Check if ffn_up and ffn_gate are of the same type before using fmoe #495
Conversation
|
Thank you for looking into this. I'll test your change and will report back when finished. Model loads when |
|
It would appear that llama-sweep-bench and llama-cli don't like llama-bench - Works when
|
|
Oh, I see. The model contains I mistakenly thought it is because Unsloth have used different quantization types for Thanks for testing. So, for now, models containing |
|
Ah! Thank you for the clarification. Where can I find the list of quantisation type currently implemented in ik_llama? I'm thinking of attempting to reproduce Unsloth dynamic GGUF quants that would only include supported ik_llama quants. |
All types supported by |
|
Yes sorry this is what I meant, I'm looking for the file/folder where the fast CPU matrix multiplication for IQ1_M would need to be implemented please. I plan to use other UD quants so I will need to see what has been implemented so far for fast CPU matrix multiplication. Edit: I believe I found it - ggml/src/iqk/iqk_mul_mat.cpp |
|
Everything is implemented apart from I personally don't take |
|
I see, not cool what happened here! ... 🫤 I with unsloth could make UD quants compatible with ik_llama. Their imatrix is quite good from what I could measure for my use-cases but they don't provide the calibration dataset they use... So I believe I have a few options here to get blasting fast speed with "unsloth", not sure if all are achievable/realistic or if they even make sense:
I'm leaning towards 1. as I don't understand yet measured the benefits of using _R4 quants. But may have to change my mind and go with option 1. Summary of “Missing quant‐types” per bit |
To see what quantization types exist, take a look here. Everything below |
|
Thanks for all the testing, this helps me understand why the temporary IQ1_S i had rolled seemed off in brief testing. The IQ1_S_R4 is definitely the way to go I see given the recent CUDA support.
tl;dr;You seem pretty smart, don't limit your imagination to what others like unsloth and myself have done already. ik_llama.cpp gives you a powerful palette of quant types and optimizations to come up with your own mixes and methodologies for your use case and hardware. RamblingsSounds like you've done some measurements and possibly observed the quant recipes and imatrix methodologies grouped broadly under the label of "unsloth dynamic 2.0" are good for your use cases? I'm curious how you are doing benchmarks, as it can be pretty challenging with these large models. (maybe u already posted on HF, catching up on messages now). I'm genuinely curious as my understanding is that unsloth recently began to generate synthetic datasets including model specific tokens and using a larger context window e.g. 6-12k rather than the "normal" default 512 context. However it isn't always clear what methodology and imatrix corpus datasets were used on each quant and don't think they upload their imatrix dat files anymore either. My own experience at least with Qwen3-30B-A3B in writing up The Great Quant Wars of 2025 suggests that UD GGUFs are not necessarily "better" in a statistically measurable way at least using the usual methodologies which I try to share openly. In another reddit post about why some folks seem to like unsloth quants, Daniel gave an interesting reply:
I appreciate all the effort they are putting in, am very happy to have more quants to choose from, and honestly they helped get me into all this with the first very small DeepSeek-R1 quants only a few months ago now haha... Their hard work fixing bugs is great too, and I'm glad they are trying out more methodologies, but it isn't clear to me how these effect actual model performance in common situations or that it is always "better". It definitely isn't better in all situations, such as the 128k 4x yarn quant GGUFs which change the Qwen recommended defaults - it might be better if all your prompts are actually 100-128k, but it gives a measurable worse perplexity in shorter context lengths as Qwen warns on the official model card. (link is some data I generated using exllamav3 in discussions with vllm-compressor AWQ quantizations). Anyway, happy Friday and enjoy your weekend! I appreciate your enthusiasm and am looking forward to seeing what you cook up! Always feel free to holler at me as I'm trying to keep up with folks pushing the limits of this stuff like Ed Addario, Bartowski, Unsloth, myself, and now you and others! Cheers! |
|
Hey @ubergarm, thank you for the kind words and most of all for sharing your knowledge here and there, it's been incredibly valuable. I am trying to ramp up my knowledge as fast as I can at the moment. I do not have well structured and scientific methodologies, but mainly rely on some quick tricks to build just enough evidence (to my own appreciation) about what my next steps should be to 1. get a GGUF tailored to my use cases, 2. make the most use of my current hardware in an attempt to avoid spending $20k+ on new hardware which may become obsolete in a couple of years and 3. gain sufficient knowledge to be comfortable with the (ik_)llama.cpp framework which appears to be the most flexible framework there is today for enthusiasts (I've explored exllama, vllm and a few others before). My main target is indeed to be able to process large prompts, so my evals mainly rely on 100k+ prompt processing. And only a few quants are able to remain consistent and reason well at these large context sizes. I'm almost done creating my first dynamic quant using unsloth's DeepSeek-R1-0528 imatrix (it's taking a few hours to produce the quantized GGUF). And I'll report back if there's any success and gains (both quality and speed). I don't think unsloth have published any of their methodologies and calibration dataset. I trust it may be better than the ones produced using calibration_data_v5_rc.txt. And from what I understand as well, this isn't the only factor that plays a role into producing better than average quants. So, baby steps first, I'm first reproducing other people's work, then will decide if it's worth diving further into the rabbit hole - it costs a lot of time... and there are all the other interesting aspects of LLMs that are worth exploring such as building the platform that uses these models or also creating custom refined models. To answer my original question, using |
|
Enjoy the journey, no rush, and glad to see you're doing your own research and testing out what has been done before to figure out how you want to proceed.
Definitely keep us posted. I'm personally skeptical that that particular imatrix will be better given it was made with the previous weights despite the model arch being the same. Feel free to use my own imatrix dat which was made on the updated R1-0528 weights using both
I find this sentiment common though don't understand nor agree with it personally. I'm happy to be proven wrong though! Its not my job to disabuse people of superiority of unsloth quants. lmao... Cheers! |
|
@ubergarm - Thanks, I went with option 1. (Get the imatrix from unsloth and produce my own quants for ik_llama). I've adapted the quants they use in their model to be ik-optimised. I'll be testing the quality of the model. |
|
Early observations using PPL: Using unsloth's imatrix into IQ1_S quants leads to slightly degraded results. Unless I'm missing something, there are no mind-blowing results when evaluating mixture of quants. I have not evaluated the original UDs, but from what I can see the ones I've adapted to ik don't lead to surprising results. I have yet to do more eval, but I'm already noticing that for my specific hardware and use case (110k+ context size) I should target IQ3_XXS - I believe the PPL should be around 3.34. I'll give it a go and will report back. |

|
Thanks for all the heavy lifting and number crunching to confirming some things. Your measured numbers for my IQ2_K_R4 and IQ3_K_R4 line up closely with my own so seems like you're methodology is sound. Nice job!
You're in luck, because My advice would be to consider using Then maybe IQ3_XXS for ffn_down and IQ2_XXS for ffn_(gate|up) or something similar to hit the size for which you're aiming. Again feel free to use my R1-0528 imatrix which was made including the fixes to imatrix MLA computation in recent PR411 so likely the best you can find without making your own. Have fun and keep us posted! I'd be interested in your |
|
I need some help to understand quant performance - how can I know which quant performs better than others? Are there metrics somewhere that I've missed? For example, when using @ubergarm's quants: Perfs are great - pp and eval are through the roof, example: 5.50t/s for eval. But now, if I decide to change the quant of the routed experts from Why is it that changing How do I know which quant will result in perf degradation in advance and which ones result in great perfs? And why is it that I'm really lost here. Edit: ChatGPT to the rescue on that one - https://chatgpt.com/share/684f3874-83f4-800f-a3b6-e9ac15ec48cd but unsure how accurate the answer is. |
|
Great job you've come a long way in a short time! This is a great question. You're getting deep enough now that the answers are not simple! I'm no expert and will likely make some mistakes in this, but you'll get the gist.
Given the context of your post my impression is you are interested in "performance" in terms of inference speed both token generation and prompt processing. (not in terms of quality like PPL/KLD similarity to the original model).
Great to hear! I tried to choose my quants recipes based on a mix of quality and speed. Though given recent improvements in various quant inferencing implementations, there are probably other good combinations as well depending on your exact hardware. Keep in mind the "best" quant in terms of speed depends on a number of things:
Right more specific to your exact problem at hand: "Which quants should I choose for my recipe to optimize speed?". I'm not sure there is a great way to know "in advance" honestly unless you look through the code to see which quants have like MMQ (quantized matrix multiplication psure) implementations for your target hardware. If it has to rely on fp16 and fp32 dtype registers, it will likely be slower especially on CPU etc. Personally, I pick a small model of similar architecture and make a bunch of quants. Then test them with llama-sweep-bench to empirically discover which ones are faster e.g. Then I use what I learn in that experiment to inform how to quantize the larger models.
You saw recent updates to Anyway, you get the idea. So in conclusion my basic approach is:
Also I'm very happy to fail. I've made many more quants that never saw the light of day than those that I upload to hugging face. Failure is half the fun. xD Cheers! |
|
Thank you for the tips!
This! That was indeed going to be my next step. But I'm still very surprised to hear that there is not "general" universal quant benchmark, at least for CPU AVX-2 to give us an idea of what speed to expect for each quant. My assumption here is that it doesn't exist because would be vastly inaccurate and strongly dependent of config type... but I still find it surprising to be honest. Would you know a model that uses the same arch as DeepSeek R1-0528 that is relatively small? I just ran some benchmarks on: https://huggingface.co/Thireus/DeepSeek-R1-0528-CODER-DRAFT-0.6B-v1.0-BF16-GGUF Here are the results: I've quantised these layers, and left all the others at q8_0: Basically I should avoid any quant below f32 from the bench results table above. But then there is |
Yeah ik and folks use DeepSeek-V2-Lite which is ~16B MoE 2.4B active.
Oh interesting, you made a lot of quants of that little 0.6B, very cool! Is this running on all layers offloaded on a single CUDA device with For DeepSeek-V2 architechture (R1-0528 etc) my strategy is:
Hope that sheds some more light on things. |
|
I don't think this model is very useful for measuring performance. Most tensors in this models have row sizes that are not a multiple of 256, which is required for almost all quantization types except Also, aren't you trying to benchmark CPU performance? (your results don't look like CPU performance at all). Either way, here are the types that you can meaningfully benchmark with this model, along with their CPU performance on my Ryzen-7950X:
I also don't think it is productive to blindly go through a list of names. One does need to understand what all these types are, do they need an imatrix or not, is it better to use an imatrix or is it OK tun run without, how many bits they use, etc. |
|
Thank you @ubergarm and @ikawrakow - I'll switch to DeepSeek-V2-Lite so it can be a better representation of R1-0528 The measurements I took were with partial offloading and latest ik_llama build. So I get a mix of GPU and CPU. But indeed those are not the speed of each quant, rather it gives an indication of which quant will slow down the overall speed perfs when used in a GPU+CPU mix. My current strategy remains to save as much time as possible in this quest of producing the most optimised GGUF for my hardware. So, anything that removes the human factor to perform any pre-assessment of which quants to use or not based on the hardware/model_architecture/quant_theory would help. I'm currently sitting on the Bruteforce method below: Bruteforce method - Effort: Minimal (measured in hours) - Full automation with scripts - Drawback: Limited knowledge gain
Smart method - Effort: High (measured in weeks/months) - Full manual - Drawback: Time (which I don't have)
|
For each quant type you want to learn more about you can search for it here. The There is a method between the two in which you do the bruteforce method, but then focus your attention on select quants you want to learn more about. |
|
Your brute force method is unlikely to produce a meaningful outcome. You don't want to just find the quantization type that runs fastest on your hardware, but the quantization mix that runs the fastest and satisfies a minimum quantization quality requirement. Because, you know, the absolutely fastest model is the one that does no computation at all. |
|
How you coming along? Things have changed a lot just in the past couple days with the enhanced CPU Prompt Processing in closed This seems to create three "tiers" of quant speed for CPU based PP from how I understand it reading Note that all three tiers are very optimized now relative to other forks. So this is mostly a distinction between the groups relative to each other on this fork. While there is still some variation within each "tier", the easiest way to tell quickly besides pulling up those PRs, is grep the code like so: 👈 A Tier$ cd ik_llama.cpp/ggml/src/iqk
$ grep Q8_K_R8 iqk_mul_mat.cpp | grep type
case GGML_TYPE_IQ2_XXS: return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ2_XS : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ2_S : return nrc_y >= 16 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ3_XXS: return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ4_XS : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ3_S : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ1_S : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ1_M : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_Q2_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_Q3_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ2_KS : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ2_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ3_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ4_KS : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ4_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ5_KS : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ5_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;
case GGML_TYPE_IQ6_K : return nrc_y >= 32 ? GGML_TYPE_Q8_K_R8 : type;👈 B Tier$ cd ik_llama.cpp/ggml/src/iqk
$ grep Q8_0_R8 iqk_mul_mat.cpp | grep type
case GGML_TYPE_Q6_K : return nrc_y >= 64 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_Q4_0 : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_Q5_0 : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_Q6_0 : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_IQ4_NL : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_Q8_0 : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_IQ2_KT : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_IQ3_KT : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_IQ4_KT : return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_IQ2_KT: return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;
case GGML_TYPE_IQ4_KT: return nrc_y >= 32 ? GGML_TYPE_Q8_0_R8 : type;👈 C Tier$ cd ik_llama.cpp/ggml/src/iqk
$ grep Q8_1 iqk_mul_mat.cpp | grep type
case GGML_TYPE_Q4_K : return nrc_y >= 32 ? GGML_TYPE_Q8_1 : type;
case GGML_TYPE_Q5_K : return nrc_y >= 32 ? GGML_TYPE_Q8_1 : type;
case GGML_TYPE_Q4_1 : return nrc_y >= 32 ? GGML_TYPE_Q8_1 : type;
case GGML_TYPE_Q5_1 : return nrc_y >= 32 ? GGML_TYPE_Q8_1 : type;There is more to take into consideration than just PP speed on CPUs with avx2 support of course, like the GPU speeds for offloaded layers, perplexity, overall BPW as TG is generally memory i/o bound, etc. Just wanted to check it with you and also write this up to help my own brain process the changes haha... Finally no need to sweat it too much. I tested changed Cheers! EDIT: The biggest upshot here for me is that the |
|
Thank you for all the feedback. I am making small progress and I'm working towards a combination of quants that brings high speed (both prompt eval and new tokens) as well as reduced PPL on my hardware. I'm on Intel x299 and there are a lot of quants that really kill the CPU speed (hence my initial high failure rate). The best model I was able to produce so far in terms of speed while maintaining a fair quality has the following characteristics:
I have also found that I need a model that is around 240GB in size max. So I'm currently cooking some quant mixes to achieve this (this is where the gap on the graph is). Once I find the most optimum mix I'll upload the model, including the eval results and the secret recipe. tl;dr: Still cooking. |
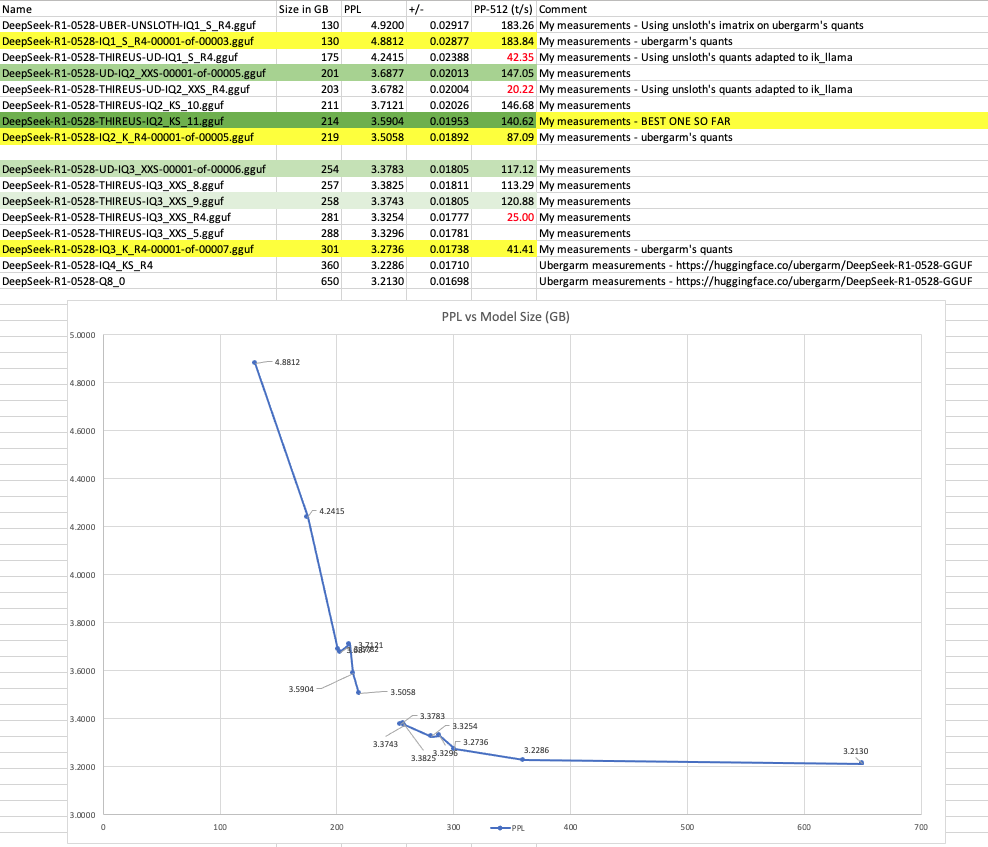
I don't get why they are called "secret recipes", even if not provided if a mix is, you can gguf-dump to get them (even if that is in a more inconvenient way than the custom regex used). If you share what your current working mix is then it would allow people to make suggestions on what you might want to change to use the ~26GB of extra budget you have. I have gone through the process you have with a lot of iterations optimizing for performance while maintaining my quality standard within a size budget (although my size budget was higher than yours). |
For myself at least, it is jest as I do my best to make my recipes known, easy to repeat, and provide imatrix data etc. And yes the gguf-dump is very useful. I'm not sure why huggingface throws "bad gguf magic number" for some of my quants but not others, as I like to look at a gguf before downloading it sometimes. Anyway, thanks as always for sharing all of your experience and guidance, you are very generous. Regarding "extra 26GB of budget" type stuff, I still wonder what the best way to add a little more fat to an otherwise fairly homogeneous quant. For example, using the normal pattern of ffn_down slightly larger than ffn_(gate|up) will hit a given size for a given quant type. If you want just a little more, is it best to increase like the first 8 layers one size? Then maybe the last few layers a little bigger? I've seen this done in some discussions, but even with the layer-similarity score I'm not sure how best to vary some layers over other layers other than lots of trial and error. Thanks! |
My question was not directed toward your use which I understood as a jest, it's just that I've seen some people use it more literally.
It might have something to do with this? #432
And thank you for the work you did in polishing a lot of it up and popularizing it.
Well it depends even within the constraint of "homogeneous quant" there is a world of difference between low and high bpw.
My solution was to try to learn from not only my own trial and error but also others. I know you can try to understand it more with theory, but it seems like people can end up with good results coming from either theory or intuition. |
|
Just wanted to share that I haven't given up, in fact I have made my first breakthrough today after a week of bruteforcing and auto-analysis to find the optimum quant combination, which allowed me to cook the following dynamic quant today:
I still need ~ 2 weeks worth of computing to achieve better results in speed and quality than the above. Then, I plan to share the methodology, scripts and quants. |

|
Thanks for the report! You're exploring the heck out of that inflection "knee point" between 200 and 300 GiB and cool to see the updated plot. Keep up the good work, and keep in mind it is somewhat of a moving target with recent PRs like 559 which have made Looking back I'd definitely change a few things on my quants like probably standardize using Cheers! |
|
Yes, I keep feeding the new quants to my automated scripts as soon as they are released/improved, so they can ingest them and see if they are of any good use. I've also fed the latest iq3_ks. I've also experimented with _kt. I've taken a lot of shortcuts (including interpolation of partial metrics and mathematical models based on partial or guessed data) to save time and cost and speed up the quant mix discovery and calibration process. I'm not yet entirely happy about the quality of some scripts nor some algorithms that can still be improved. Nevertheless, I believe the methodology is mature enough to provide near optimum quant mixes, competing against popular quants such as unsloth quants. I have created a script that can produce optimum mix recipes given a VRAM and RAM GB target. So, I'm happy to report I was able to produce a mixture tonight that fits exactly 240GB which was my target, and fits 99% of my free RAM without incurring any speed loss. The PPL is also the lowest I've achieved so far.
Since I run my scripts on partial metrics, full metrics will be available in about 5-6 more days (I had made a mistake in my calibration dataset last week and had to redo all the computation), so there is still a bit of hope that I can reach slightly lower PPL for this size. In the meantime, here's a zero-shot screensaver created by that mixture of quants which I very much like (part of my own quality check testing, so can't disclose the prompt): https://thireus.com/GITHUB/screensaver.py |
|
MVP1 published - https://github.com/Thireus/GGUF-Tool-Suite Example of quant mix recipe available here.
Config: 1x 5090 + 2x 3090 + i9 9980xe with 256GB DDR4 Custom recipes can be produced within minutes for different VRAM and RAM requirements, see README file for basic instructions. Article coming soon. |
Apparently some quant cookers are going as far as using different quantization types for
ffn_upandffn_gate. As this possibility is not correctly handled in the fusedffn_up+ffn_gateop, this PR adds a check and disablesfmoein these layers.