniques like removing stopwords, POS tagging, Named Entity Recognition, Lemmatization, Stemming. Code : preprocess_data.py
-
Building the model for extracting the text.
-
Performing advanced simulations on the resulting data:
-
Using Word2Vec: Convert each and every word in the data into vector format which will then help to identify the semantic similarities between them. Following shows the plot showing the related words near to each other. Code : convert_vector.py. Jupyter Notebook : Word2Vec_in_detail.ipynb.
-
Using a Neural Network for text classification: Classify the responses based on the questions which is already been categorized into different groups and identify the codewords from each group using a Word Cloud. Code : text_classify.py . Jupyter Notebook : FastTextClassification_in_detail.ipynb. Following shows the Word Cloud related with disease from our data.

-
-
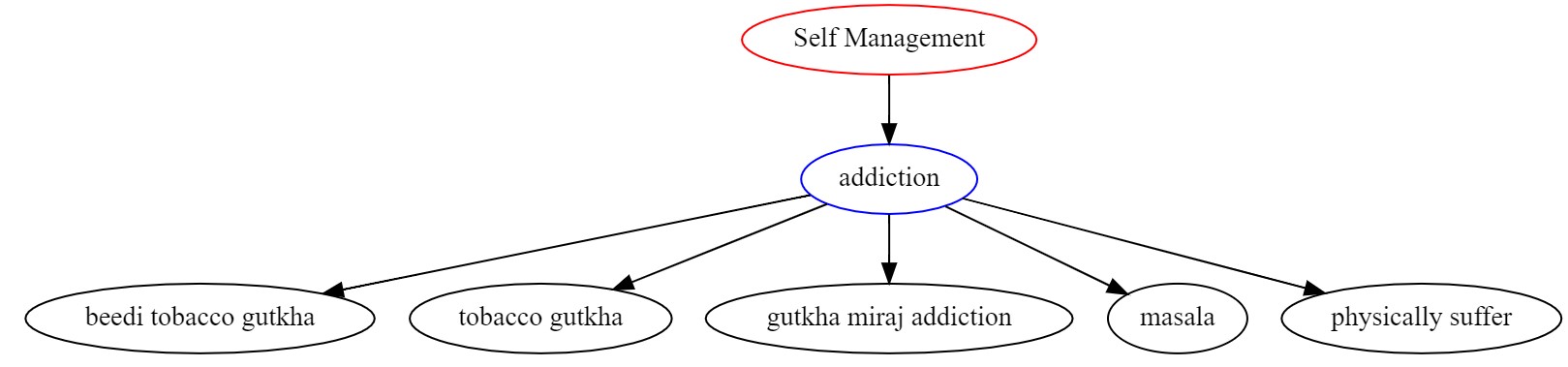
Develop connecting graphs to connect similar themes together.Compare the developed models and identify the approach that would help to define our theme “Well Being Management” well. Code: text_graph.py . Summary Graphs for each aspect of Lifestyle Management : Graphs. Following is an example graph showing the theme addiction from the data. This shows that the people were addicted to Gutkha, Beedi, Tobacco, Miraj.
-
The Code is written in Python 3.7 If you don't have Python installed you can find it here. If you are using a lower version of Python you can upgrade using the pip package, ensuring you have the latest version of pip.


