Spark 使用GBDT(梯度提升树)算法预测土壤干旱情况
数据集地址:https://www.kaggle.com/cdminix/us-drought-meteorological-data
Ubuntu虚拟机准备环境:
1⃣️设置master、worker节点
sudo gedit /etc/hosts : master/worker1/worker2
2⃣️ssh 免密登录
生成密钥:ssh-keygen -t rsa
分发公钥:cat ~/.ssh/id_rsa.pub | ssh -p 主机A@主机A的IP 'cat >> ~/.ssh/authorized_keys’
3⃣️配置Java和Scala环境
Java、Scala使用版本必须与使用的Spark版本对应
配置环境变量:sudo vim ~/.bashrc
export SCALA_HOME=/opt/scala/scala-2.12.15
export PATH=${SCALA_HOME}/bin:$PATH
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-arm64/
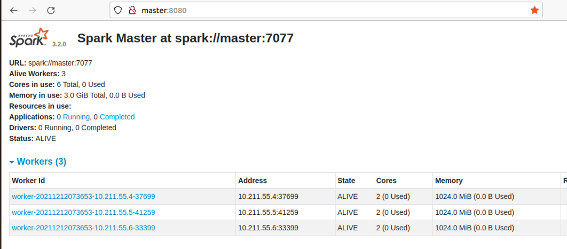
Standalone模式部署集群:
1⃣️从官网下载Spark:
使用spark-3.2.0-bin-hadoop3.2版本
2⃣️进入conf目录,配置spark-env.sh,确定master
sudo vim spark-env.sh
SPARK_MASTER_HOST=master
SPARK_MASTER_PORT=7077
3⃣️修改worker文件,确定worker
sudo vim slaves
master
worker1
worker2
4⃣️在sbin/spark-config.sh文件下添加JAVA_HOME
5⃣️配置环境变量:
sudo vim ~/.bashrc
export SPARK_HOME=/spark-3.2.0-bin-hadoop3.2/
export PATH=$SPARK_HOME/bin
6⃣️把spark环境分发到集群节点
scp -r spark-standalone / worker1(2):/home/parallels
7⃣️启动standalone集群
sbin/start-all.sh