![]()
LLMService does one thing well - manage LLM invocations with production concerns (clean code separation, rate limits, costs, retries, extensive logging, postprocessing, scalable architecture).
A clean, production-ready service layer that centralizes prompts, invocations, and post-processing, ensuring rate-aware, maintainable, and scalable LLM logic in your application.
| Package |   |
Install LLMService via pip:
pip install llmservice- Installation
- What makes it unique?
- Main Features
- Architecture
- Usage
- Postprocessing Pipeline
- Async support
| Feature | LLMService | LangChain |
|---|---|---|
| Result Handling | Returns a single GenerationResult dataclass encapsulating success/failure, rich metadata (tokens, cost, latency), and pipeline outcomes |
Composes chains of tools and agents; success/failure handling is dispersed via callbacks and exceptions |
| Rate-Limit & Throughput Control | Built-in sliding-window RPM/TPM counters and an adjustable semaphore for concurrency, automatically pausing when you hit your API quota | Relies on external throttlers or underlying client logic; no native RPM/TPM management |
| Cost Monitoring | Automatic per-model token-level cost calculation and aggregated usage stats for real-time billing insights | No built-in cost monitoring—you must implement your own wrappers or middleware |
| Post-Processing Pipelines | Declarative configs for JSON parsing, semantic extraction, validation, and transformation without ad-hoc parsing code | Encourages embedding output parsers inside chains or writing ad-hoc post-chain functions, scattering parsing logic |
| Dependencies | Minimal footprint: only Tenacity, your LLM client, and optionally YAML for prompts | Broad ecosystem: agents, retrievers, vector stores, callback managers, and other heavy dependencies |
| Extensibility | Provides a clear BaseLLMService subclassing interface so you encapsulate each business operation and never call the engine directly |
You wire together chains or agents at call-site, mixing business logic with prompt orchestration |
LLMService delivers a well-structured alternative to more monolithic frameworks like LangChain.
"LangChain isn't a library, it's a collection of demos held together by duct tape, fstrings, and prayers."
-
Minimal Footprint & Low Coupling
Designed for dependency injection—your application code never needs to know about LLM logic. -
Result Monad Pattern
Returns aGenerationResultdataclass for every invocation, encapsulating success/failure status, raw and processed outputs, error details, retry information, and per-step results—giving you full control over custom workflows. -
Declarative Post-Processing Pipelines
Chain semantic extraction, JSON parsing, string validation, and more via simple, declarative configurations. -
Rate-Limit-Aware Asynchronous Requests
Dynamically queue and scale workers based on real-time RPM/TPM metrics to maximize throughput without exceeding API quotas. -
Transparent Cost & Usage Monitoring
Automatically track input/output tokens and compute per-model cost, exposing detailed metadata with each response. -
Automated Retry & Exponential Backoff
Handle transient errors (rate limits, network hiccups) with configurable retries and exponential backoff powered by Tenacity. -
Custom Exception Handling
Provide clear, operation-specific fallbacks (e.g., insufficient quota, unsupported region) for graceful degradation.
LLMService provides an abstract BaseLLMService class to guide users in implementing their own service layers. It includes llmhandlerwhich manages interactions with different LLM providers and generation_engine which handles the process of prompt crafting, LLM invocation, and post-processing
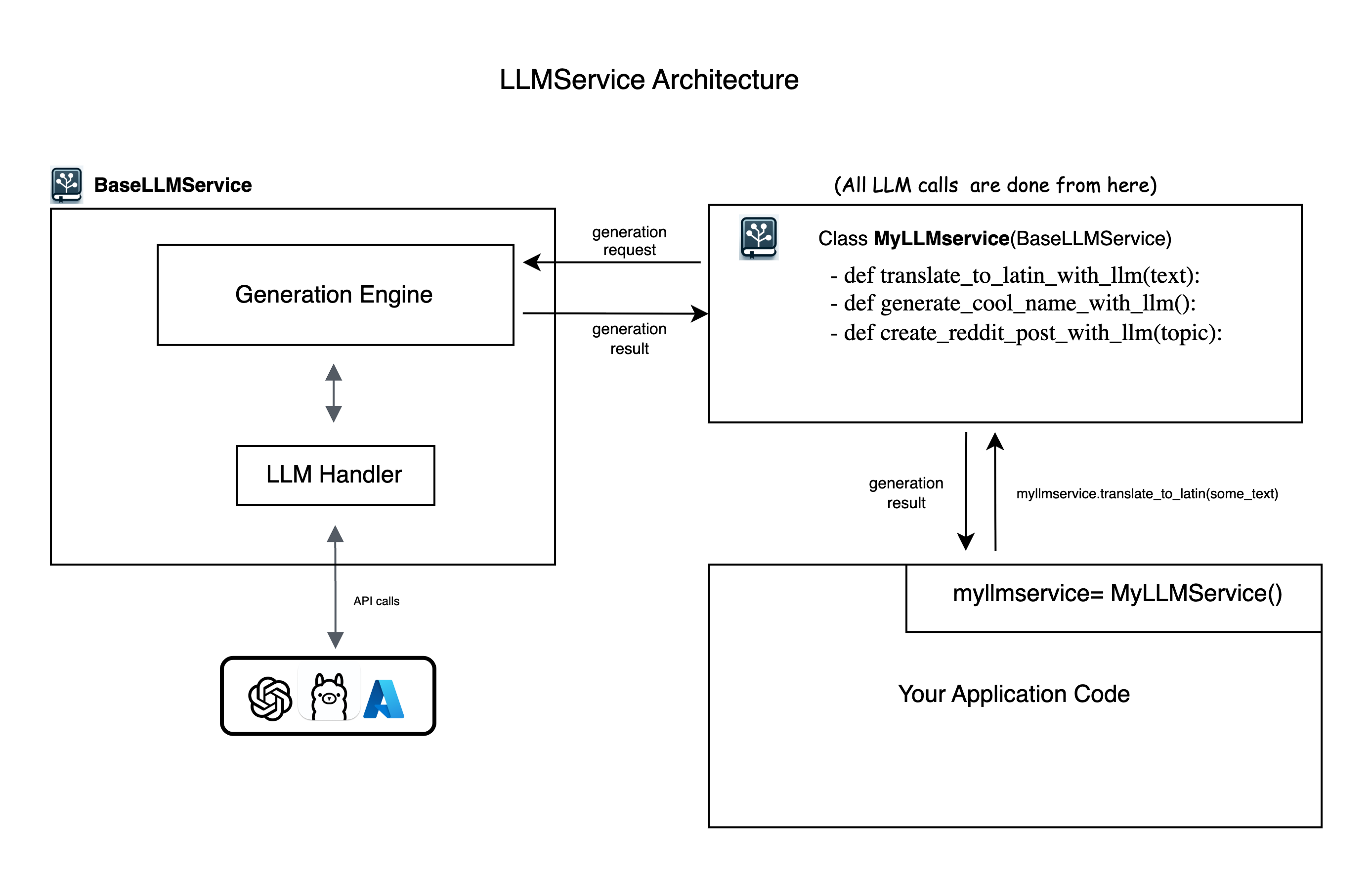
-
Put your
OPENAI_API_KEYinside.envfile -
Install LLMService via pip:
pip install llmserviceCreate a new Python file (e.g., myllmservice.py) and extend the BaseLLMService class. And all llm using logic of your business logic will be defined here as methods.
from llmservice import BaseLLMService
class MyLLMService(BaseLLMService):
def translate_to_latin(self, input_paragraph: str) -> GenerationResult:
my_prompt=f"translate this text to latin {input_paragraph}"
generation_request = GenerationRequest(
formatted_prompt=my_prompt,
model="gpt-4.1-nano",
)
# Execute the generation synchronously
generation_result = self.execute_generation(generation_request)
return generation_result# in your app code anywhere you need to run LLM logic
from myllmservice import MyLLMService
if __name__ == '__main__':
service = MyLLMService()
result = service.translate_to_latin("Hello, how are you?")
print(result)
# in this case the result will be a generation_result object which inludes all the information you need.
# to get the result text you can print result.contentBelow is the structure of the GenerationResult dataclass. While the .content field provides the direct LLM response, advanced applications—especially those with high LLM throughput—will benefit from leveraging the full set of metadata, including timing, usage, retry logic, and error diagnostics.
@dataclass
class GenerationResult:
success: bool
trace_id: str
request_id: Optional[Union[str, int]] = None
content: Optional[Any] = None
raw_content: Optional[str] = None # Store initial LLM output
retried: Optional[Any] = None,
attempt_count: Optional[Any] = None,
operation_name: Optional[str] = None
usage: Dict[str, Any] = field(default_factory=dict)
elapsed_time: Optional[float] = None
error_message: Optional[str] = None
model: Optional[str] = None
formatted_prompt: Optional[str] = None
unformatted_prompt: Optional[str] = None
response_type: Optional[str] = None
pipeline_steps_results: List[PipelineStepResult] = field(default_factory=list)
# rpm tpm related logs
rpm_at_the_beginning: Optional[int] = None
rpm_at_the_end: Optional[int] = None
tpm_at_the_beginning: Optional[int] = None
tpm_at_the_end: Optional[int] = None
rpm_waited: Optional[bool] = None
rpm_wait_loops: Optional[int] = None
rpm_waited_ms: Optional[int] = None
tpm_waited: Optional[bool] = None
tpm_wait_loops: Optional[int] = None
tpm_waited_ms: Optional[int] = None
total_invoke_duration_ms: Optional[Any] = None,
total_backoff_ms: Optional[Any] = None,
backoff: BackoffStats = field(default_factory=BackoffStats)
# detailed timestamp logs requested_at, enqueued_at...
timestamps: Optional[EventTimestamps] = None
# complete copy of the generation_request
generation_request: Optional[GenerationRequest] = NoneBeyond res.content, you can pull:
- Success flag:
if not res.success: print("LLM call failed:", res.error_message)
-
Token and cost breakdown:
print("Input tokens:", res.usage["input_tokens"]) print("Output tokens:", res.usage["output_tokens"]) print("Total cost (USD):", res.usage["total_cost"])
-
Latency and backoff info:
print("LLM round-trip (ms):", res.total_invoke_duration_ms) print("Client backoff (ms):", res.total_backoff_ms)
-
Rate-limit / concurrency stats:
print("RPM at start:", res.rpm_at_the_beginning) print("RPM at end: ", res.rpm_at_the_end) print("Did RPM block?:", res.rpm_waited, "| loops:", res.rpm_wait_loops)
-
Pipeline step details (if you used a pipeline):
for step in res.pipeline_steps_results: print(f"{step.step_type} → success? {step.success}.")
LLMService includes five native post-processing methods (only three are illustrated here). These built-in steps cover the most common transformations and are supported out of the box.
Use the SemanticIsolator step whenever you need to extract a specific semantic element (for example, a code snippet, a name, or any targeted fragment) from an LLM’s output.
For example, imagine you asked LLM to write you a SQL snippet and it returns:
Here is your answer:
SELECT * FROM users;
Do you need anything else?
For example If you plan to use the LLM output directly in your database connection, any extra text like “Here is your answer:” will break SQL execution. In scenarios where you only need the raw semantic element (such as a SQL query) this post-processing step becomes essential.
Here is sample usage for above example:
# in your myllmservice
def create_sql_code(self, user_question: str, database_desc,) -> GenerationResult:
formatted_prompt = f"""Here is my database description: {database_desc},
and here is what the user wants to learn: {user_question}.
I want you to generate a SQL query. answer should contain only SQL code."""
pipeline_config = [
{
'type': 'SemanticIsolation',
'params': {
'semantic_element_for_extraction': 'SQL code'
}
}
]
generation_request = GenerationRequest(
formatted_prompt=formatted_prompt,
model="gpt-4o",
pipeline_config=pipeline_config,
)
generation_result = self.execute_generation(generation_request)
return generation_resultThe SemanticIsolator postprocessing step fixes this by running a second query that extracts only the semantic element you provided (in this case SQL code).
When you ask an LLM to output a JSON-like response, you typically convert it into a dictionary (for example, using json.loads()). However, if the output is missing quotes or otherwise isn’t strictly valid JSON, json.loads() will fail.
ConvertToDict pipeline leverages the string2dict module to handle these edge cases—even with missing quotes or minor formatting issues, it can parse the string into a proper Python dict.
Below are some LLM outputs where json.loads() fails but ConvertToDict succeeds:
sample_1:
'{\n "key": "SELECT DATE_FORMAT(bills.bill_date, \'%Y-%m\') AS month, SUM(bills.total) AS total_spending FROM bills WHERE YEAR(bills.bill_date) = 2023 GROUP BY DATE_FORMAT(bills.bill_date, \'%Y-%m\') ORDER BY month;"\n}'
sample_2:
"{\n 'key': 'SELECT DATE_FORMAT(bill_date, \\'%Y-%m\\') AS month, SUM(total) AS total_spendings FROM bills WHERE YEAR(bill_date) = 2023 GROUP BY month ORDER BY month;'\n}"
sample_3:
'{ \'key\': "https://dfasdfasfer.vercel.app/"}'
Usage :
pipeline_config = [
{
'type': 'ConvertToDict',
'params': {}
}
]Use this pipeline step with the ConvertToDict method to extract a single field from a JSON-like response. Simply specify the field name as a parameter.
For example, if your LLM returns:
{"answer": "<LLM-generated answer>"}add the following to your pipeline config:
{
'type': 'ExtractValue',
'params': {'key': 'answer'}
}
This configuration first ensures the output is parsed into a Python dict, then automatically returns the value associated with "answer".
A common scenario is to chain multiple pipeline steps to extract a specific value from an LLM response:
- SemanticIsolation
Extracts the JSON-like snippet from a larger text response. - ConvertToDict
Normalizes that snippet into a Pythondict, even if it isn’t strictly valid JSON. - ExtractValue
Retrieves the value associated with a given key from the dictionary.
pipeline_config = [
{
'type': 'SemanticIsolation',
'params': { 'semantic_element_for_extraction': 'SQL code' }
},
{
'type': 'ConvertToDict',
'params': {}
},
{
'type': 'ExtractValue',
'params': {'key': 'answer'}
}
]
LLMService includes first-class asynchronous methods, with built-in rate and concurrency controls. You can configure max_rpm max_tpm and max_concurrent_requests (which indirectly governs TPM over the same window). Here’s an example for your myllmservice.py:
class MyLLMService(BaseLLMService):
def __init__(self):
super().__init__(default_model_name="gpt-4o-mini")
self.set_rate_limits(max_rpm=120, max_tpm=10_000)
self.set_concurrency(100)
async def translate_to_latin_async(self, input_paragraph: str) -> GenerationResult:
my_prompt=f"translate this to to latin {input_paragraph}"
generation_request = GenerationRequest(
formatted_prompt=my_prompt,
model="gpt-4o-mini",
operation_name="translate_to_latin",
)
generation_result = await self.execute_generation_async(generation_request)
return generation_result
For this experiement we are using a text which is already chunked into pieces
| Model Name | Method | Max Concurrency | Max RPM | Max TPM | Elapsed Time | Total Cost |
|---|---|---|---|---|---|---|
| gpt4o-mini | synch | – | – | – | ||
| gpt4o-mini | asynch | 10 | 100 | 10000 | ||
| gpt4o-mini | asynch | 50 | 100 | 10000 | ||
| gpt4o-mini | asynch | 100 | 150 | 20000 | ||
| gpt4o-mini | asynch | 200 | 300 | 30000 | ||
| gpt4o | synch | - | ||||
| gpt4o | asynch | |||||
| gpt4.1-nano | synch | |||||
| gpt4.1-nano | asynch |