![]()
Review GitHub Pull Requests or GitLab Merge Requests using Ollama.

🔍 Overview • 💻 Usage • 📖 FAQ • 🔧 Installation
This is a Chrome extension which reviews Pull Requests for you using Ollama.
Here's an example output for this Pull Request:
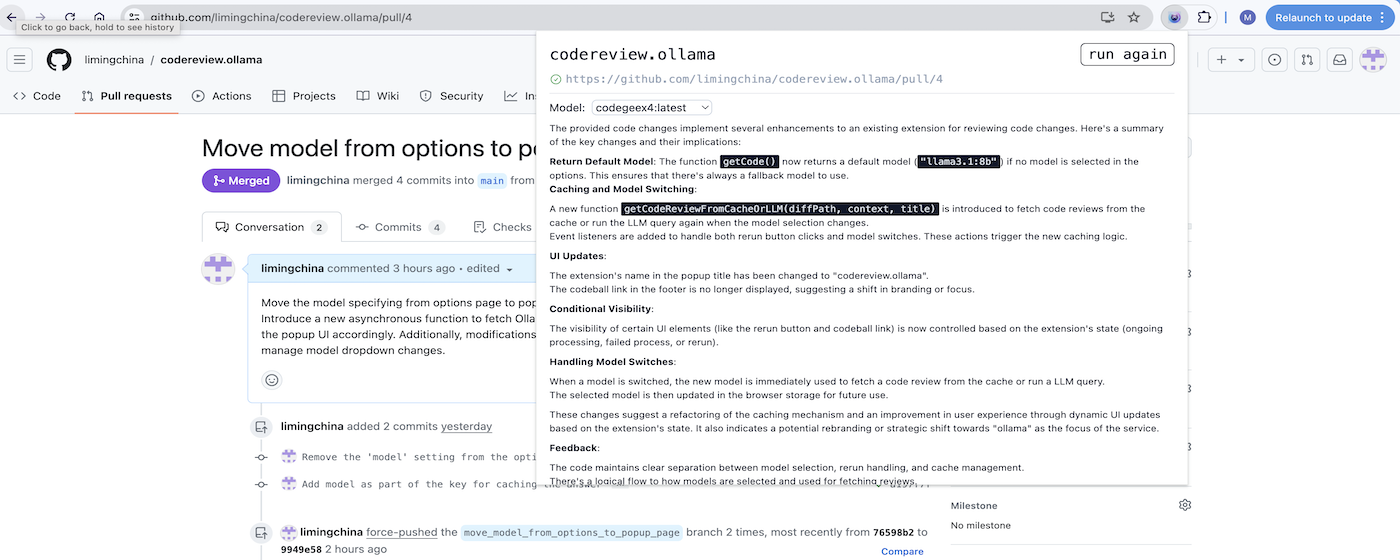
2025 June 9th:
- Add options to override LLM sampling parameters: temperature, top_p, top_k, max_tokens.
2025 April 12th:
- Add support for LM Studio
- Add a button in the popup page to copy the prompt messsage so that it can be pasted to another AI chat app.
- Add management of user-defined code review guidelines, one can customzie in the options page.
- Install Ollama
- In order to call the REST API from Ollama running locally, one needs to enable CORS following the instructions here to set the environment variable
OLLAMA_ORIGIN. - If one wants to use the Ollama server in a remote location, one needs to configure the Ollama server with the environment variable
OLLAMA_HOST=0.0.0.0on the remote machine. Refer to (https://chatboxai.app/help-center/connect-chatbox-remote-ollama-service-guide) - Install some models using 'ollama pull'. For example, 'ollama pull llama3.1:8b'. One can pull multiple models.
- Go to a Github Pull Request web page or a Gitlab Merge Request web page, and click the extension icon. In the first run, the first listed model will be used for performing the code review. One can change to use another model by choosing from the dropdown list.
- The review comment from Ollama are shown in the popup window. The result will be cached based on the Pull(Merge) Request URL and the selected model. If you go to the same URL later and use the same model, the result will be fetched from the cache. One can also click the "run again" button to re-run the review. The new review result will replace the cached result.
- Install LM Studio
- Launch LM Studio and download some models.
- Switch to "Developer" mode in the status bar. Click "Developer" icon on the left side bar. Then click on "Settings" button and switch on the "Enable CORS" option.
The server addresses for Ollama and LM Studio can be specified in the options page. The default values are as follows:
- Ollama:
http://localhost:11434 - LM Studio:
http://localhost:1234Since for LM studio, the request is using OpenAI-compatible API, the other OpenAI-compatible backends would also work, for example, the mlx_lm server. Note that the mlx_lm server's default max_tokens parameter is 512, which is too short. One needs to override that in the "Generation Parameters" in the options page.
Apart from "max_tokens", one can also customize other LLM sampling parameters in the "Generation Parameters" in the options page. "temperature" and "top_p" are the most important parameters. "temperature" controls the randomness of the generated text, while "top_p" controls the diversity of the generated text. "top_k" controls the number of tokens to consider for sampling. "max_tokens" controls the maximum number of tokens to generate. "min_p" is not supported since it is not supported by OpenAI API and LM Studio API.
Sometimes one might want to customize the code review guidelines instead of using the builtin one. For example, you just want the code review to concentrate on finding typos or naming conventions. You can add such guidelines by following these steps:
- Go to the "Code Review Guidelines" section of the options page and click on the "Add" button.
- Enter the guideline's name and content.
- Click the "Save" button to save the guideline.
NB: Running the review multiple times often produces different feedback, so if you are dealing with a larger PR, it might be a good idea to do that to get the most out of it.
Q: Are the reviews 100% trustworthy?
A: No. This tool can help you spot bugs, but as with anything, use your judgement. Sometimes it hallucinates things that sound plausible but are false — in this case, re-run the review.
Q: What aspects of the Pull Request or Merge Request are considered during the review?
A: The model gets the code changes and the commit messages in a patch format. Additionally it pulls in the description of the MR/PR.
Q: Does the extension post comments on the Pull Request page?
A: No. If you want any of the feedback as PR comments, you can copy paste the output.
Q: Why would you want this?
A: Plenty of reasons! You can:
- pretend to work while playing games instead
- appear smart to your colleagues
- enable a future skynet
- actually catch some bugs you missed
- learn a thing or 2 on best practices
You can install codereview.ollama build it from source locally.
- Clone this repository
- Install the dependencies
npm install - Run the build script
npm run build - Navigate to
chrome://extensions - Enable Developer Mode
- Click the 'Load unpacked' button and navigate to the
builddirectory in the project
only Chrome is supported
- Add support to follow up the conversion in the popup window
This is a list of permissions the extension uses with the respective reason.
activeTabis used to get the URL or the active tab. This is needed to fetch the get the Pull Request detailsstorageis used to cache the responses from OpenAIscriptingis used to fetch html content from the Merge Request / Pull Request
This project is forked from codereview.gpt
codereview.ollama is distributed under the MIT license.