Brandon Trabucco (1) Gunnar Sigurdsson (2) Robinson Piramuthu (2) Ruslan Salakhutdinov (1)
(1) Carnegie Mellon University, Machine Learning Department (2) Amazon
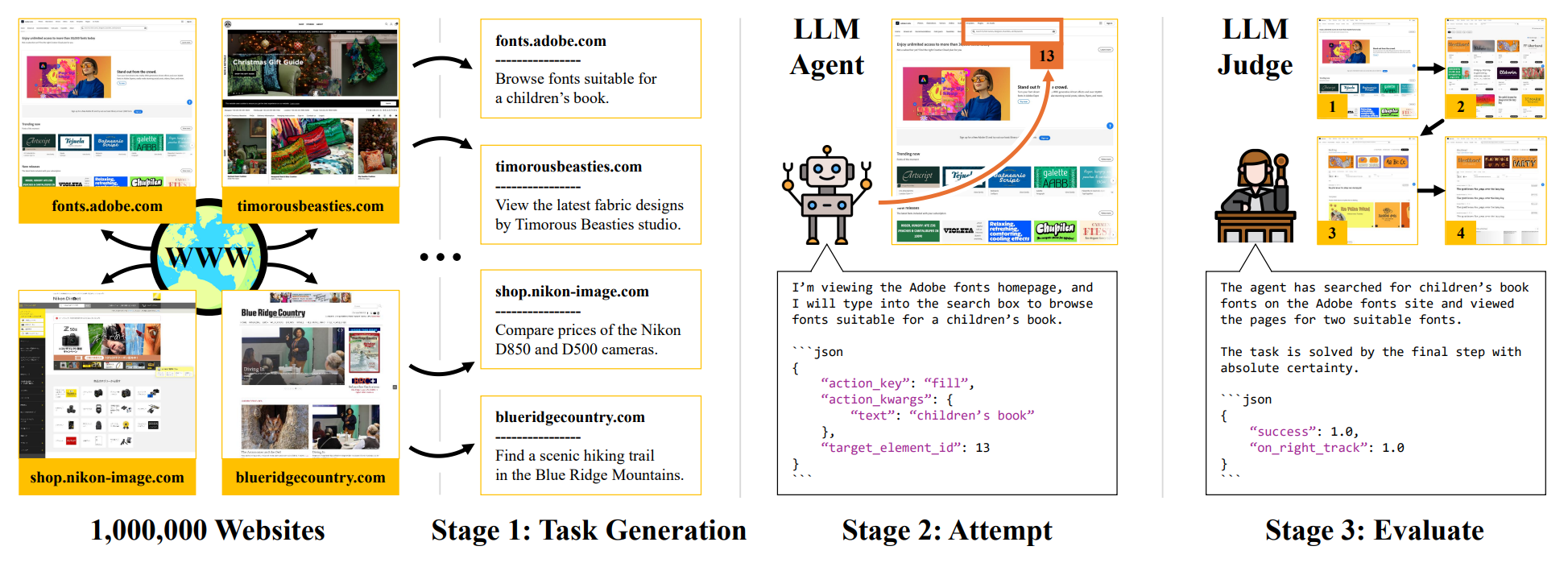
The predominant approach for training web navigation agents is to gather human demonstrations for a set of popular websites and hand-written tasks, but it is becoming clear that human data is an inefficient resource. We develop a pipeline to facilitate internet-scale training for agents without laborious human annotations. In the first stage, an LLM annotates 150k sites with agentic tasks. In the next stage, LLM agents complete tasks and produce trajectories. In the final stage, an LLM filters trajectories by judging their success. Language models are powerful data curation tools, identifying harmful content with an accuracy of 97%, judging successful trajectories with an accuracy of 82.6%, and producing effective data. We train agents based on Qwen 3 1.7B that are competitive with frontier LLMs as web agents, while being smaller and faster. Our top agent reaches a success rate of 56.9%, outperforming the data collection policy Qwen 3 235B, a 235 times larger Llama 4 Maverick, and reaching 94.7% of the performance of Gemini 2.5 Flash. We are releasing code, models and data at: data-for-agents.github.io.
This is the official code for InSTA, and can be used to reproduce our paper, and scale training for web agents. The repository has the following capabilities.
- Data Collection: 150,000 trajectories in 24 hours on 50 L40S GPUs
- Training: beats Llama 4 Maverick with a 1.7B model
- Inference: serves our 1.7B web agent that operates a virtual web browser.
The quickest way to start is to download and install the code:
git clone https://github.com/data-for-agents/insta
cd insta && pip install -e .And start the local web agent endpoint:
bash gradio/start_agent.shYou can view the frontend at http://localhost:7860. This application allows you to specify an initial_url and an instruction for an LLM web agent. The agent will then operate a virtual web browser to complete the instruction, and produces a final agent response, and a video of the trajectory.
The quickest way to start developing new agents is to launch the environment:
docker pull brandontrabucco/insta-browser-environment
docker run -p 7860:7860 -p 3000-3007:3000-3007 -t brandontrabucco/insta-browser-environment &Then, you can run various LLMs via the LLM client args:
from insta import (
get_agent_config,
get_judge_config,
get_browser_config,
InstaPipeline
)
import os
agent_client_kwargs = {
"api_key": os.environ.get("OPENAI_API_KEY"),
"base_url": "https://api.openai.com/v1"
}
agent_generation_kwargs = {
"model": "gpt-4.1",
"max_tokens": 1024,
"top_p": 1.0,
"temperature": 0.5
}
agent_config = get_agent_config(
client_kwargs = agent_client_kwargs,
generation_kwargs = agent_generation_kwargs
)
judge_client_kwargs = {
"api_key": os.environ.get("OPENAI_API_KEY"),
"base_url": "https://api.openai.com/v1"
}
judge_generation_kwargs = {
"model": "gpt-4.1-nano",
"max_tokens": 1024,
"top_p": 1.0,
"temperature": 0.5
}
judge_config = get_judge_config(
client_kwargs = judge_client_kwargs,
generation_kwargs = judge_generation_kwargs
)
dataset = [
{"website": "duckduckgo.com", "instruction": "retrieve a news article on US politics"},
]
pipeline = InstaPipeline(
agent_config = agent_config,
judge_config = judge_config
)
trajectories = pipeline.launch(
dataset = dataset
)The trajectories variable returned by the pipeline is a list of InstaPipelineOutput instances, which are named tuples with observations, actions, and judgment keys. The observations key points to a list, where each element is a dict containing text, screenshots, and metadata from the browser. The actions key points to a list, where each element is a dict containing the LLM agent response, and parsed action. Finally, the judgment key points to a dict containing scores from the judge, which can be used to filter the data.
The InstaPipeline is the main entry point for this code, and can serve as an efficient distributed rollout pipeline for data collection, and an efficient serving engine for runninh your trained agents.
Please cite our work using the following bibtex:
@misc{Trabucco2025InSTA,
title={InSTA: Towards Internet-Scale Training For Agents},
author={Brandon Trabucco and Gunnar Sigurdsson and Robinson Piramuthu and Ruslan Salakhutdinov},
year={2025},
eprint={2502.06776},
archivePrefix={arXiv},
primaryClass={cs.LG},
}