

DeepFabric is a CLI tool and SDK, that leverages large language models to generate high-quality synthetic datasets. It's designed for researchers and developers building teacher-student distillation pipelines, creating evaluation benchmarks for models and agents, or conducting research requiring diverse training data.
The key innovation lies in DeepFabric's graph and tree-based architecture, which uses structured topic nodes as generation seeds. This approach ensures the creation of datasets that are both highly diverse and domain-specific, while minimizing redundancy and duplication across generated samples.
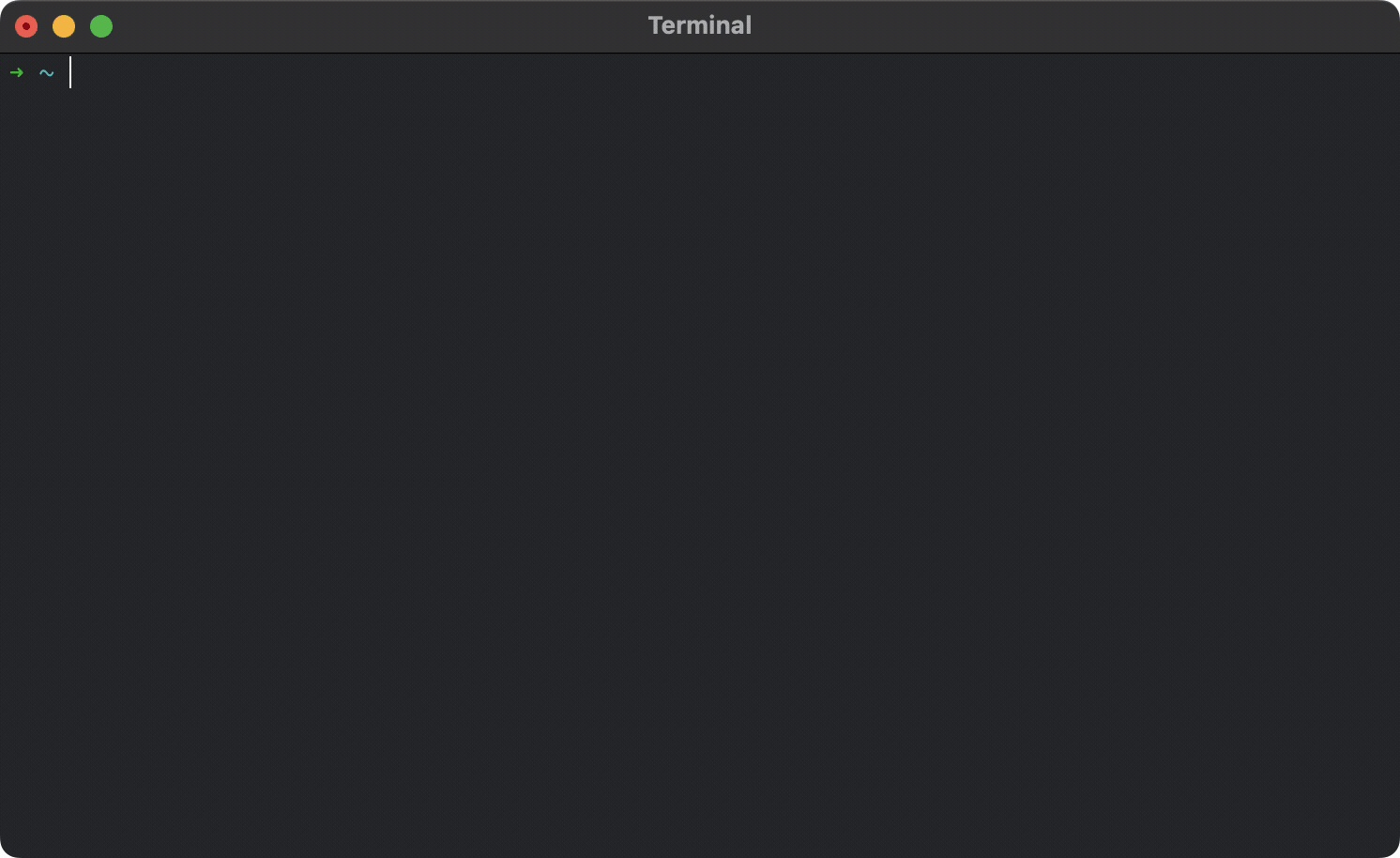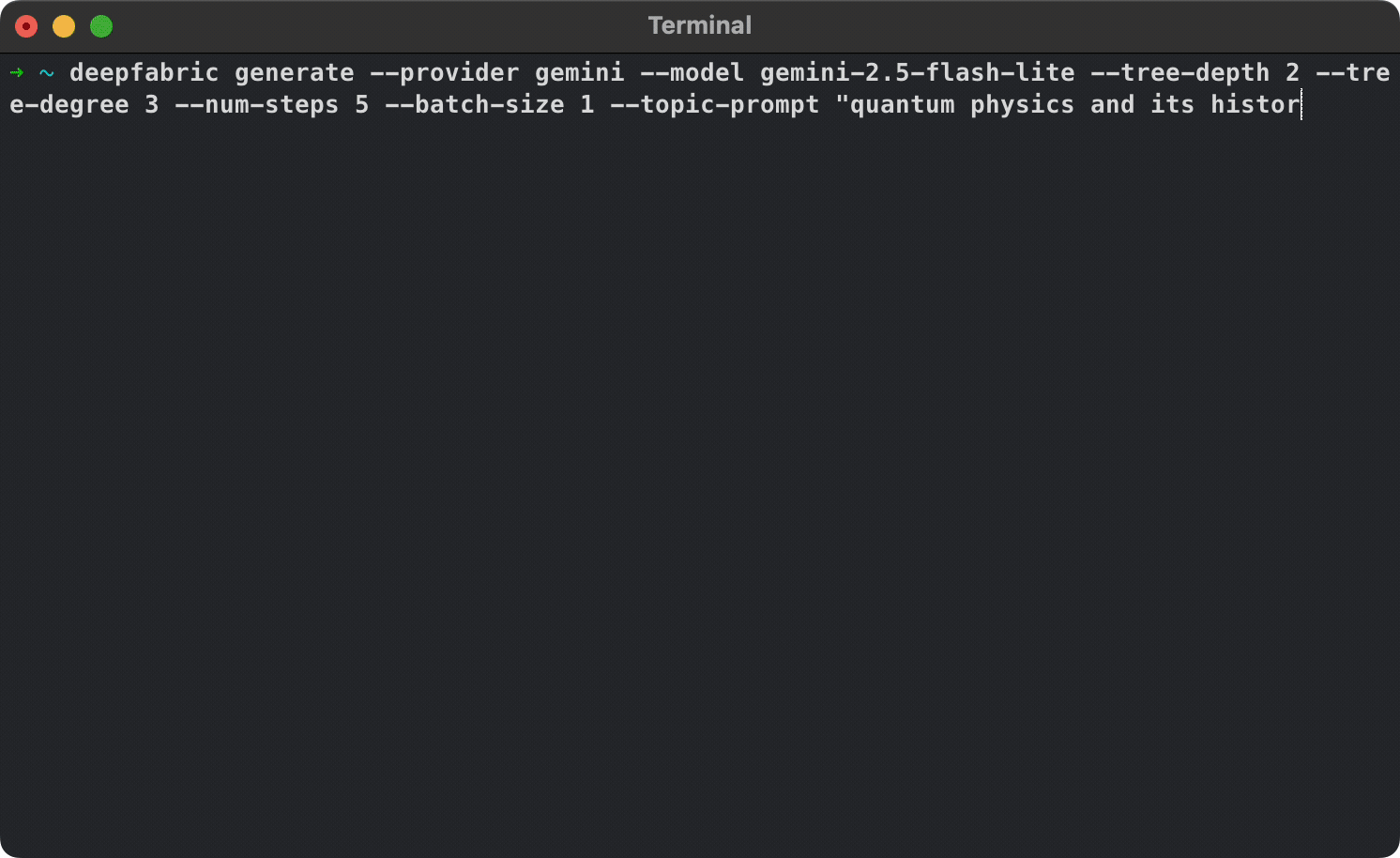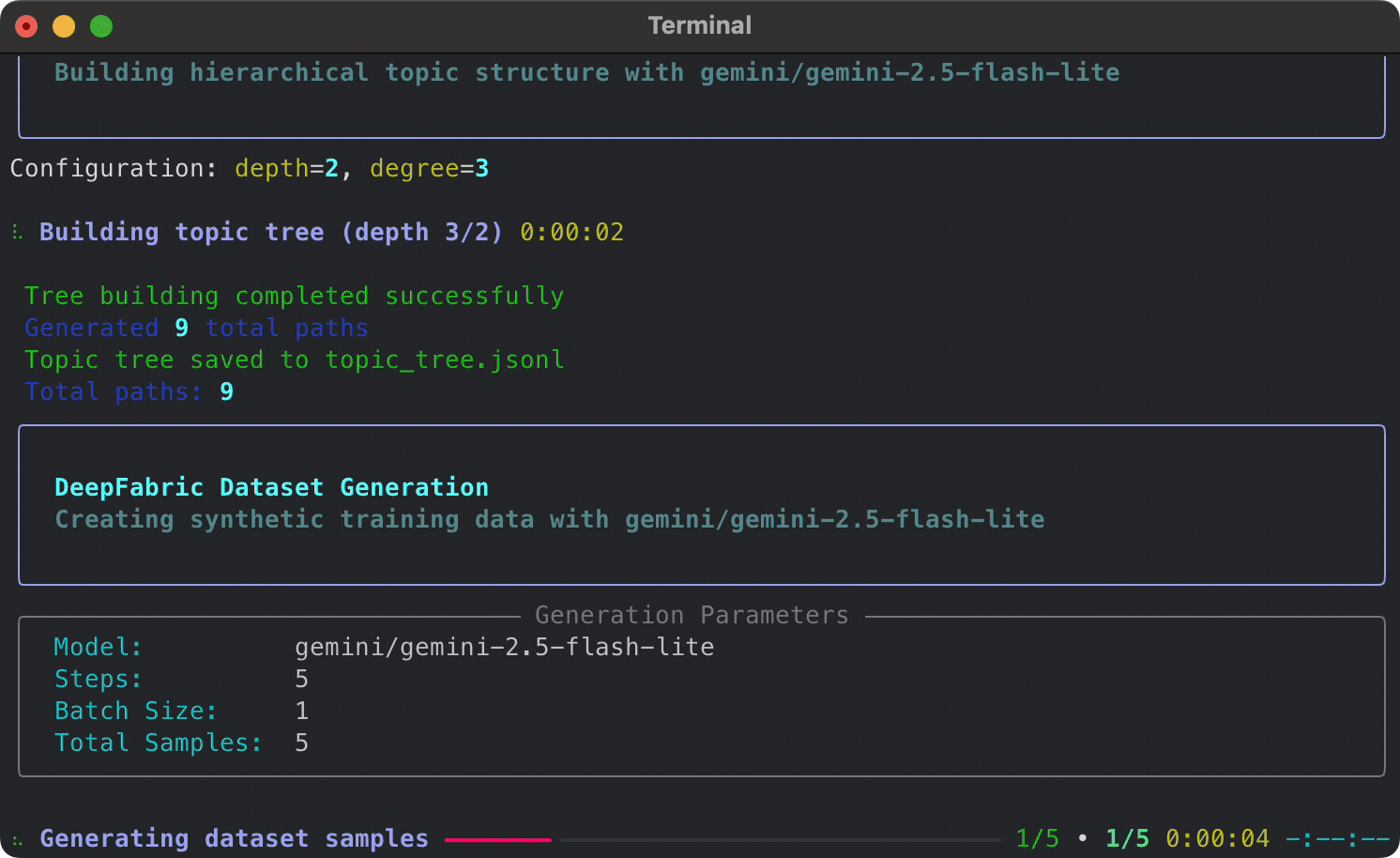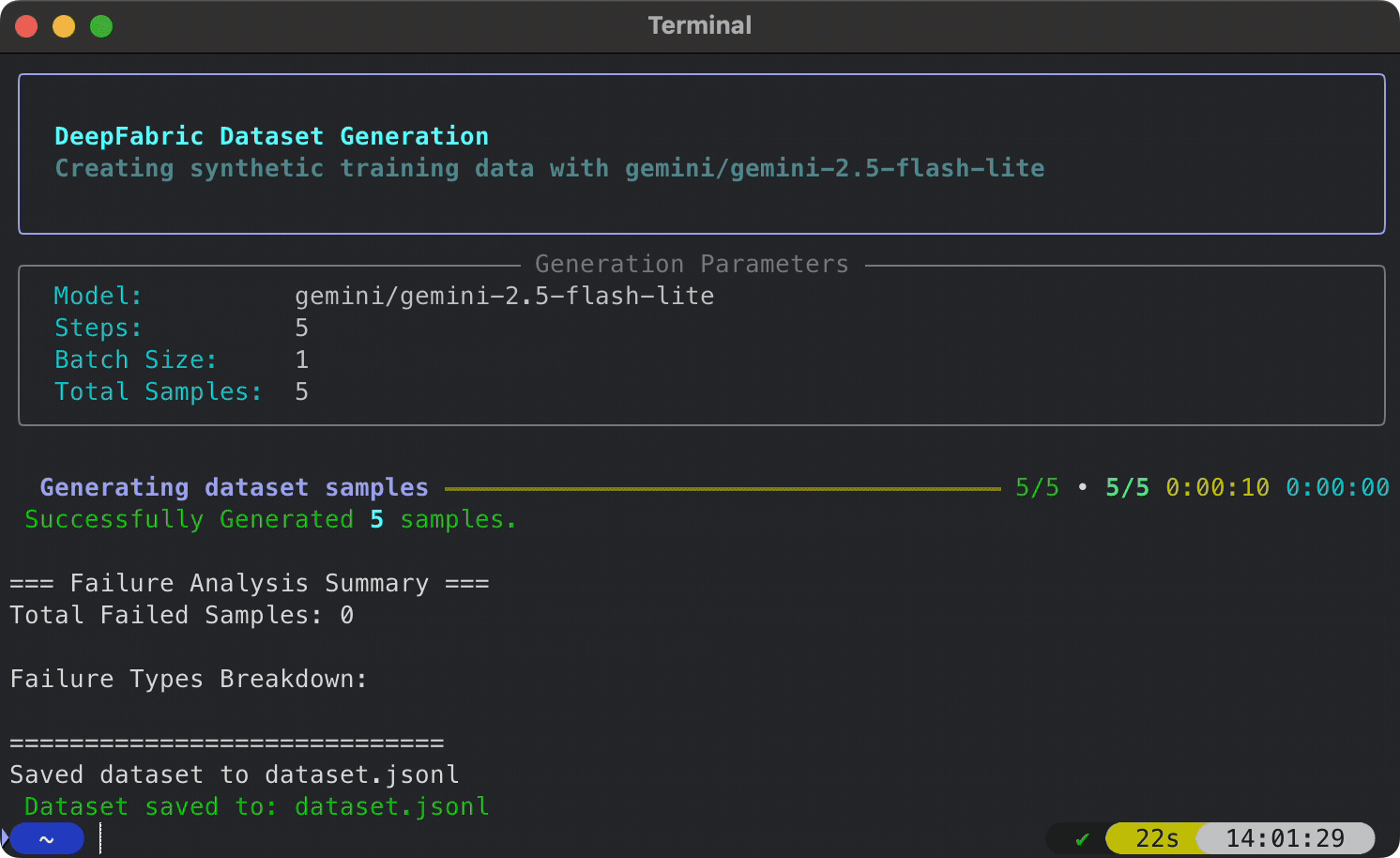
pip install deepfabric# Set your API key (or use Ollama for local generation)
export OPENAI_API_KEY="your-api-key"
# Generate a dataset with a single command
deepfabric generate \
--mode tree \
--provider openai \
--model gpt-4o \
--depth 3 \
--degree 3 \
--num-steps 9 \
--batch-size 1 \
--topic-prompt "This history Quantum physics" \
--generation-system-prompt "You are an expert on academic history, with a specialism in the sciences" \
--dataset-save-as dataset.jsonlDeepfabric will automatically:
- Generate a hierarchical topic tree (3 levels deep, 3 branches per level)
- Create 9 diverse Q&A pairs across the generated topics
- Save your dataset to
dataset.jsonl
Your dataset is ready in the OpenAI standard instruct format (JSONL):
{
"messages": [
{
"role": "user",
"content": "Can you explain Albert Einstein's contribution to quantum theory?"
},
{
"role": "assistant",
"content": "Albert Einstein made significant contributions to quantum theory, particularly through his explanation of the photoelectric effect, for which he won the Nobel Prize in 1921. He proposed that light could be thought of as discrete packets of energy called quanta or photons, which could explain how electrons are emitted from metals when exposed to light. This idea was instrumental in the development of quantum mechanics. He later became famous for his skepticism about quantum mechanics probabilistic interpretation, leading to his quote \"God does not play dice with the universe.\""
}
]
}Generate larger datasets with different models:
# With a depth of 4 and degree of 4^5 = 1,024
deepfabric generate \
--provider ollama \
--model qwen3:32b \
--depth 4 \
--degree 5 \
--num-steps 100 \
--batch-size 5 \
--topic-prompt "Machine Learning Fundamentals"
--generation-system-prompt "You are an expert on Machine Learning and its application in modern technologies" \
--dataset-save-as dataset.jsonlThere are lots more examples to get you going.
DeepFabric can generate topics using two approaches:
Topic Graphs (Experimental): DAG-based structure allowing cross-connections between topics, ideal for complex domains with interconnected concepts.
Topic Trees: Traditional hierarchical structure where each topic branches into subtopics, perfect for well-organized domains.
Leverage different LLMs for different tasks. Use GPT-4 for complex topic generation, then switch to a local model like Mixtral for bulk data creation:
topic_tree:
provider: "openai"
model: "gpt-4" # High quality for topic structure
data_engine:
provider: "ollama"
model: "mixtral" # Fast and efficient for bulk generationPush your datasets directly to Hugging Face Hub with automatic dataset cards:
deepfabric generate config.yaml --hf-repo username/my-dataset --hf-token $HF_TOKENDeepFabric uses YAML configuration files for maximum flexibility. Here's a complete example:
# Main system prompt - used as fallback throughout the pipeline
dataset_system_prompt: "You are a helpful AI assistant providing clear, educational responses."
# Topic Tree Configuration
# Generates a hierarchical topic structure using tree generation
topic_tree:
topic_prompt: "Python programming fundamentals and best practices"
# LLM Settings
provider: "ollama" # Options: openai, anthropic, gemini, ollama
model: "qwen3:0.6b" # Change to your preferred model
temperature: 0.7 # 0.0 = deterministic, 1.0 = creative
# Tree Structure
degree: 2 # Number of subtopics per node (1-10)
depth: 2 # Depth of the tree (1-5)
# Topic generation prompt (optional - uses dataset_system_prompt if not specified)
topic_system_prompt: "You are a curriculum designer creating comprehensive programming learning paths. Focus on practical concepts that beginners need to master."
# Output
save_as: "python_topics_tree.jsonl" # Where to save the generated topic tree
# Data Engine Configuration
# Generates the actual training examples
data_engine:
instructions: "Create clear programming tutorials with working code examples and explanations"
# LLM Settings (can override main provider/model)
provider: "ollama"
model: "qwen3:0.6b"
temperature: 0.3 # Lower temperature for more consistent code
max_retries: 3 # Number of retries for failed generations
# Content generation prompt
generation_system_prompt: "You are a Python programming instructor creating educational content. Provide working code examples, clear explanations, and practical applications."
# Dataset Assembly Configuration
# Controls how the final dataset is created and formatted
dataset:
creation:
num_steps: 4 # Number of training examples to generate
batch_size: 1 # Process 3 examples at a time
sys_msg: true # Include system messages in output format
# Output
save_as: "python_programming_dataset.jsonl"
# Optional Hugging Face Hub configuration
huggingface:
# Repository in format "username/dataset-name"
repository: "your-username/your-dataset-name"
# Token can also be provided via HF_TOKEN environment variable or --hf-token CLI option
token: "your-hf-token"
# Additional tags for the dataset (optional)
# "deepfabric" and "synthetic" tags are added automatically
tags:
- "deepfabric-generated-dataset"
- "geography"Run using the CLI:
deepfabric generate config.yamlThe CLI supports various options to override configuration values:
deepfabric generate config.yaml \
--save-tree output_tree.jsonl \
--dataset-save-as output_dataset.jsonl \
--model-name ollama/qwen3:8b \
--temperature 0.8 \
--degree 4 \
--depth 3 \
--num-steps 10 \
--batch-size 2 \
--sys-msg true \ # Control system message inclusion (default: true)
--hf-repo username/dataset-name \
--hf-token your-token \
--hf-tags tag1 --hf-tags tag2DeepFabric supports serveral providers. Here are the most common:
OpenAI
provider: "openai"
model: "gpt-4-turbo-preview"
# Set: export OPENAI_API_KEY="your-key"Anthropic
provider: "anthropic"
model: "claude-3-opus-20240229"
# Set: export ANTHROPIC_API_KEY="your-key"provider: "gemini"
model: "gemini-pro"
# Set: export GEMINI_API_KEY="your-key"Ollama (Local)
provider: "ollama"
model: "qwen3:8b:latest"
# No API key neededFor more details, including how to use the SDK, see the docs!
There are also lots of examples to get you going.
Deepfabric development is moving at a fast pace 🏃♂️, for a great way to follow the project and to be instantly notified of new releases, Star the repo.

Deepfabric currently outputs to Open AI chat format, we will provide a system where you can easily plug in a post-processing conversion to whatever format is needed. This should allow easy adaption to what ever you need within a training pipeline:
formatters:
- name: "alpaca"
template: "builtin://alpaca.py"
- name: "custom"
template: "file://./my_format.py"
config:
instruction_field: "query"We will be introducing, multi-turn, reasoning, chain-of-thought etc.
Push to Kaggel
We use fully anonymised analytics, to help use improve application performance and stablity. We never send personal indentifiable information.
The analytics only captures:
- Model names and providers (e.g., "ollama", "gpt-4")
- Numeric parameters (temperature, depth, degree, batch_size)
- Success/failure rates
- Timing metrics
But never:
- Prompts
- Generated content
- File paths (only hashed versions)
- API keys, Tokens etc
- Any user data or content
Should you wish to opt-out, just set ANONYMIZED_TELEMETRY=False.