{kind=link}
사용한 데이터셋
- 소상공인 데이터: 카페 시군구명 비교
- 네이버 데이터 : 카페에 대한 15개의 키워드 데이터 포함
코드 간략 설명 (코사인 유사도 관련):
- 코사인 유사도를 계산하는 sklearn.metrics.pairwise 라이브러리를 가져온다.
- 코사인 유사도를 계산하기 위해 rating값을 matrix_dummy에 복사한다.
- 코사인 유사도를 계산할 때 NaN 값이 있으면 에러가 발생하므로 NaN을 0으로 바꿔준다.
- 모든 사용자 간의 코사인 유사도를 구한다. 실행해 보면 user_simlarity는 (n X n)의 차원을 가지며 대각선이 1.0(자기 자신과의 유사도)인 대칭 매트릭스임을 볼 수 있다.
- 나중에 필요한 값을 뽑아낼 수 있도록 user_similarity에 index를 지정해준다.
모델 설명 (Content-Based Filtering):
- 아이템의 내용을 분석해서 아이템 간의 유사도를 계산하고 이를 바탕으로 추천을 하는 방법
- 각 아이템 간의 유사도를 계산하고 카페명을 입력받아 이 카페와 가장 유사도가 높은 n개의 아이템을 찾아서 이걸 추천하는 방법
- 이때 아이템 간의 유사도를 어떤 방법으로 계산할지가 이슌데, 여기서 코사인 유사도 사용!
-
- Binary한 값의 데이터를 사용한 모델과 2) Vector로 숫자 데이터를 모두 포함한 모델
Binary
- 데이터셋 불러오기
- astype(bool).astype(int)을 통해 키워드 별 숫자를 1,0의 binary 값으로 바꾸기
- 카페 종류들과 특징 수에 맞는 열 행렬 생성
- 7661개의 카페끼리 특징에 관하여 코사인 유사도 계산
- 거리지표: 입력된 ‘시군구명’과 동일한 시군구에 속한 카페들 안에서 추천리스트 뽑기
- 추천 함수: 주어진 카페와 다른 카페의 특징의 similarity를 가져옴 —> 거리지표 고려 —> similarity를 기준으로 정렬 —> 자기자신은 빼고 추천해줄 카페를 주어진 수만큼 가져옴
- Input: 1) 몇번째 카페에 대한 추천을 받고 싶은지, 2) 몇개의 카페를 추천받고 싶은지, 3) 어느 지역에 있는 카페를 추천받고 싶은지
- Output: 추천해줄 카페 이름
Vector
- 위와 과정 동일, BUT binary값으로 바꾸는 대신에 기존 데이터셋의 숫자 데이터 그대로 사용!
-
Binary
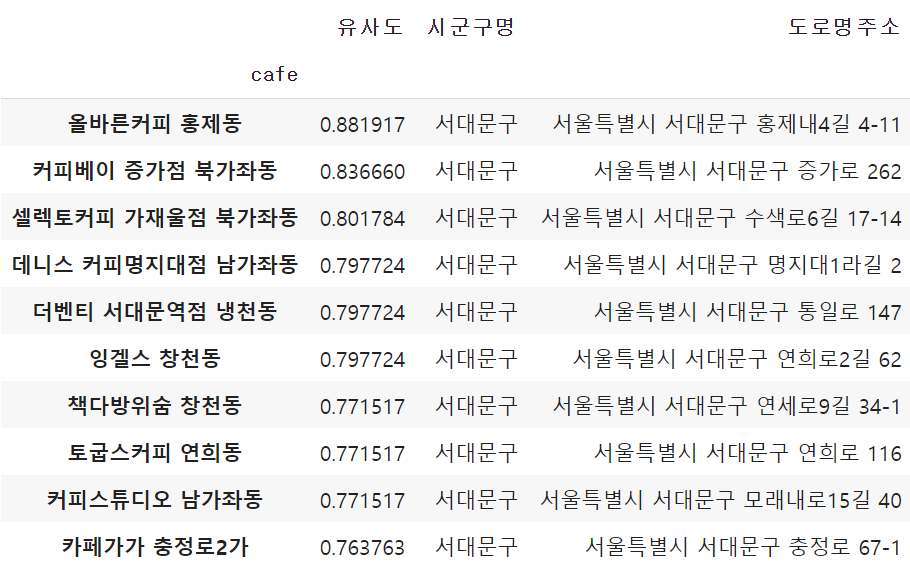
-
Vector
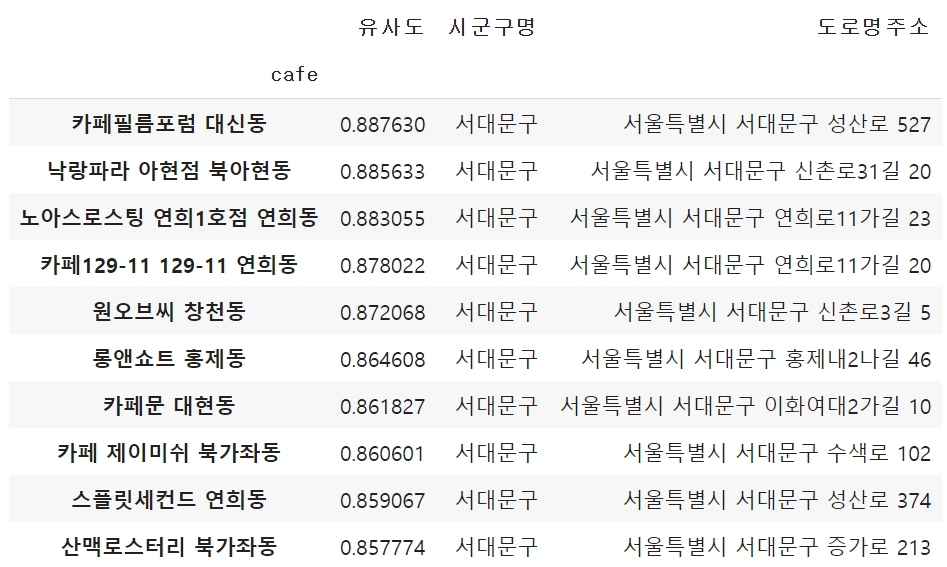
언급해볼 만한 점:
- 일반적인 추천 시스템들은 특징을 binary 값으로 반영해서 컨텐츠 based를 함
- —> 처음에는 이걸 시도해봤는데, 네이버 키워드에는 각 키워드를 선택한 사람들의 숫자 데이터도 포함되어 있기 때문에 이걸 반영하면 더 정확한 추천을 해주지 않을까 싶어서 반영!
- 성능을 측정할 정확한 지표(RMSE)가 없다는 것이 한계점이지만, 동일한 카페에 대해 추천해주는 리스트를 보면 Vector모델이 Binary 모델에 비해 훨씬 특징을 잘 고려한 효과적인 추천을 해주는 것을 알 수 있음!
https://lsjsj92.tistory.com/568 https://pearlluck.tistory.com/666