SNS 원문 텍스트를 고양이와 강아지의 다양한 감정으로 변환하여 자연어 처리 모델 학습용 데이터를 증강하는 프로젝트입니다.
이 프로젝트는 Google Gemini API를 활용하여 일반적인 SNS 텍스트를 동물(고양이, 강아지)의 특성과 6가지 감정 상태를 반영한 텍스트로 변환합니다. 미야옹 자체모델 파인튜닝을 위한 총 17,596개의 증강된 데이터셋을 구축했습니다.
- 자연어 처리 모델의 성능 향상을 위한 데이터 다양성 확보
- 동물 말투와 감정 표현의 체계적인 데이터 구축
- 균형 잡힌 감정 분포를 가진 대규모 데이터셋 생성
- 총 원문 데이터: 2,604개
- 총 증강 데이터: 20,582개
- 데이터 증강 비율: 7.9배
- 최종 고품질 데이터셋: 17,596개
| 파일명 | 타입 | 데이터 수 | 평균 길이 | 설명 |
|---|---|---|---|---|
증강_데이터17000개(22일업데이트).jsonl |
증강된 데이터 | 17,596개 | 29.6자 | 🎯 최종 메인 데이터셋 |
0615미야옹_합성_데이터.jsonl |
증강된 데이터 | 2,986개 | 33.1자 | 초기 버전 데이터 |
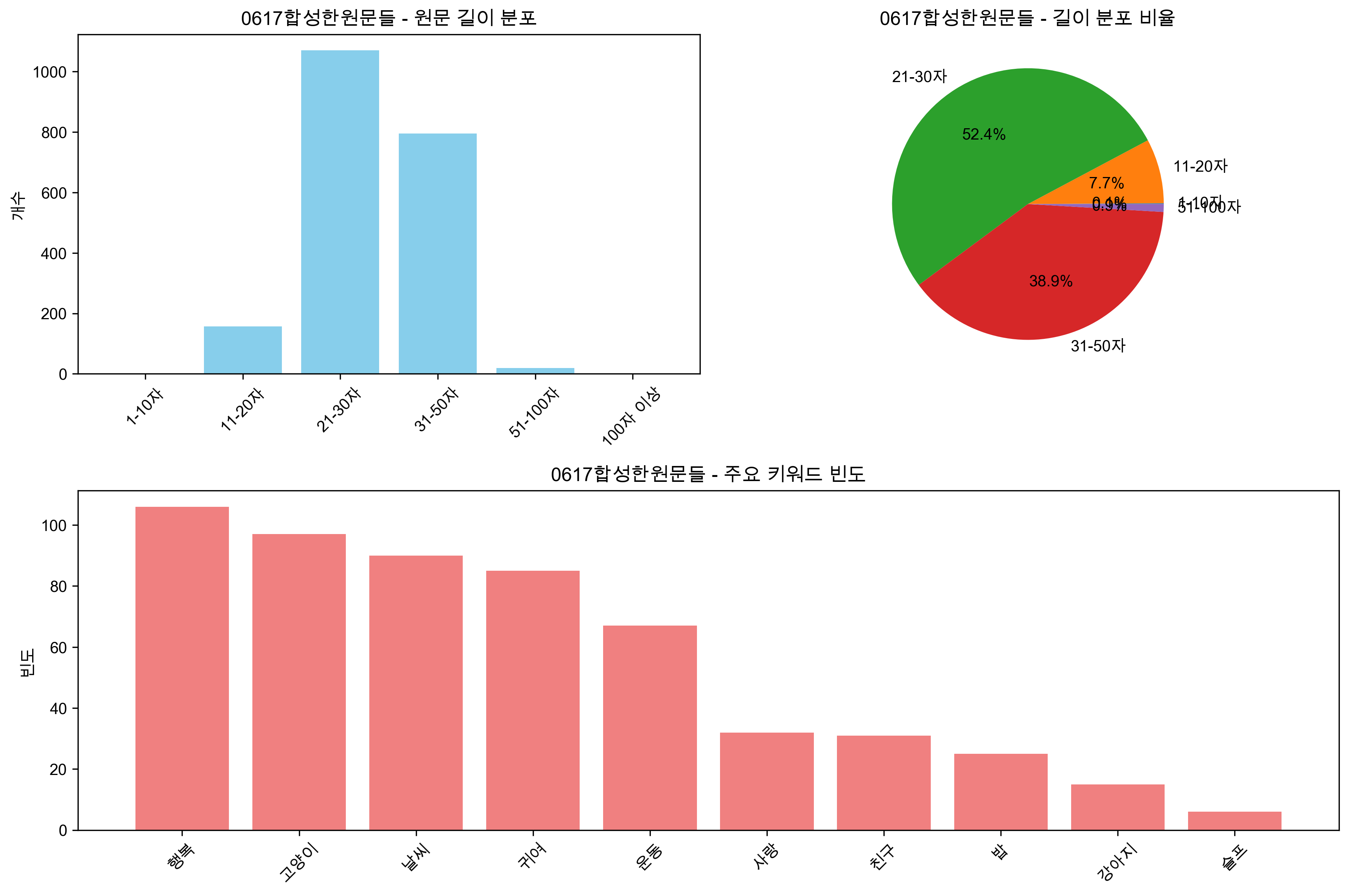
0617합성한원문들.jsonl |
원문 데이터 | 2,043개 | 29.4자 | AI 생성 원문 모음 |
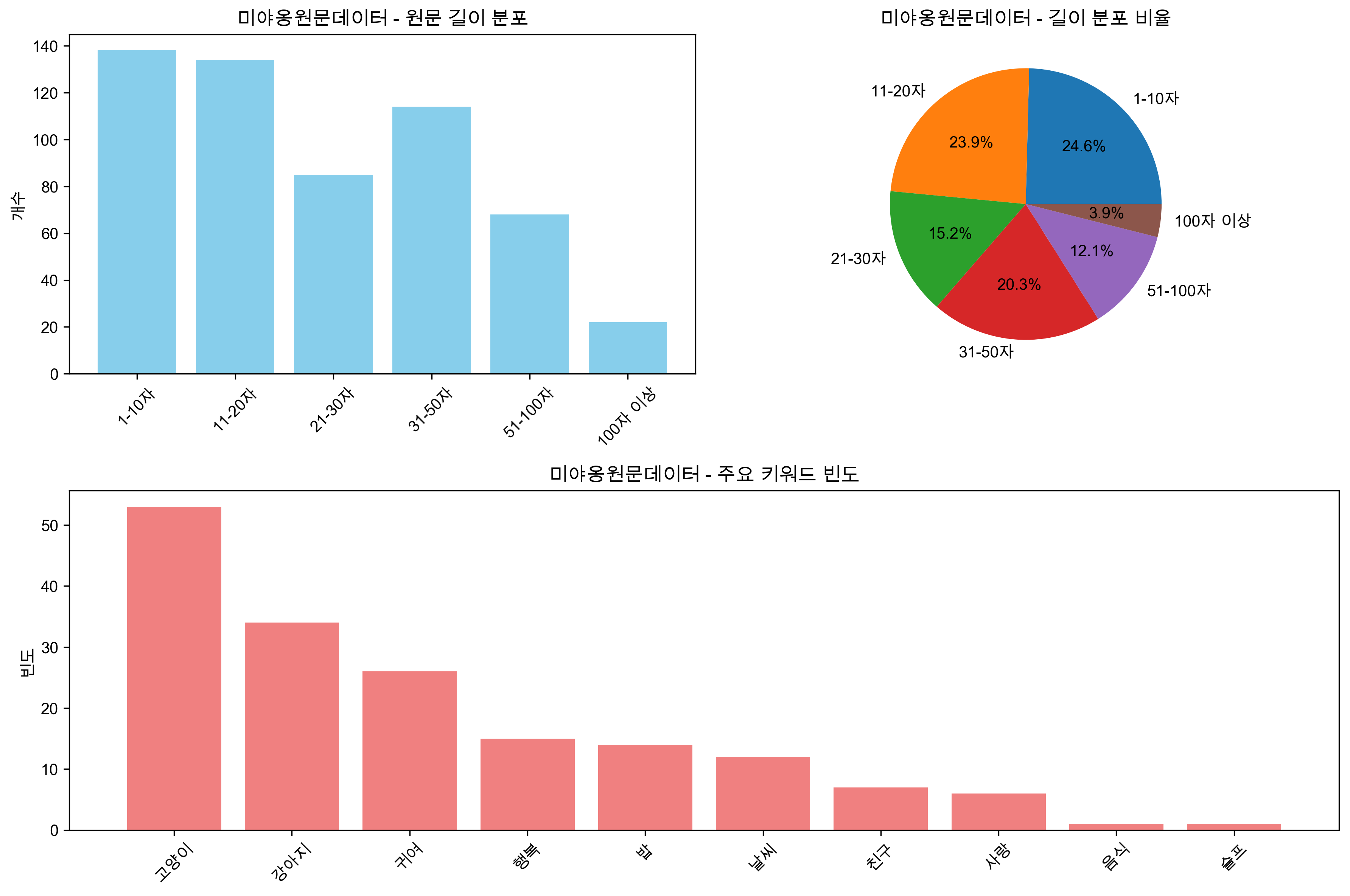
미야옹원문데이터_최종.jsonl |
원문 데이터 | 561개 | 30.8자 | 기본 원문 데이터 |
- 고양이(Cat): 8,808개 (50.06%)
- 강아지(Dog): 8,788개 (49.94%)
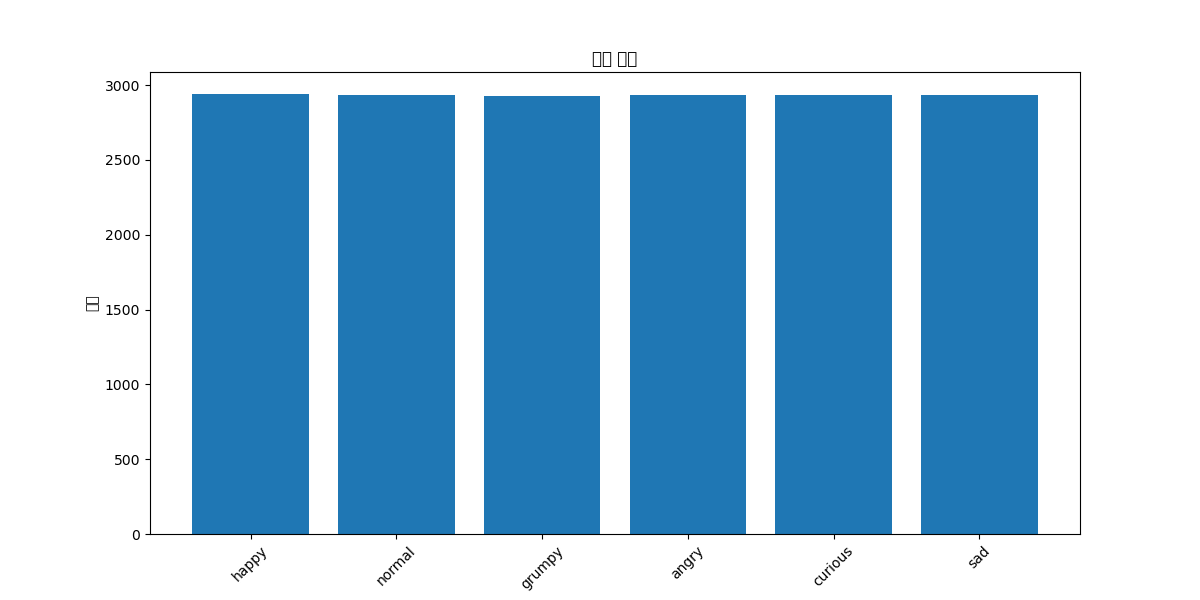
- Happy: 2,941개 (16.71%)
- Normal: 2,932개 (16.66%)
- Grumpy: 2,928개 (16.64%)
- Angry: 2,932개 (16.66%)
- Curious: 2,931개 (16.66%)
- Sad: 2,932개 (16.66%)





데이터증강/
├── data_augmention/ # 데이터 증강 핵심 모듈
│ ├── 미야옹_데이터_합성자동화.py # 메인 데이터 변환 엔진
│ ├── 원문_자동_생성.py # 원문 자동 생성기
│ ├── 인스타원문별2개감정합성자동화.py # 인스타 데이터 처리
│ ├── 크롤링텍스트필터링.py # 텍스트 품질 필터링
│ ├── 데이터_감정_분포파악.py # 데이터 분포 분석 도구
│ └── lsonl형식통일.py # JSON/JSONL 형식 변환
├── 데이터/ # 데이터 저장소
│ ├── 증강_데이터17000개(22일업데이트).jsonl # 🎯 메인 데이터셋
│ ├── 0615미야옹_합성_데이터.jsonl # 초기 증강 데이터
│ ├── 0617합성한원문들.jsonl # AI 생성 원문
│ └── 미야옹원문데이터_최종.jsonl # 기본 원문
├── 데이터시각화/ # 분포 시각화 결과
│ ├── 최종_분포_*.png # 최종 데이터 분포 차트
│ ├── 0615미야옹_합성_데이터_*.png # 0615 데이터 분포 차트
│ ├── 0617합성한원문들_analysis.png # 원문 분석 차트
│ └── 미야옹원문데이터_최종_analysis.png # 원문 분석 차트
├── merge_miyang_data.py # 데이터 병합 유틸리티
└── README.md
# 크롤링텍스트필터링.py
- SNS 텍스트 수집
- 불필요한 문자 제거
- 텍스트 품질 필터링
- 중복 제거# 원문_자동_생성.py
- 23개 주제 기반 원문 생성
- 6가지 감정 상태 반영
- Google Gemini API 활용
- 자연스러운 SNS 문체 구현# 미야옹_데이터_합성자동화.py
- 고양이: ~냥, ~냐옹, ~다옹 어미
- 강아지: ~멍, ~냐왈, ~다왈 어미
- 동물별 이모티콘 및 의성어 추가
- 감정별 특화된 표현 적용# API 키 풀링 시스템
- 다중 API 키 관리
- 분당 요청 제한 처리
- 자동 로드밸런싱
- 실시간 사용량 모니터링| 감정 | 특징 | 예시 이모티콘 |
|---|---|---|
| Happy | 밝고 들뜬 말투 | ❤️, 💛, ✨ |
| Curious | 궁금한 말투, 킁킁거리기 | 🫨, ❓ |
| Sad | 축 처진 말투, 외로움 표현 | 😢 |
| Grumpy | 거만하고 고급스러운 말투 | - |
| Angry | 까칠하고 화난 말투 | 😾, 💢, 🔥 |
| Normal | 평범하고 차분한 말투 | 🐾 |
| 감정 | 특징 | 예시 이모티콘 |
|---|---|---|
| Happy | 밝고 신나는 말투 | ❤️, 💛, ✨ |
| Curious | 호기심 가득한 말투 | 🫨, ❓ |
| Sad | 풀이 죽은 말투 | 😢 |
| Grumpy | 불만이 있는 말투 | - |
| Angry | 공격적인 말투 | 😾, 💢, 🔥 |
| Normal | 즐겁고 일상적인 말투 | 🐾 |
# 가상환경 생성
python -m venv venv
source venv/bin/activate
# 패키지 설치
pip install -r requirements.txt# .env 파일 생성
echo "GOOGLE_API_KEY=여기에_API_키_입력" > .envcd data_augmention
python 미야옹_데이터_합성자동화.py \
--input_file "../데이터/원문데이터.jsonl" \
--output_file "../데이터/증강결과.jsonl" \
--target_count 1000python 원문_자동_생성.py \
--output_file "../데이터/생성된원문.jsonl" \
--count 500python 데이터_감정_분포파악.py \
--input_file "../데이터/증강_데이터17000개(22일업데이트).jsonl" \
--output_prefix "../데이터시각화/분포"{
"content": "오늘 날씨가 정말 좋네요!"
}{
"content": "오늘 날씨가 정말 좋네요!",
"emotion": "happy",
"post_type": "cat",
"transformed_content": "오늘 날씨가 정말 좋다냥! 🐾 밖에 나가서 햇볕을 쬐고 싶다옹! ❤️"
}- 핵심 기능: 원문을 동물 말투로 변환하는 메인 엔진
- 특징:
- 동물별/감정별 프롬프트 템플릿 시스템
- API 키 풀링을 통한 대량 처리
- 실시간 진행상황 모니터링
- 핵심 기능: 23개 주제 기반 원문 자동 생성
- 특징:
- 실제 SNS 문체 모방
- 다양한 주제와 감정 조합
- 자연스러운 한국어 생성
- 핵심 기능: 데이터셋 품질 분석 및 시각화
- 특징:
- 포스트 타입별 분포 분석
- 감정별 균형 확인
- 자동 차트 생성
- 다중 키 관리: 최대 9개 API 키 동시 사용
- 로드 밸런싱: 사용량 기반 자동 키 선택
- 레이트 리미팅: 분당 15회 제한 자동 관리
- 배치 처리: 대량 데이터 효율적 처리
- 오류 복구: JSON 파싱 오류 자동 수정
- 진행률 추적: 실시간 처리 상황 모니터링
google-generativeai>=0.3.0: Google Gemini API 클라이언트python-dotenv>=1.0.0: 환경변수 관리ijson>=3.1.4: 대용량 JSON 처리
KTB 팀 프로젝트 - 데이터 증강