Типичный процесс проведения анализа данных включает несколько этапов:
- предварительная обработка данных или ETL, Extract-Transform-Load (1-Data_Prep);
- анализ данных или Exploratory Data Analysis (2-EDA).
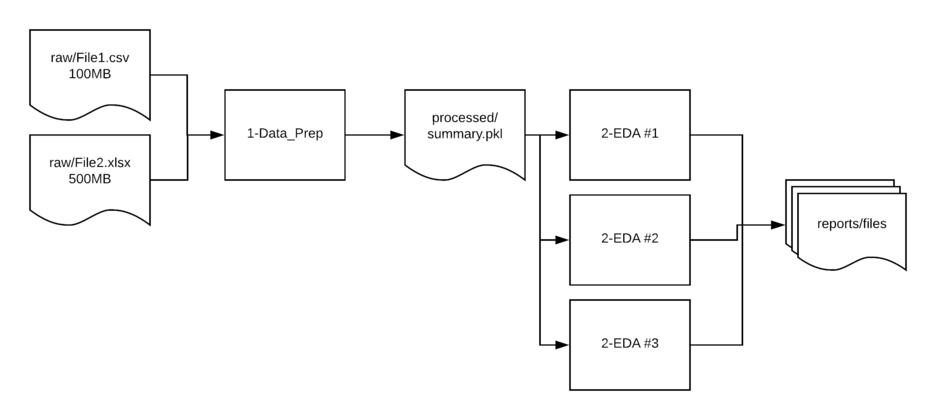
Jupyter (Lab) Notebook перекладывает ответственность за структуру проекта на исследователя, поэтому важно о структуре подумать заранее.
Следующий шаблон ускорит разработку проектов в области науки о данных, т.к. обладает ясной и предсказуемой структурой файлов и директорий (повторяет схему выше):
.
├── 1-Data_Prep.ipynb # Блокнот для подготовки данных
├── 2-EDA.ipynb # Блокнот для анализа данных (может быть несколько)
├── data # Директория с данными
│ ├── interim # Рабочая директория для временных файлов
│ ├── processed # Очищенные данные, готовые к анализу
│ └── raw # Оригинальные (сырые) данные (никогда не должны изменяться)
└── reports # Финальные отчеты (например, Excel)В дистрибутиве Anaconda/Miniconda установка следующая:
$ conda config --add channels conda-forge
$ conda install cookiecutterЕсли начнет ругаться на отсутствие git:
$ conda install -c anaconda gitВ пути желательно не указывать кириллические символы, Anaconda/Miniconda их не любят.
В директории, в которой вы хотите хранить запускаемый проект, выполните шаблон следующим образом, ответив на вопросы, относящиеся к вашему проекту:
$ cookiecutter https://github.com/dm-fedorov/pbp_cookiecutter
project_name [project_name]: data_journalism_project
directory_name [data_journalism_project]:
description [More background on the project]: Исследование трендов.В результате появится директория data_journalism_project, в которой хранятся необходимые файлы.
- Идея шаблона из статьи.
- Документация по Cookiecutter: Better Project Templates