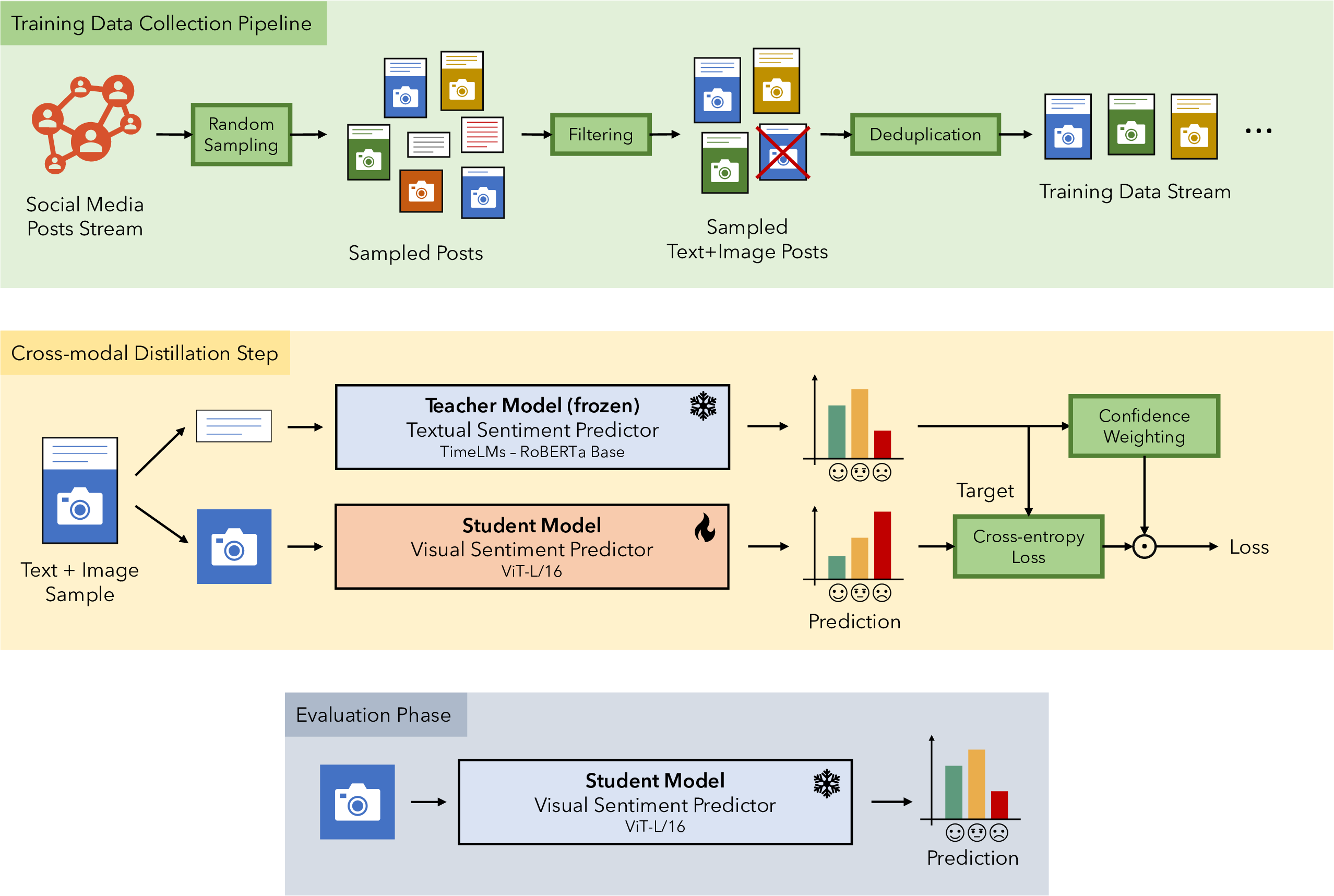
This work introduces T4SA 2.0, a comprehensive dataset and cross-modal learning method for training visual models for Sentiment Analysis in the Twitter domain.
Our approach fine-tunes Vision-Transformer (ViT) models pre-trained on ImageNet-21k, achieving remarkable results on external benchmarks with manual annotations, even surpassing the current State-of-the-Art!
- 🎯 Cross-modal distillation: Leverages both visual and textual information from social media
- 📊 Large-scale dataset: ~3.7M images crawled from April 1 to June 30
- 🤖 Automated labeling: Uses distant supervision to minimize human annotation efforts
- 🏆 SOTA performance: Beats current state-of-the-art on multiple benchmarks
- 🔧 Ready-to-use models: Pre-trained models available for immediate deployment
The cross-modal teacher-student learning technique eliminates the need for human annotators while enabling the creation of vast training sets, supporting future research in training robust visual models as parameter counts continue to grow exponentially.
- Python 3.7+
- CUDA-compatible GPU (recommended)
-
Clone the repository
git config --global http.postBuffer 1048576000 git clone --recursive https://github.com/fabiocarrara/cross-modal-visual-sentiment-analysis.git cd cross-modal-visual-sentiment-analysis -
Create a virtual environment (recommended)
python -m venv venv source venv/bin/activate -
Install Python dependencies
pip install --upgrade pip pip install -r requirements.txt
-
Install system dependencies (Linux/Ubuntu)
chmod +x setup.sh sudo ./setup.sh
python3 scripts/test_benchmark.py -m <model_name> -b <benchmark_name>Available models:
boosted_model(recommended)ViT_L16,ViT_L32,ViT_B16,ViT_B32merged_T4SA,bal_flat_T4SA2.0,bal_T4SA2.0,unb_T4SA2.0B-T4SA_1.0_upd_filt,B-T4SA_1.0_upd,B-T4SA_1.0
Available benchmarks:
5agree,4agree,3agreeFI_complete,emotion_ROI_test,twitter_testing_2
python3 scripts/5_fold_cross.py -b <benchmark_name>Returns mean accuracy, standard deviation, and saves predictions
python3 scripts/fine_tune_FI.py.
├── dataset/
│ ├── benchmark/
│ │ ├── EmotionROI/
│ │ │ └── images/
│ │ │ ├── anger/
│ │ │ ├── disgust/
│ │ │ ├── fear/
│ │ │ ├── joy/
│ │ │ ├── sadness/
│ │ │ └── surprise/
│ │ ├── FI/
│ │ │ ├── images/
│ │ │ │ ├── amusement/
│ │ │ │ ├── anger/
│ │ │ │ ├── awe/
│ │ │ │ ├── contentment/
│ │ │ │ ├── disgust/
│ │ │ │ ├── excitement/
│ │ │ │ ├── fear/
│ │ │ │ └── sadness/
│ │ │ ├── split_1/ ... split_5/
│ │ ├── Twitter Testing Dataset I/
│ │ └── Twitter Testing Dataset II/
│ ├── t4sa 1.0/
│ │ ├── dataset with new labels/
│ │ └── original dataset/
│ └── t4sa 2.0/
│ ├── bal_T4SA2.0/
│ ├── bal_flat_T4SA2.0/
│ ├── img/
│ ├── merged_T4SA/
│ └── unb_T4SA2.0/
├── models/
├── notebooks/
├── predictions/
├── scripts/
├── requirements.txt
├── setup.sh
└── README.md
Our models achieve state-of-the-art performance on Twitter sentiment analysis benchmarks:
| Confidence Filter Threshold | Accuracy on Twitter Dataset (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | Dataset | Pos | Neu | Neg | Architecture | 5 agree | ≥4 agree | ≥3 agree |
| Model 3.1 | A | - | - | - | ViT-B/32 | 82.2 | 78.0 | 75.5 |
| Model 3.2 | A | 0.70 | 0.70 | 0.70 | ViT-B/32 | 84.7 | 79.7 | 76.6 |
| Model 3.3 | B | 0.70 | 0.70 | 0.70 | ViT-B/32 | 82.3 | 78.7 | 75.3 |
| Model 3.4 | B | 0.90 | 0.90 | 0.70 | ViT-B/32 | 84.4 | 80.3 | 77.1 |
| Model 3.5 | A+B | 0.90 | 0.90 | 0.70 | ViT-B/32 | 86.5 | 82.6 | 78.9 |
| Model 3.6 | A+B | 0.90 | 0.90 | 0.70 | ViT-L/32 | 85.0 | 82.4 | 79.4 |
| Model 3.7 | A+B | 0.90 | 0.90 | 0.70 | ViT-B/16 | 87.0 | 83.1 | 79.4 |
| Model 3.8 | A+B | 0.90 | 0.90 | 0.70 | ViT-L/16 | 87.8 | 84.8 | 81.9 |
Best performing model: ViT-L/16 (Model 3.8) achieves 87.8% accuracy on the most challenging 5-agreement benchmark.
The T4SA 2.0 dataset will be made available soon. It contains:
- ~3.7M images from Twitter
- Cross-modal annotations using distant supervision
- Multiple confidence thresholds for different use cases
- Balanced and unbalanced versions
This project is licensed under the MIT License - see the LICENSE file for details.
If you use this work in your research, please cite:
@inproceedings{serra2023emotions,
author = {Serra, Alessio and Carrara, Fabio and Tesconi, Maurizio and Falchi, Fabrizio},
editor = {Kobi Gal and Ann Now{\'{e}} and Grzegorz J. Nalepa and Roy Fairstein and Roxana Radulescu},
title = {The Emotions of the Crowd: Learning Image Sentiment from Tweets via Cross-Modal Distillation},
booktitle = {{ECAI} 2023 - 26th European Conference on Artificial Intelligence, September 30 - October 4, 2023, Krak{\'{o}}w, Poland - Including 12th Conference on Prestigious Applications of Intelligent Systems ({PAIS} 2023)},
series = {Frontiers in Artificial Intelligence and Applications},
volume = {372},
pages = {2089--2096},
publisher = {{IOS} Press},
year = {2023},
url = {https://doi.org/10.3233/FAIA230503},
doi = {10.3233/FAIA230503},
}