Learn how to scrape flight data from Kayak using powerful web scraping tools. This guide provides step-by-step instructions to help you collect accurate and up-to-date flight information for travel analysis, price comparison, and more.
Want to track flight prices, compare deals, or gather travel insights from Kayak?
In this guide, we'll show you how to scrape flight data from Kayak using the right tools and techniques—without getting blocked. From setting up your scraping environment to handling dynamic content and bypassing restrictions, you'll learn everything you need to collect accurate flight information efficiently. Let's get started!
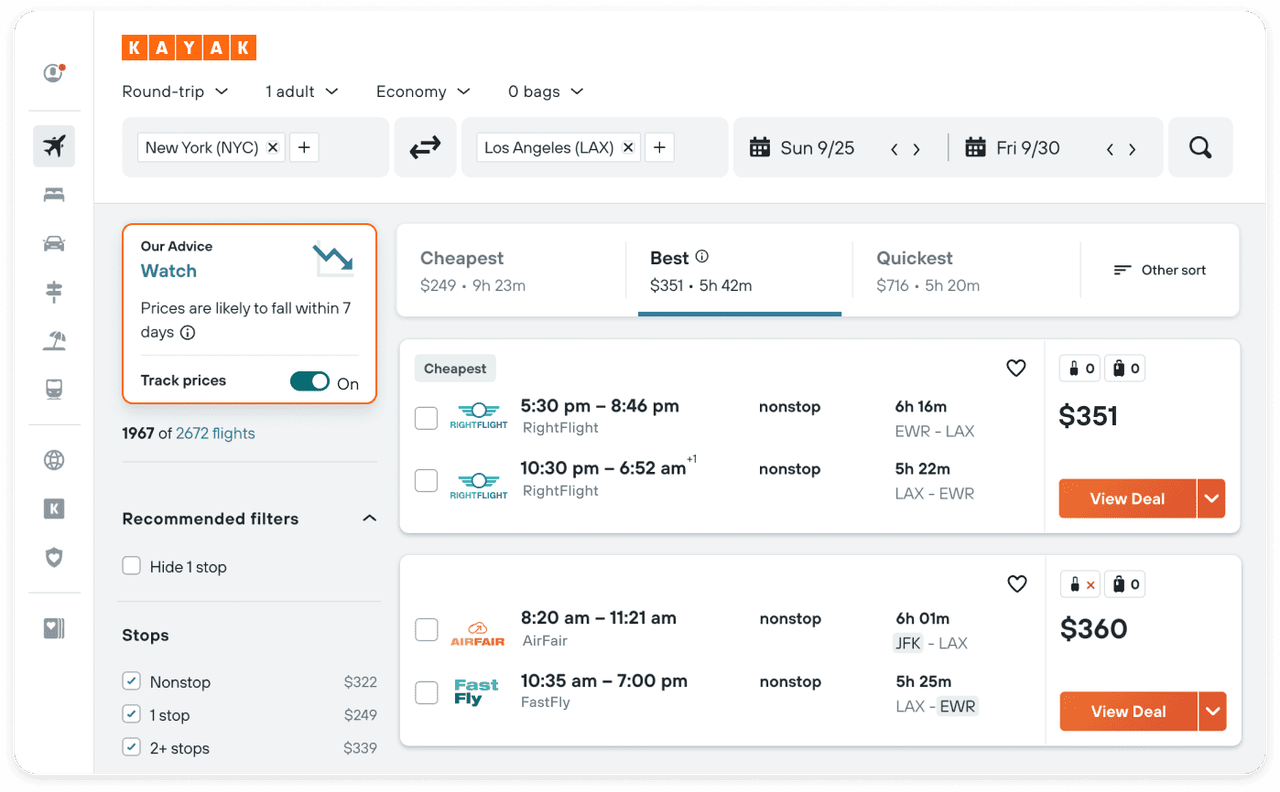
Image Source: Kayak
Launched in 2004, Kayak has become a widely-used travel search engine, helping travelers find the best deals on flights, hotels, car rentals, and vacation packages. By aggregating and comparing prices from numerous travel sites, Kayak enables users to book directly through providers or on its own platform.
Flight data is extremely valuable in many fields, as follows:
- Travel planning: Accurate and real-time flight information can help the platform provide users with the latest travel information, so that users can book their trips at the most appropriate time.
- Price monitoring: By tracking flight prices over a long period of time, companies can identify price fluctuation trends and predict the best time for travelers to buy tickets.
- Market analysis: Historical flight data can reveal changing trends in consumer demand, popular travel periods, and pricing strategies, providing strong support for tourism industry analysts and market researchers.
Before diving into the technical details of Kayak’s data, it’s important to consider legal and ethical issues:
- Follow platform rules: Read Kayak’s terms of service carefully to confirm whether data scraping is allowed.
- Follow Robots.txt files: Check Kayak’s Robots.txt file to understand which pages are allowed or prohibited for crawlers.
- Avoid server stress: Reasonably control the frequency of crawling requests to avoid overwhelming Kayak’s servers.
In this section, we will introduce effective methods to scrape flight data from Kayak, ensuring that you get the most accurate and up-to-date information.
In this section, we will introduce how to easily scrape Kayak flight data using Scrapeless. Scrapeless is an advanced web scraping platform designed to provide seamless and efficient data extraction.
- Extensive proxy network: Scrapeless provides a large and diverse network of high-quality rotating proxies around the world.
- Comprehensive data access: Scrapeless provides access to a variety of data sources, including e-commerce websites, search engines, social media, etc.
- Real-time data transmission: Scrapeless ensures real-time data retrieval, providing support for scraping Kayak flight information, market research, and competitive analysis, etc.
- Customizable data collection: With powerful tools and API integration, Scrapeless allows users to customize their data collection process.
- Compliance and security: Scrapeless prioritizes data privacy and compliance with all legal requirements.
- After signing up for free on Scrapeless, you have a free $2 to search.
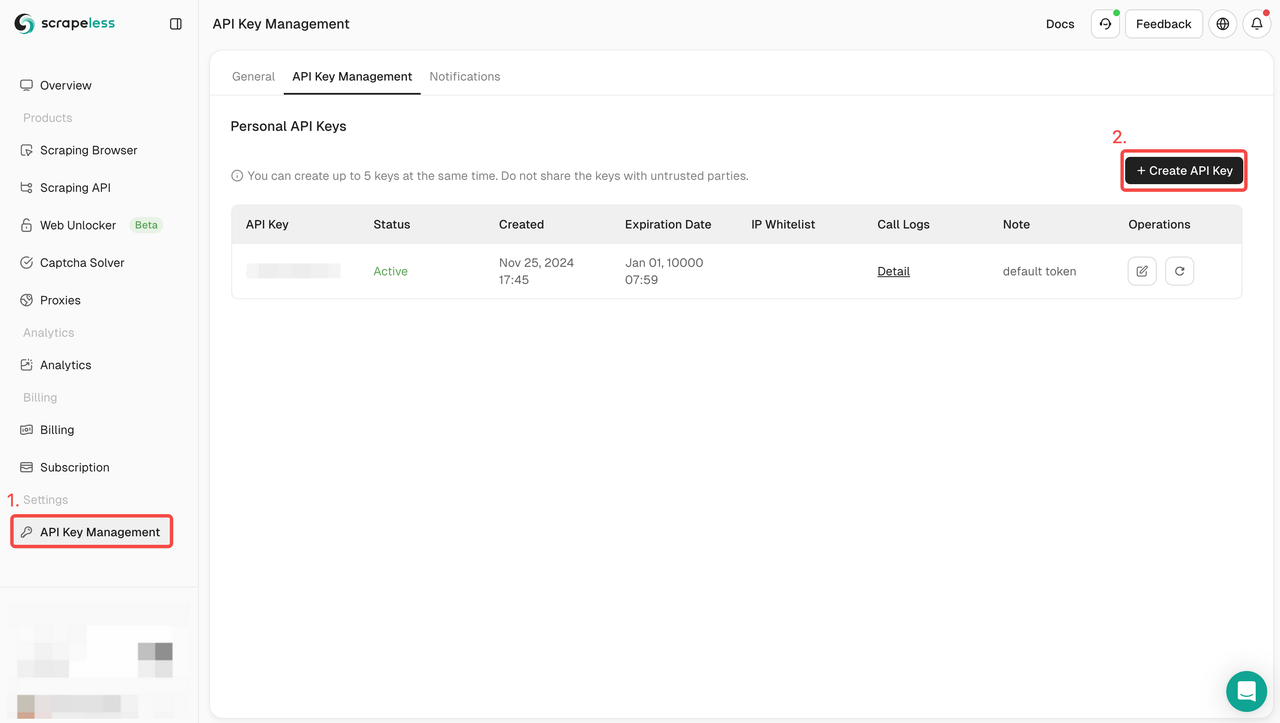
- Navigate to API Key Management. Then click Create to generate a unique API key. Once created, just click on AP to copy it.
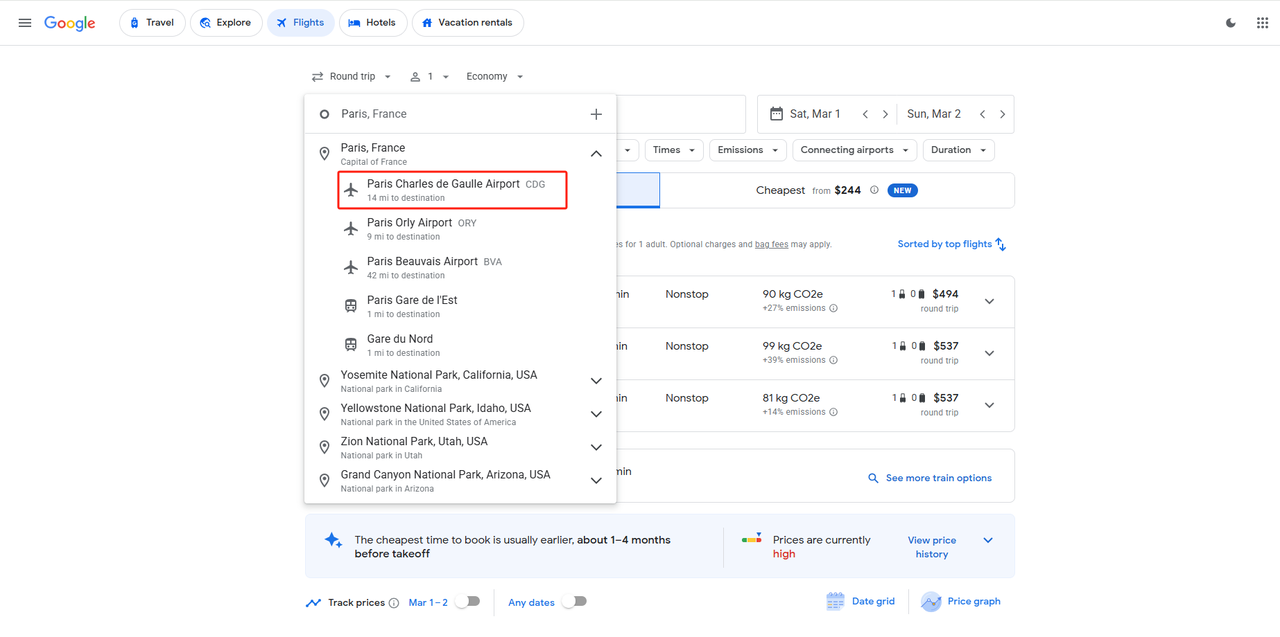
Suppose we want to arrive at Berlin Brandenbury Airport from Paris Charles de Gaulle Airport, departing on March 1, 2025, and returning on March 4, 2025. Once we have the departure point, destination, departure date, and return date, we can form a complete parameter structure:
input_data = {
"departure_id": "CDG",
"arrival_id": "BER",
"data_type": 1,
"outbound_date": "2025-03-01",
"return_date": "2025-03-04"
}
Parameter description: departure_id and arrival_id are the airport codes corresponding to the airports filled in, which are set by the International Air Transport Association.
If you don't know the code of the corresponding airport, you can directly access Google Flights to get it in the departure and destination. data_type represents our departure type, 1 represents Round trip.
After the parameters are formed, we can assemble the complete code, where you also need to replace your_token with your Scrapeless API key:
import json
import requests
class Payload:
def __init__(self, actor, input_data):
self.actor = actor
self.input = input_data
def send_request():
host = "api.scrapeless.com"
url = f"https://{host}/api/v1/scraper/request"
token = "your_token"
headers = {
"x-api-token": token
}
input_data = {
"departure_id": "CDG",
"arrival_id": "BER",
"data_type": 1,
"outbound_date": "2025-03-01",
"return_date": "2025-03-04"
}
payload = Payload("scraper.google.flights", input_data)
json_payload = json.dumps(payload.__dict__)
response = requests.post(url, headers=headers, data=json_payload)
if response.status_code != 200:
print("Error:", response.status_code, response.text)
return
print("body", response.text)
if __name__ == "__main__":
send_request()
Of course, our parameters are far more than that. We can also provide you with other parameters of Google Flights, such as the number of passengers, number of stops, maximum price, etc. For details, you can refer to our Scrapeless API official website documentation.
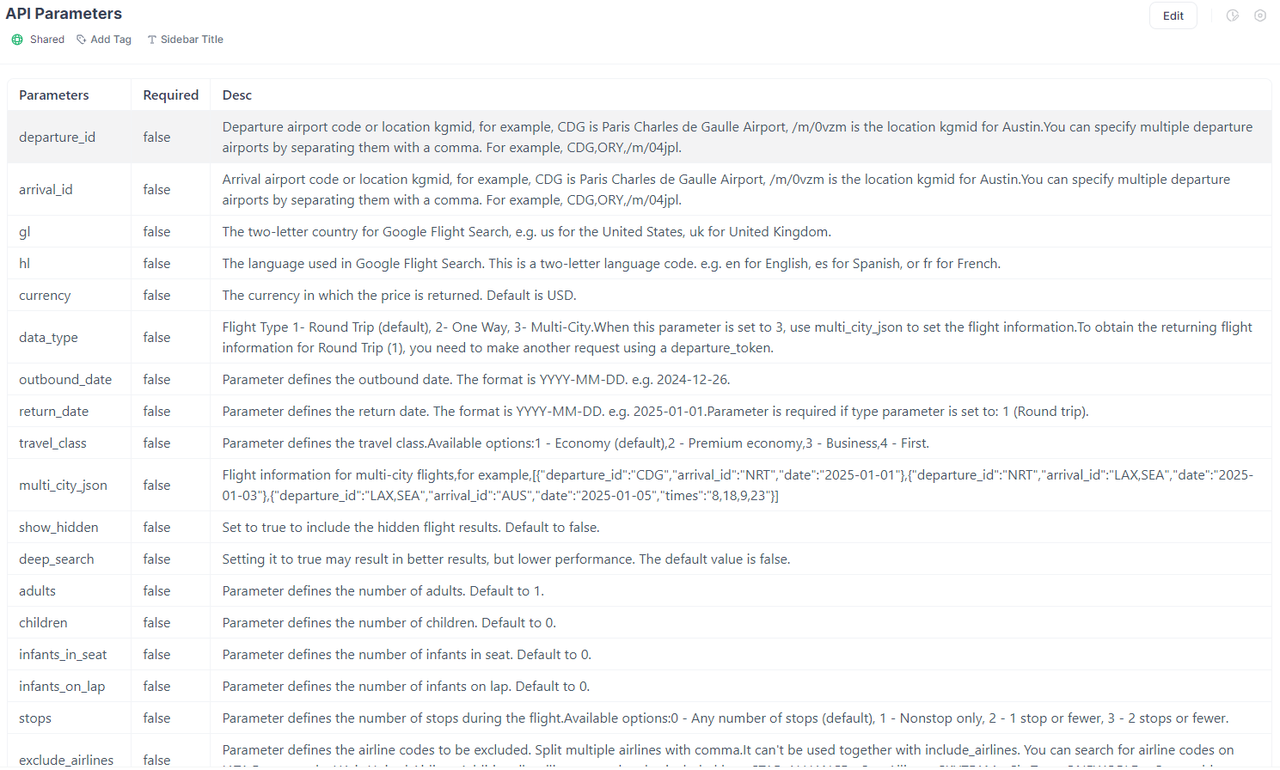
We can get a lot of data from the Scrapeless Google Flights API, such as:
- Departure and arrival time
- Airport information
- Flight duration
- Carbon emission information
- Price
- Stopover information
- Airline information
- And so on.
If you need to export the results to CSV, just add the following code.
result = response.json()
best_flights = result['best_flights']
with open('flights-maps-results.csv', 'w', newline='') as csvfile:
csv_writer = csv.writer(csvfile)
# Write the headers
csv_writer.writerow(["departure_time", "arrival_time", "flight_number", "price"])
# Write the data
for best_flight in best_flights:
flights = best_flight['flights']
for flight in flights:
departure_airport = flight['departure_airport']
arrival_airport = flight['arrival_airport']
csv_writer.writerow(
[departure_airport["time"], arrival_airport["time"], flight["flight_number"], best_flight["price"]])
print('Done writing to CSV file.')
Scrapeless provides you with a variety of crawling scenarios, including the Kayak flight time and price information shown above. Scrapeless also provides information such as ''Other Departing Flights, historical price trends, etc. You only need to construct different parameters:
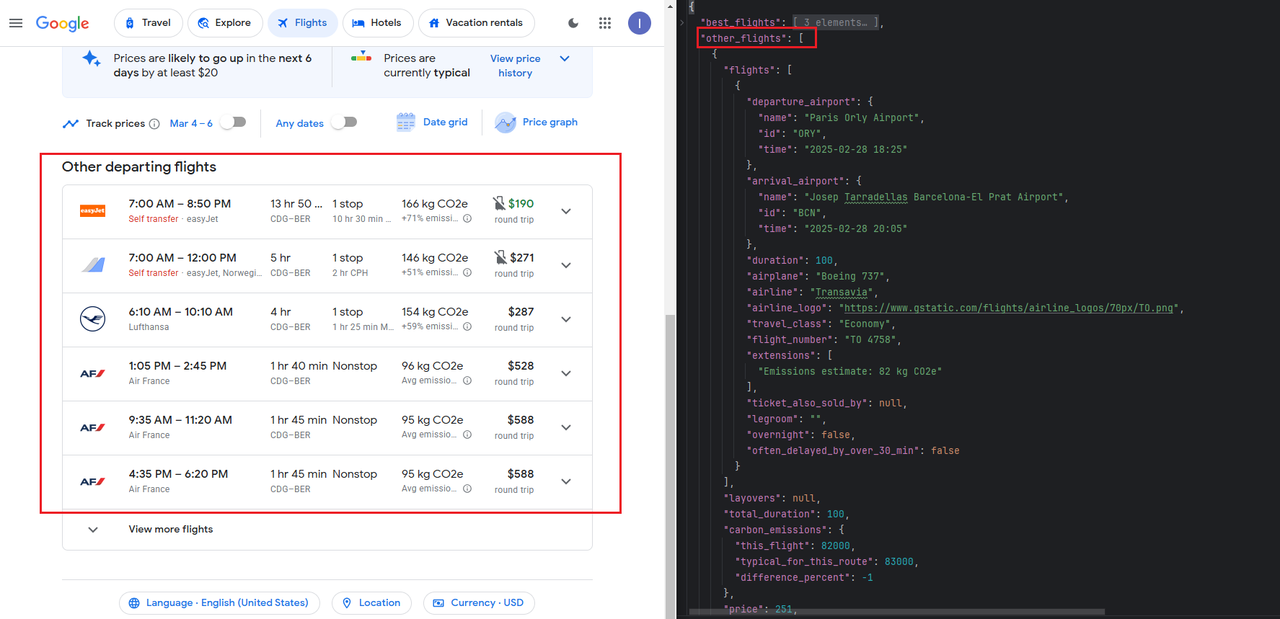
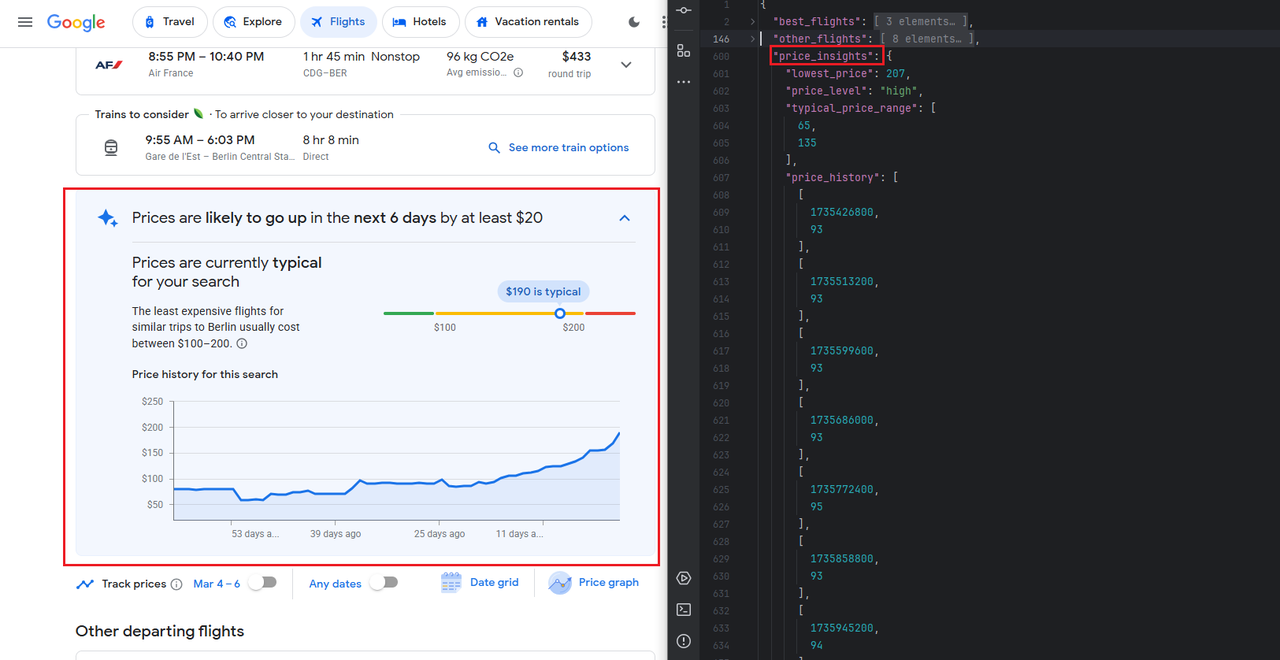
In addition, Scrapeless also provides the following data interfaces:
- Google Maps
- Google Jobs
- Google Trends
- Google Hotel ...
Deep SerpApi is a dedicated search engine designed for large language models (LLMs) and AI agents, aiming to provide real-time, accurate, and fair information to help AI applications efficiently retrieve and process data.
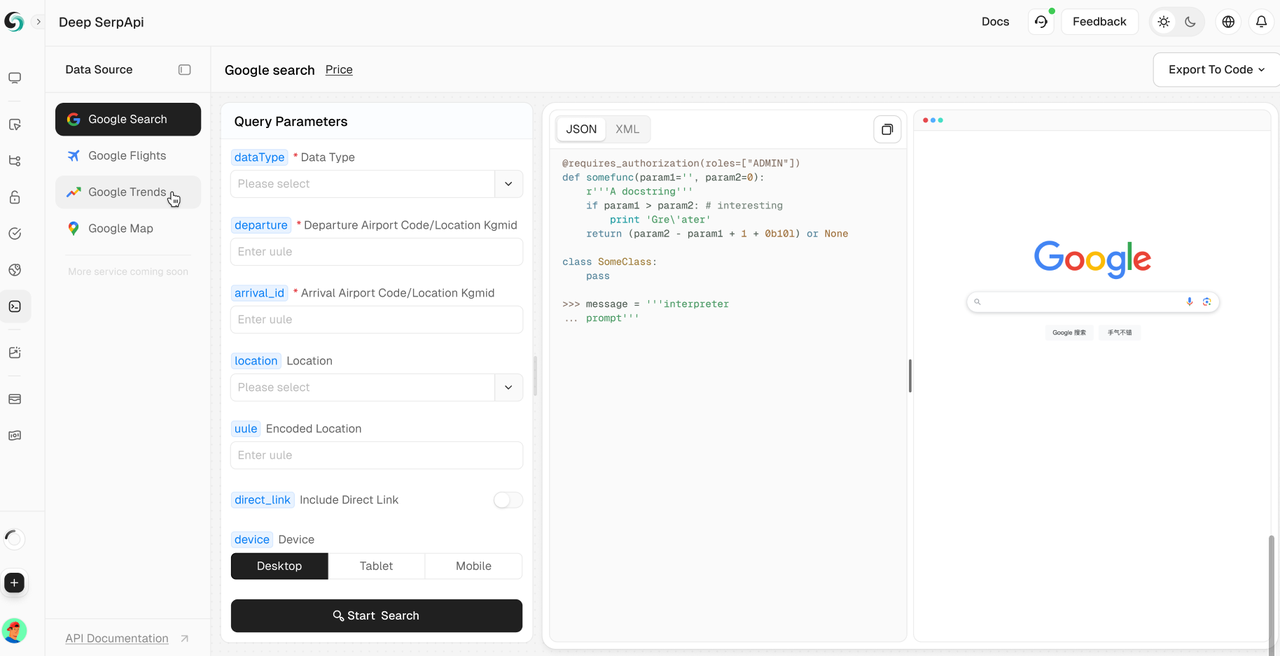
Main features:
- Comprehensive data coverage and high-value crawling: Built-in 20+ Google Search API scenario interfaces, access to data from mainstream search engines.
- Real-time data update: Supports historical data updates for the past 24 hours to ensure the latest information.
- Cost-effective: Deep SerpApi offers pricing from $0.10 per thousand queries, with a response time of 1-2 seconds, allowing developers and enterprises to obtain data efficiently and at low cost.
- Advanced data integration capabilities: Can integrate information from all available online channels and search engines.
🎺🎺Exciting Announcement! Developer Support Program: Integrate Scrapeless Deep SerpApi into your AI tools, applications or projects. [We already support Dify, and will soon support Langchain, Langflow, FlowiseAI and other frameworks]. Then share your results on GitHub or social media, and you will receive free developer support for 1-12 months, up to $500 per month.
If you are interested in other Google scraping techniques, you can read the following detailed articles:
- How to scrape Google Scholar results
- How to scrape Google job results
- How to scrape Google Map results
In conclusion, scraping flight data from Kayak provides valuable insights for travelers and businesses. By using the right tools and ethical practices, you can easily collect real-time data.
Ready to dive in? Join our Discord community for more tips and advice.