将字体文件拆分为多个字体文件,每个字体文件包含一部分字符,这样可以减少单个字体文件的大小。字体切片适用于应用中需要加载所有字符(比如有很多生僻字)的情况下,字体以较小的体积、较快的速度呈现在页面。
字体文件的拆分可以参考Google Fonts,它采用机器学习等手段,将字体拆分成合适的粒度,比如把一个 4MB 的字体包分成 100 多个小体积的字体包,每个字体文件包含一部分字符。从某种角度来说,也实现了字体的按需加载。
上实例,我有一个 Noto Sans SC 字体包,其大小为 10MB,共包含 30889 个字符。根据 unicode-range,将其分割成了 101 个字体包,下面展示其中两个字体包的信息。
@font-face {
font-family: 'Noto Sans SC';
font-style: normal;
font-weight: 400;
font-display: swap;
src: url(fonts/notosanssc/font_1.woff2) format('woff2');
unicode-range: U+0000-00FF, U+0131, U+0152-0153, U+02BB-02BC, U+02C6, U+02DA, U+02DC, U+0304, U+0308, U+0329, U+2000-206F, U+20AC, U+2122, U+2191,
U+2193, U+2212, U+2215, U+FEFF, U+FFFD;
}
@font-face {
font-family: 'Noto Sans SC';
font-style: normal;
font-weight: 400;
font-display: swap;
src: url(fonts/notosanssc/font_2.woff2) format('woff2');
unicode-range: U+0100-02BA, U+02BD-02C5, U+02C7-02CC, U+02CE-02D7, U+02DD-02FF, U+0304, U+0308, U+0329, U+1D00-1DBF, U+1E00-1E9F, U+1EF2-1EFF,
U+2020, U+20A0-20AB, U+20AD-20C0, U+2113, U+2C60-2C7F, U+A720-A7FF;
}通过下面两个图的对比,可以发现,文字不同,所加载的字体包也不同,字体包从而实现了字体的按需加载。并且比原始的字体包 10MB 小了太多太多了。
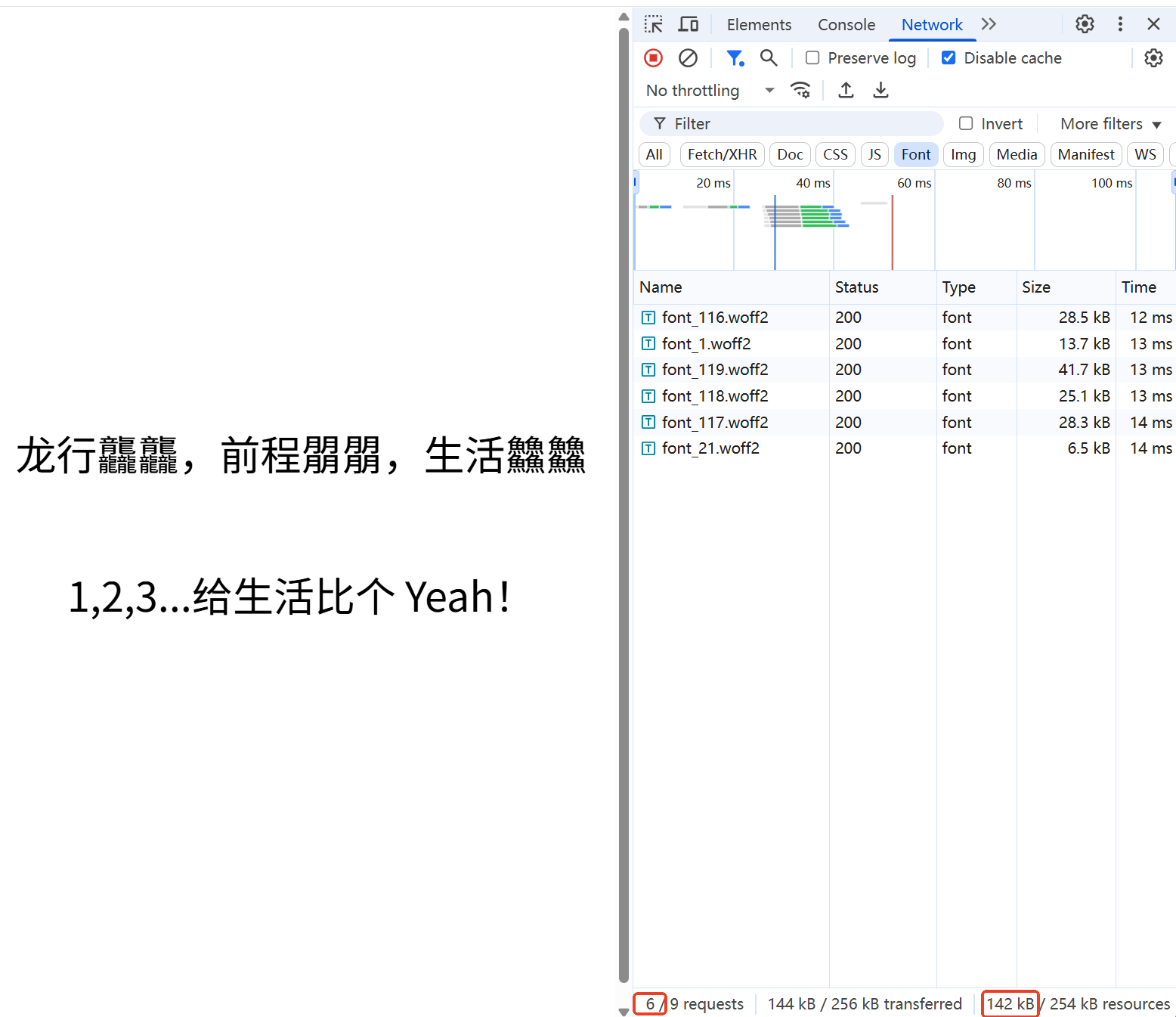
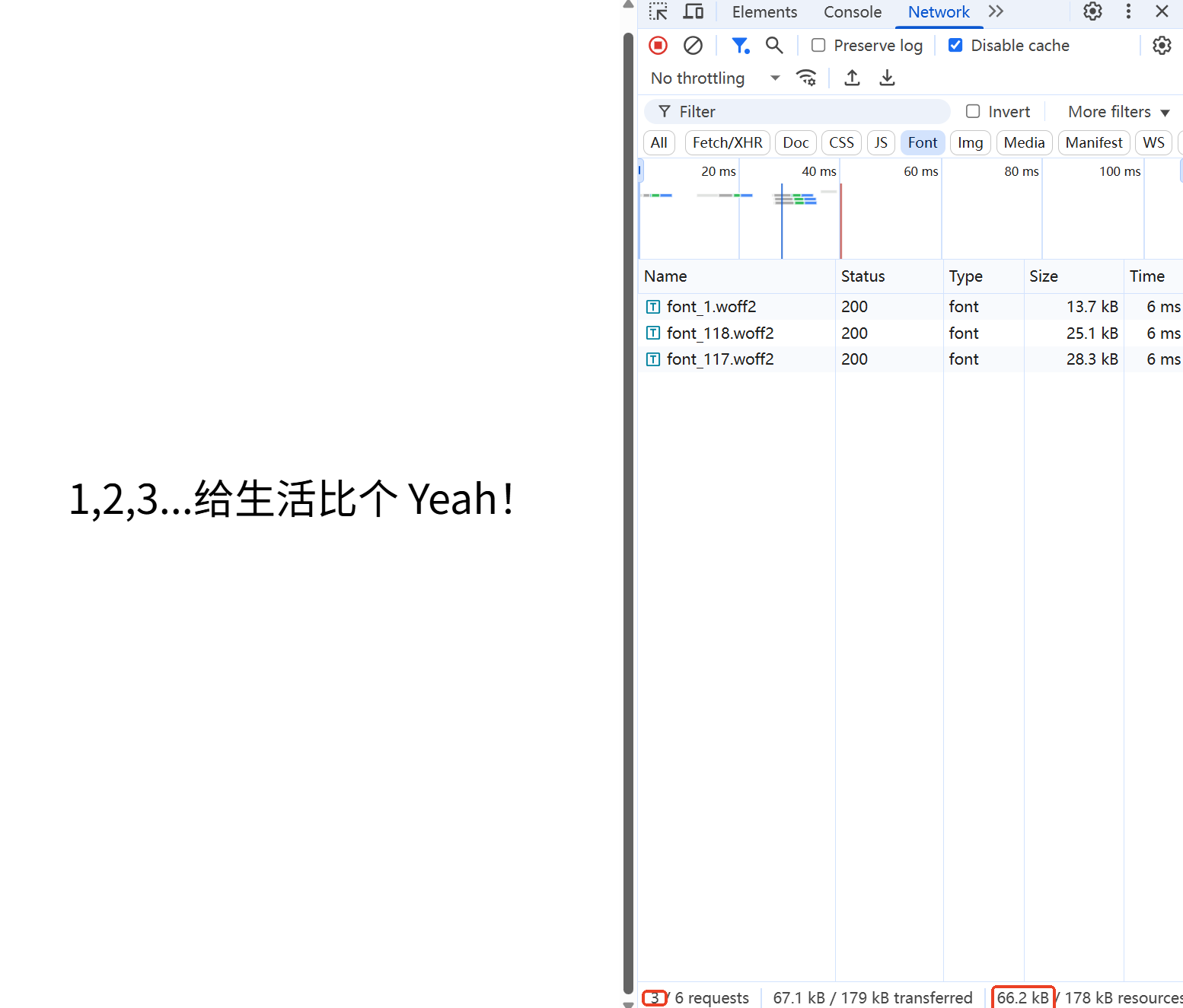
有了 unicode-range,就可以使用 fonttools 工具来进行子集提取了。
pyftsubset Noto Sans SC.otf --output-file=Noto Sans SC.01.woff2 --unicodes='U+0100-02BA,U+02BD-02C5,U+02C7-02CC,U+02CE-02D7,U+02DD-02FF,U+0304,U+0308,U+0329,U+1D00-1DBF,U+1E00-1E9F,U+1EF2-1EFF,U+2020,U+20A0-20AB,U+20AD-20C0,U+2113,U+2C60-2C7F,U+A720-A7FF' --flavor=woff2https://jealyn.github.io/font-slicing-demo/,在输入框动态添加文字,打开浏览器调试工具,查看 Network 中的 Font 项,即可看到字体的动态加载。