For a live demo of the application, visit: HomeValueAI
Full Detail of Project on YouTube: Videolink
- Project Overview
- Getting Started
- Data Collection and Preprocessing
- Machine Learning Modeling
- Deployment and Web Application
- Technical Stack
- Dataset Details
- Project Workflow
- SQL Integration
- Visualization and Insights
- Screenshots
- Contact
HomeValueAI is an advanced machine learning project designed to accurately predict real estate prices across major cities in Pakistan. This end-to-end project demonstrates expertise in data engineering, exploratory data analysis, machine learning, and web deployment, providing valuable insights and tools for stakeholders in the real estate industry.
The project leverages comprehensive real estate data from Zameen.com, integrating sophisticated algorithms and interactive web technologies to deliver a seamless user experience for real-time property valuation.
Follow these instructions to set up the HomeValueAI project on your local machine for development and testing purposes.
Ensure you have the following software installed on your system:
- Python 3.9 or higher
- Git
- Virtual Environment tool (e.g.,
venv,virtualenv, orconda) - Microsoft SQL Server (optional, only if you intend to perform data preprocessing steps)
- Power BI Desktop (optional, for data visualization purposes)
Clone the project repository from GitHub to your local machine using the following command:
git clone https://github.com/whoisusmanali/HomeValueAI.gitcd HomeValueAIIt's recommended to use a virtual environment to manage dependencies. Create and activate a virtual environment using one of the following methods:
Using venv:
# Create virtual environment
python3 -m venv venv
# Activate virtual environment (Linux/Mac)
source venv/bin/activate
# Activate virtual environment (Windows)
venv\Scripts\activateUsing conda:
# Create virtual environment
conda create -n homevalueai python=3.8
# Activate virtual environment
conda activate homevalueaiInstall all required Python packages using the requirements.txt file:
pip install -r requirements.txtCreate a .env file in the root directory to store necessary environment variables:
touch .envAdd the following configurations to the .env file:
FLASK_APP=app.py
FLASK_ENV=development
SECRET_KEY=your_secret_key
DATABASE_URL=your_database_connection_string # If using SQL ServerReplace your_secret_key and your_database_connection_string with your actual credentials.
Ensure that the dataset required for predictions is available in the appropriate directory:
- Place your cleaned and preprocessed dataset in the
data/directory. - If starting from raw data, run the preprocessing scripts provided in the
scripts/directory.
Note: Detailed data preprocessing steps are outlined in the Data Collection and Preprocessing section.
Run the Flask application using the following command:
flask runOr use Gunicorn for a production-ready server:
gunicorn app:appOnce the server is running, access the web application by navigating to:
http://127.0.0.1:5000/Features:
- Home Page: Provides an overview and allows users to input property details.
- Prediction Page: Displays the predicted property price based on user inputs.
- Visualization Dashboard: Showcases interactive charts and graphs for data insights.
The dataset was meticulously sourced from Zameen.com, encompassing diverse property listings across major Pakistani cities.
Steps Involved:
- Data Ingestion: Collected raw data using web scraping techniques and APIs where applicable.
- Data Storage: Stored the raw data in Microsoft SQL Server for robust and efficient handling.
- Data Cleaning:
- Handled missing and null values through imputation and removal strategies.
- Removed duplicate entries to ensure data integrity.
- Corrected inconsistent data types and formats.
- Feature Engineering:
- Created new features such as price per square foot, location desirability scores, and proximity indicators.
- Transformed categorical variables using encoding techniques (e.g., One-Hot Encoding).
- Exploratory Data Analysis (EDA):
- Conducted thorough EDA using Pandas, NumPy, Matplotlib, and Seaborn to uncover underlying patterns and correlations.
- Utilized Plotly for interactive and dynamic visualizations.
- Data Splitting:
- Split the dataset into training and testing sets to evaluate model performance effectively.
Detailed scripts and notebooks for data preprocessing are available in the notebooks/ and scripts/ directories.
Building upon the clean and processed data, various machine learning models were developed and evaluated to determine the most effective approach for property price prediction.
Models Evaluated:
- Linear Regression
- Decision Tree Regressor
- Random Forest Regressor
- K-Nearest Neighbors (KNN)
- XGBoost Regressor
- Gradient Boosting Regressor
- AdaBoost Regressor
Model Evaluation Metrics:
- Mean Absolute Error (MAE)
- Mean Squared Error (MSE)
- Root Mean Squared Error (RMSE)
- R-squared (R²) Score
Best Performing Model:
- XGBoost Regressor
- Performance:
- R² Score: 0.92
- The model demonstrated superior performance due to its ability to handle complex non-linear relationships and manage overfitting effectively.
- Performance:
Model Serialization:
- The trained XGBoost model was serialized using Pickle for seamless integration into the web application.
To provide real-time access to the predictive capabilities of HomeValueAI, the model was deployed as a web application.
Deployment Details:
- Backend:
- Developed using Flask, facilitating RESTful API endpoints for prediction services.
- Implemented input validation and error handling to ensure robustness.
- Frontend:
- Designed with HTML, CSS, and Bootstrap for responsive and user-friendly interfaces.
- Integrated interactive elements and form validations for enhanced user experience.
- Hosting:
- Deployed on Microsoft Azure, offering scalable and reliable cloud infrastructure.
- Configured continuous integration and deployment pipelines for streamlined updates.
Security and Performance:
- Implemented security measures including input sanitation and secure handling of environment variables.
- Optimized performance through efficient code practices and resource management.
Programming Languages & Frameworks:
- Python 3.12
- Flask
- HTML5
- CSS3
- Bootstrap
Data Processing & Analysis:
- Pandas
- NumPy
- Scikit-learn
- XGBoost
- TensorFlow
- Keras
Visualization:
- Matplotlib
- Seaborn
- Plotly
- Power BI
Database & Storage:
- Microsoft SQL Server
DevOps & Deployment:
- Git & GitHub
- Microsoft Azure Cloud Platform
- Gunicorn (WSGI HTTP Server)
Others:
- Pickle (for model serialization)
- dotenv (for environment variable management)
- virtualenv/conda (for environment management)
- Requirement Analysis: Defined project objectives and success metrics.
- Data Acquisition: Gathered and stored raw data securely.
- Data Preprocessing: Cleaned and transformed data for optimal model performance.
- Exploratory Data Analysis: Identified key insights and informed feature selection.
- Feature Engineering: Enhanced dataset with additional relevant features.
- Model Development: Trained and fine-tuned various regression models.
- Model Evaluation: Assessed models using appropriate metrics and selected the best-performing one.
- Model Deployment: Integrated the model into a Flask application and deployed it on Render.
- Testing and Validation: Conducted thorough testing to ensure reliability and accuracy.
- Documentation: Prepared detailed documentation for users and developers.
- Maintenance and Updates: Established protocols for future updates and improvements.
Microsoft SQL Server was utilized extensively for data management tasks:
- Data Cleaning:
- Employed SQL queries to handle null values and enforce data integrity constraints.
- Data Transformation:
- Conducted aggregation, joins, and subqueries to restructure data effectively.
- Performance Optimization:
- Implemented indexing and query optimization techniques for efficient data retrieval.
Sample SQL scripts and queries are provided in the SQL Analysis and Cleaning/ directory.
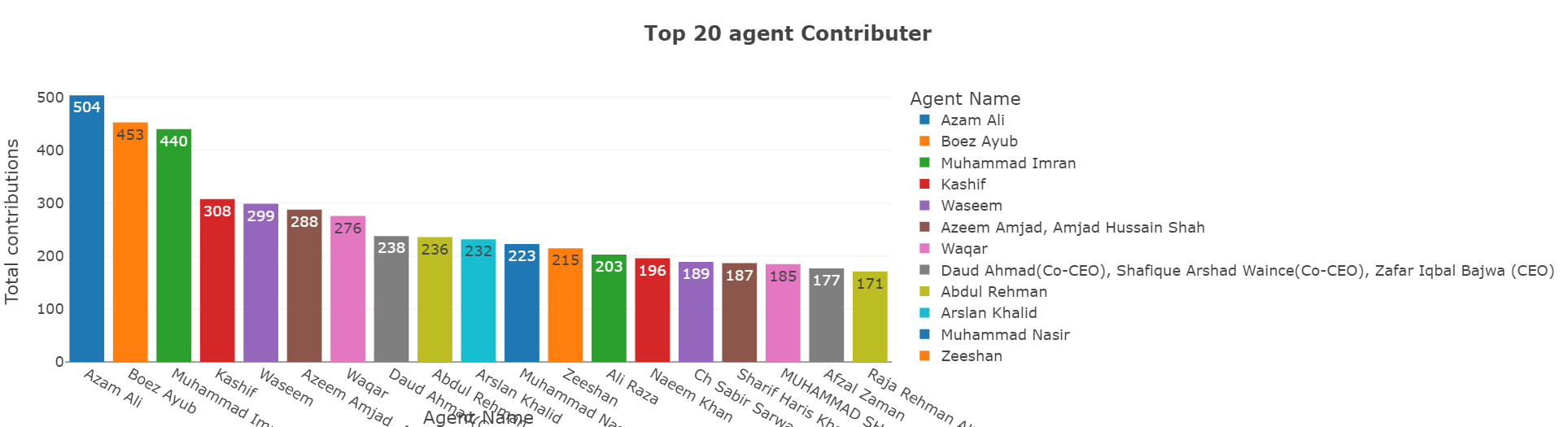
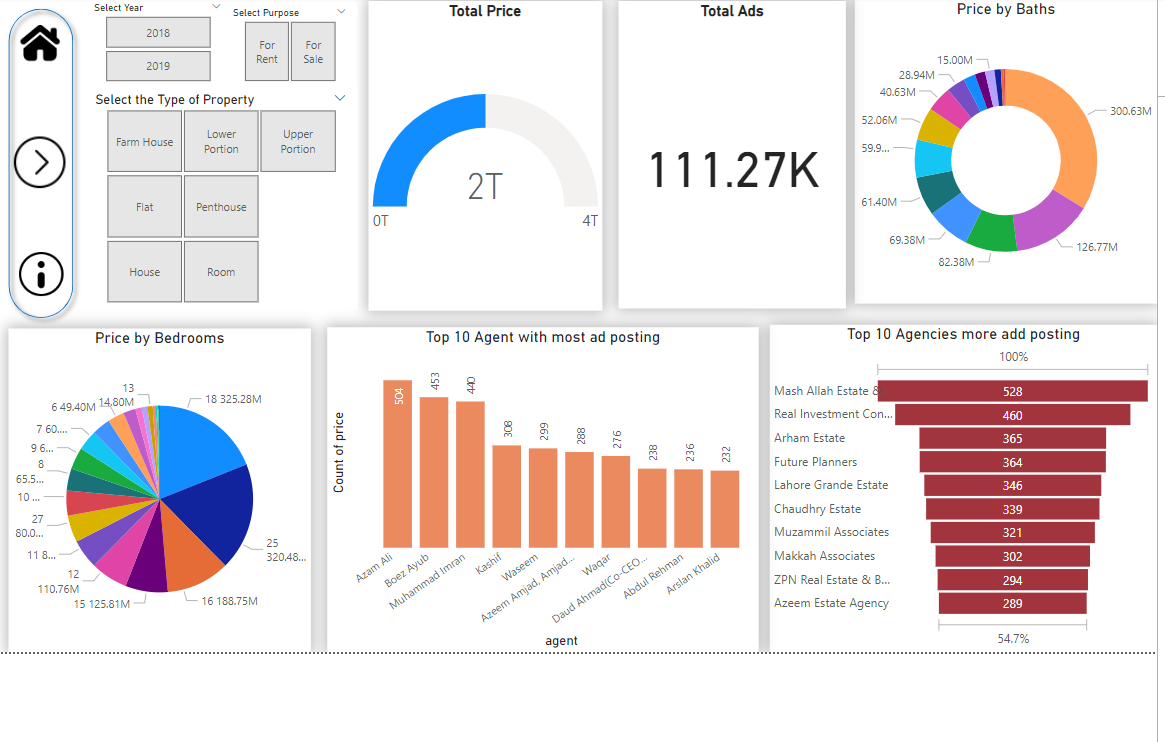
Power BI was leveraged to create interactive and insightful dashboards, aiding in:
- Market Trend Analysis:
- Visualized historical price trends across different cities and property types.
- Geospatial Analysis:
- Mapped property distributions and hotspots using latitude and longitude data.
- Feature Impact:
- Illustrated the influence of various features on property prices through heatmaps and scatter plots.
- Stakeholder Reporting:
- Generated comprehensive reports facilitating data-driven decision-making.
Power BI files and exported visuals are available in the Visualization with Power BU/ directory.

Your Name
- Email: whoisusmanali@gmail.com
- LinkedIn: LinkedIn Profile
- GitHub: GitHub Profile
- Portfolio: Portfolio Website
Feel free to reach out for collaboration, queries, or any opportunities related to data science and machine learning.