Data Quality tasks goal is to implement processes for cleansing, standardization, parsing and validation of data based on Customer and Address data.
Data set to be used as source for analysis is: DQ_Tasks_Cutomer_Data.csv found in the same folder as the current document. Additional files for the tasks: Names.xlsx and Addresses_BG.7z
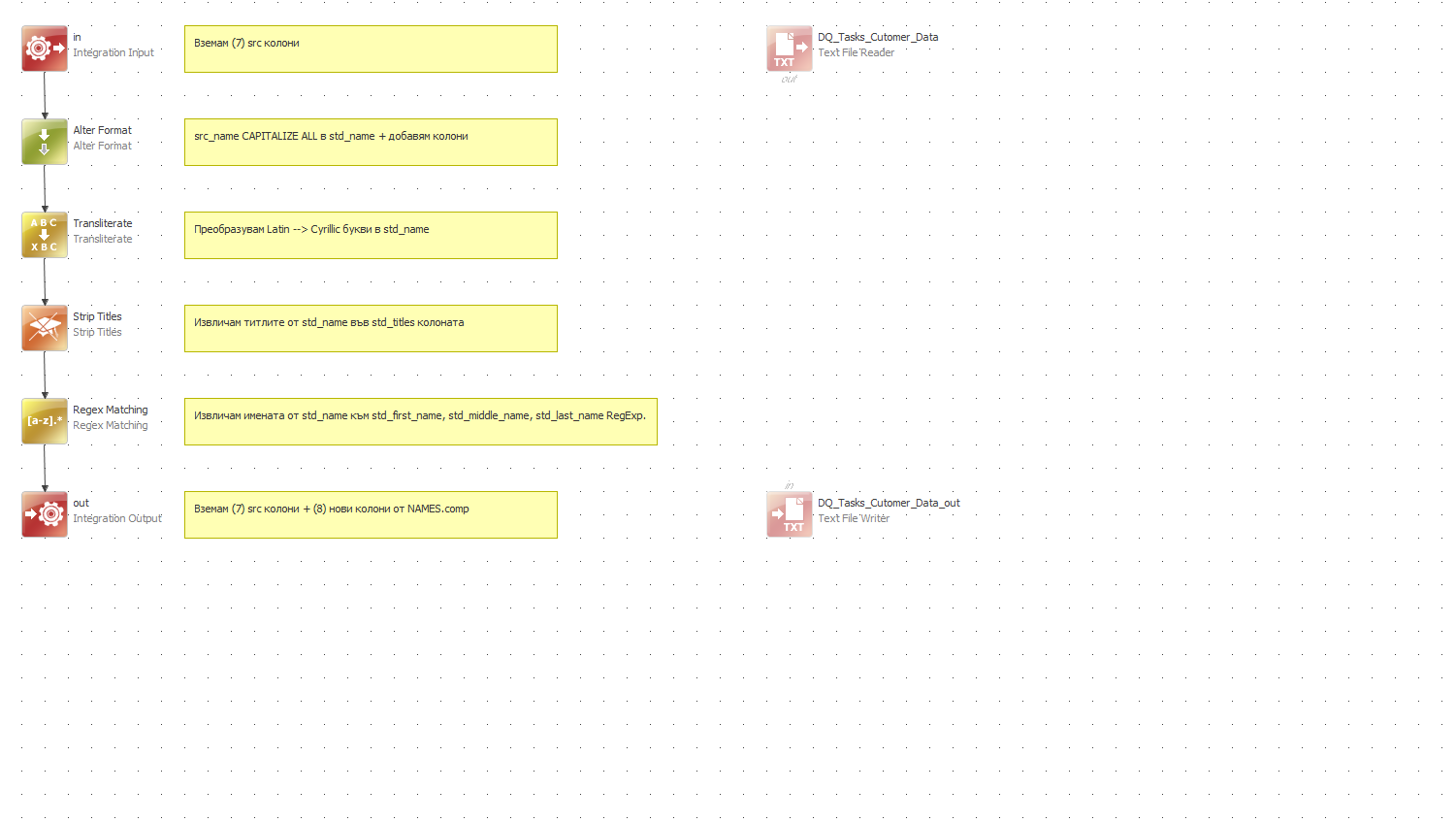
1.1. Basic Profiling of NAME column - analyze patterns in the field, create rule to identify names with incorrect format -e.g. contain Latin letters and/or digits. Document the issues and required actions in an excel file with at least three columns - column, issue(s), DQ actions, etc.
1.2 Cleansing and Standardizing - remove all noise symbols (%",/@#, etc.), squeeze spaces, capitalize all, transliterate all Latin letters/digits into Cyrillic ones
1.3. Parsing - split names column into individual columns for: titles, first name, middle name last name
1.3.1. Build Ataccama specific lookup file for titles (e.g. инж., доц., проф., д-р, г-н, г-жа, etc.) - define your own list of bulgarian titles. Based on the titles, lookup parse out the titles from Name in separate column.
1.3.2. Build Ataccama specific lookup file for first names using file Names.xlsx as input. The file is in the same folder as the current document. Based on the Names lookup parse out the first names from Name in separate column. For names not found in the Names lookup parse out only one word from Name column. Output a flag indicating whether the first name is found in the lookup.
1.3.3. Parse out middle and last name in separate columns. Last name can be of two names, where the two names can be separated by dash or space.
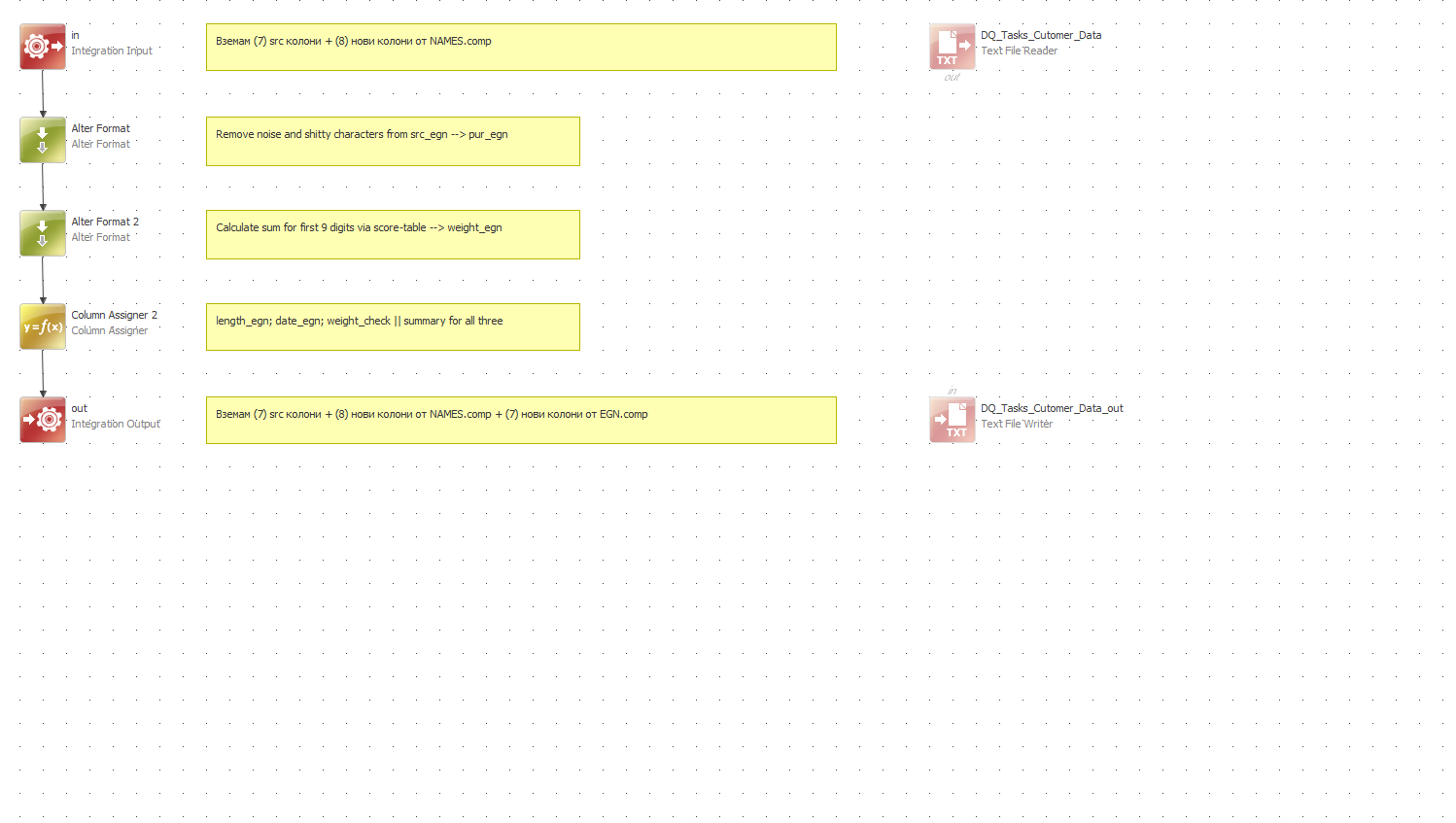
2.1. Basic Profiling of EGN column - analyze patterns in the field, create rule to identify EGN with incorrect format (e.g. non-digit symbols, extra spaces, length less or more than 10 digits). Document the issues and required actions in an excel file with at least three columns - column, issue(s), DQ actions, etc.
2.2. Cleanse - remove all non-digit symbols (%",/@#, etc.) and remove all that are less or more than 10 digits
2.3. Validate - apply algorithm for validation of EGN (algorithm is publicly available)
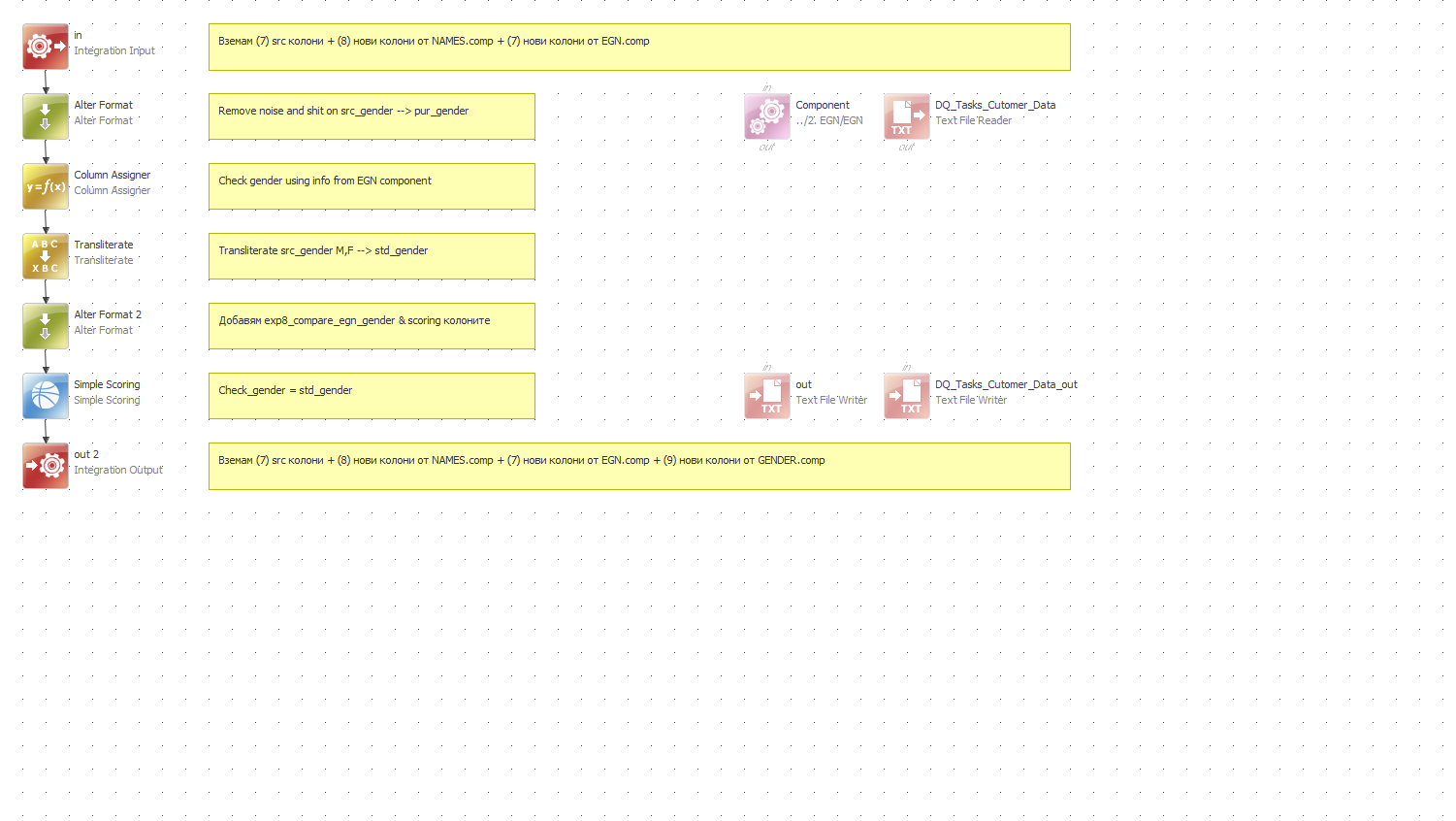
3.1. Basic Profiling of GENDER column - analyze patterns in the field, create rule to identify GENDER with incorrect format (e.g. noise symbols, extra spaces, latin letters). Document the issues and required actions in an excel file with at least three columns - column, issue(s), DQ actions, etc.
3.2. Cleanse - remove all noise symbols (%",/@#, etc.), squeeze spaces, capitalize all, transliterate all latin letters/digits into cyrillic ones
3.3. Standardize - standardize field data to contain either 'М' for male and 'Ж' for female (e.g. мъж-> М, жена -> Ж)
3.4. Validate and Infer - if valid EGN exists, then infer gender from the 9-th digit of EGN (odd digit->'Ж', even digit-'M'). Output a flag to indicate the following: Gender different from inferred (existing), Gender inferred (if missing), Gender valid (existing and equal to inferred)
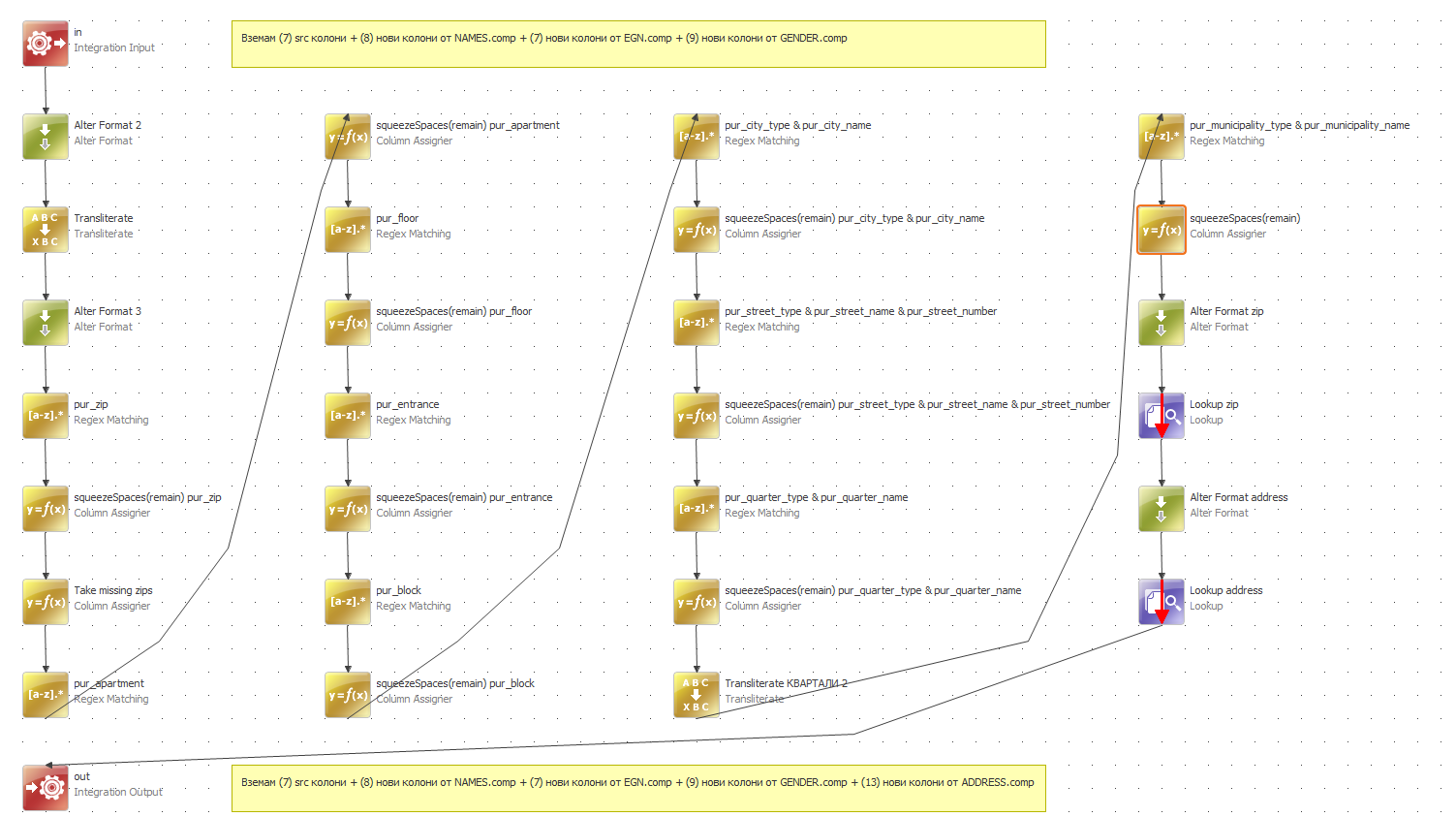
4.1. Parse out the ADDRESS column into separate columns for
- ZIP code,
- city type (ГР., С., К.К, В.З),
- city,
- quarter (ж.к., кв.),
- quarter name,
- street type (),
- street name,
- street number,
- block number,
- entrance number,
- apartment number.
All extra information should be kept in a separate column.
4.2. Validate ZIP Codes - use file BGPopulatedPlaces.txt in the archive Addresses_BG.7z - Cyrillic Windows 1251
4.3. Validate addresses (street names) - use BGAddresses.txt in the archive Addresses_BG.7z - Cyrillic Windows 1251
5.1. Create components for Names, EGN, Gender and Addresses. Addresses can be separated in several components. Pass the data through those components and create one output file.
