Zalando is a multinational e-commerce platform selling fashion goods in many European countries. It released a Fashion MNIST dataset – a set of (60,000 train + 10,000 test, stored in fashion-mnist_train.zip and fashion-mnist_test.zip) images of 10 types of clothes.
In this code I create neural network with few hidden layers to classify images in Fashion MNIST dataset. Then I “Play” with the number of the hidden layers and size of each layer. For each case, I measure:
i. The total number of network parameters.
ii. The network accuracy on the training and validation set (for each batch).
iii. Training and inference times.
What can we learn from these experiments? Can they help as choose the best model? I use some plots to make my arguments easier to convey.
Then I test performance of the model in the test set, and add confusion matrix.
Summary:
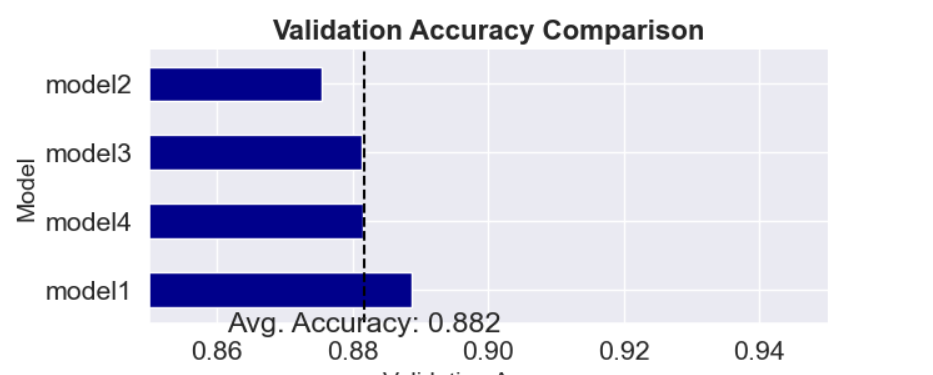
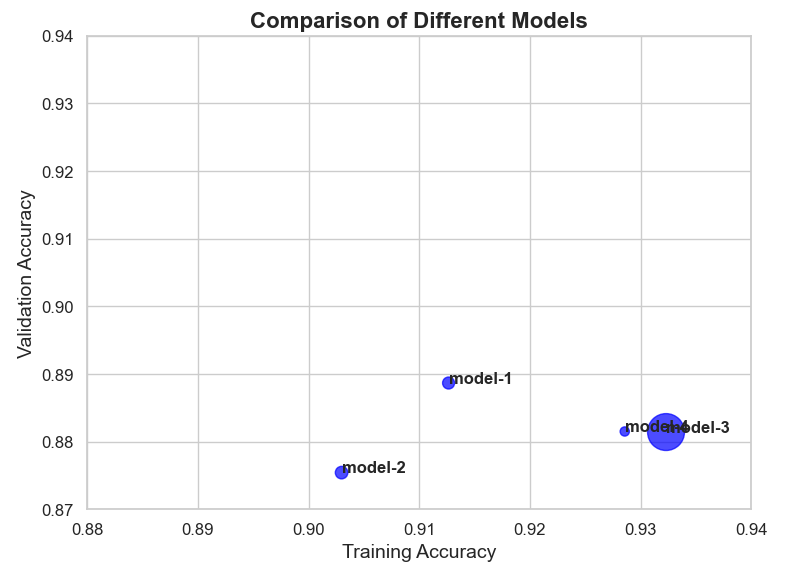

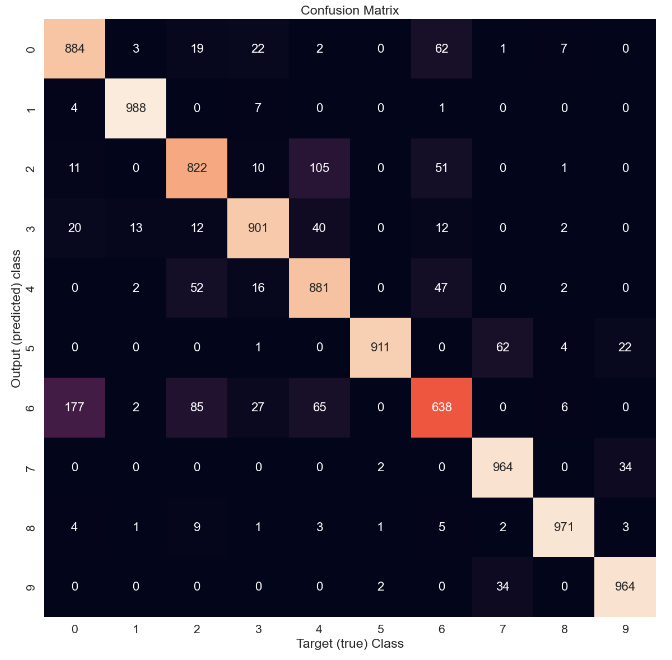
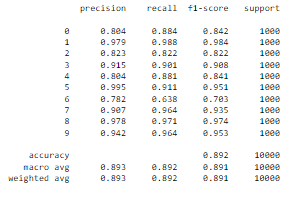
As we can see the f1-score is muh lower for Tshirts, shirts, coats, and pullovers. The same thing we saw using tsne. This only further strengthens our claim that the boundaries are blurred, and it is more difficult for the model to differentiate between these products. Even looking on the predicted pictures, it's little bit hard to distinguesh between them. The cause of course is because there is a high degree of similarity between them ( similar shapes and textures, which can make it difficult for the model to accurately distinguish between them ). So, the model_1 itself, performing well overall but as it can be seen it's struggling with specific classes. How could I prevent those problems in the feature? Well, first we can add additional feateres to the pictures, such as material and maybe style ( at the end it can be translated as 1,0 the same as picture).