In this project, I will put my ETL skills to the test. Many of Amazon's shoppers depend on product reviews to make a purchase. Amazon makes these datasets publicly available. They are quite large and can exceed the capacity of local machines. One dataset alone contains over 1.5 million rows; with over 40 datasets, data analysis can be very demanding on the average local computer. My first goal will be to perform the ETL process completely in the cloud and upload a DataFrame to an RDS instance. My second goal will be to use PySpark or SQL to perform a statistical analysis of selected data.
Part 1 - Extract two Amazon customer review datasets, transform each dataset into four DataFrames, and load the DataFrames into an RDS instance.
-
Activate Spark, install params, and start a SparkSession.
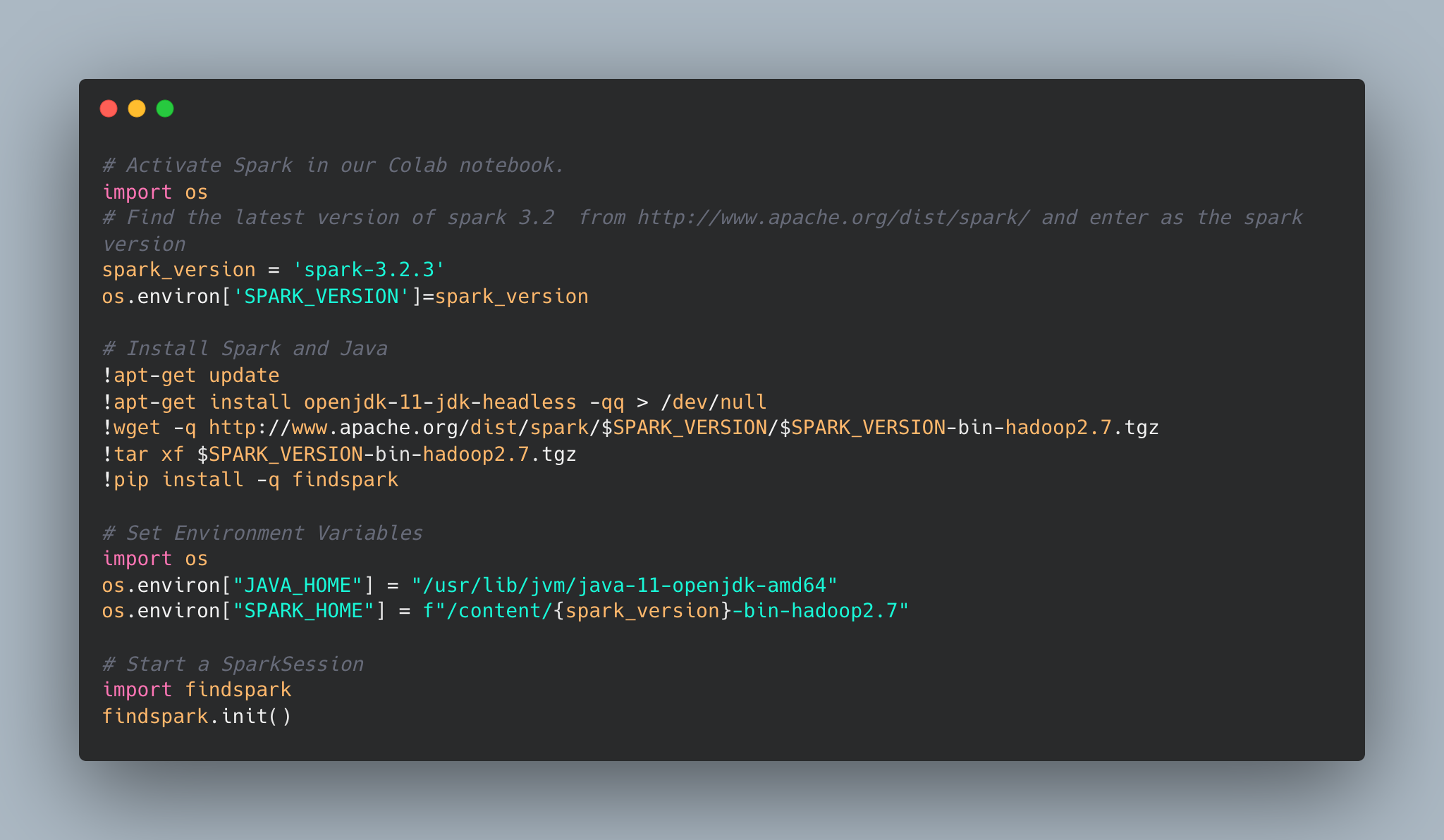
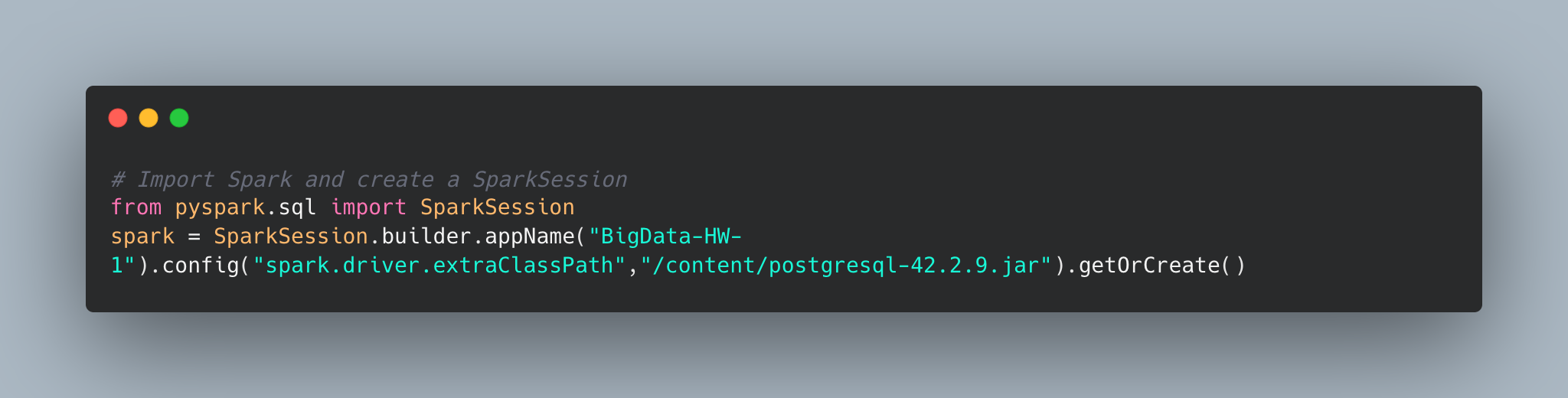
-
Explore the Amazon Reviews Links to an external site.datasets and pick two datasets to perform ETL.
-
Extract the Data
- Read in each dataset using the correct header and sep parameters.

- Get the number of rows in the dataset.

- Read in each dataset using the correct header and sep parameters.
-
Transform the Data


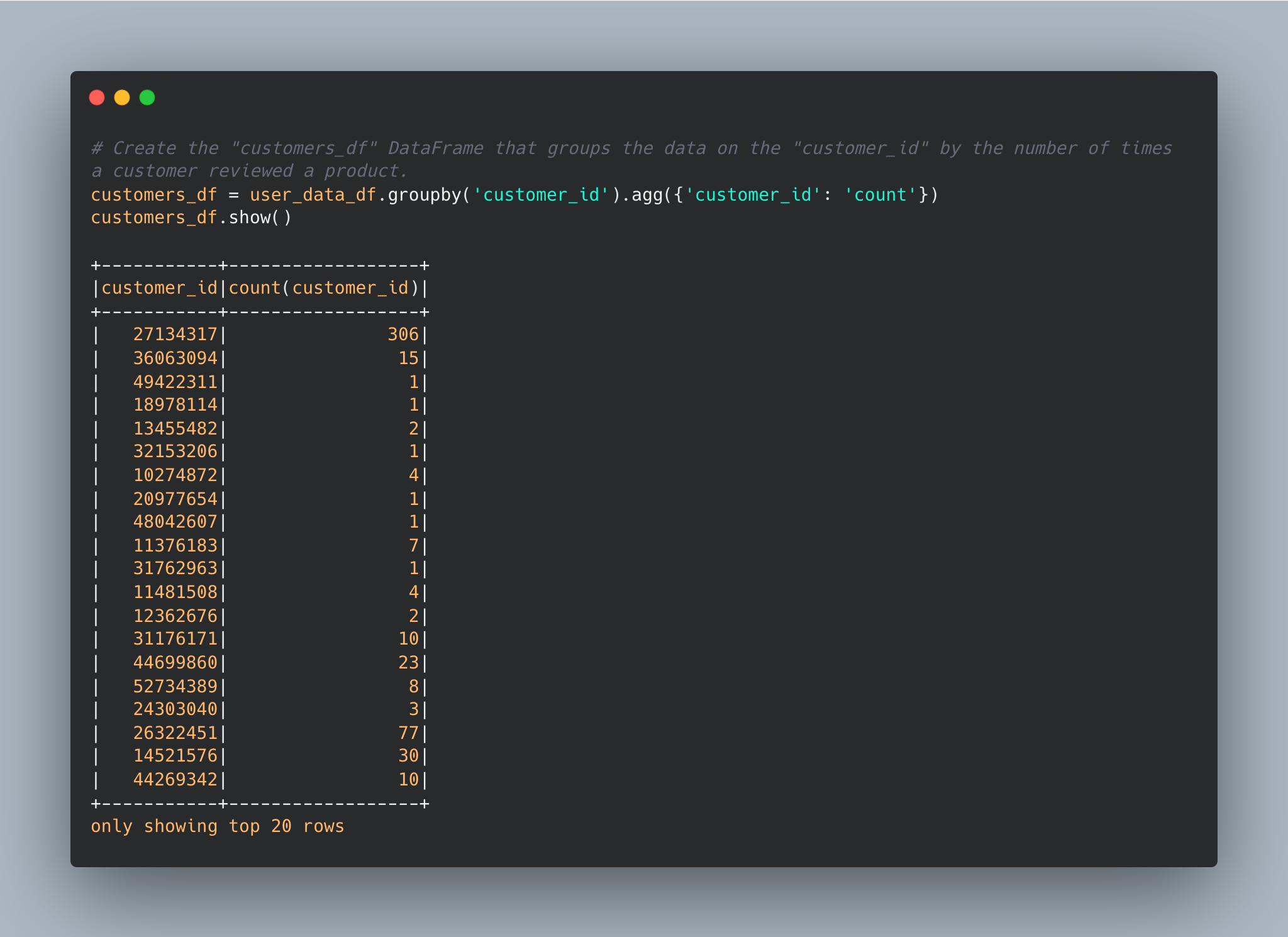

-
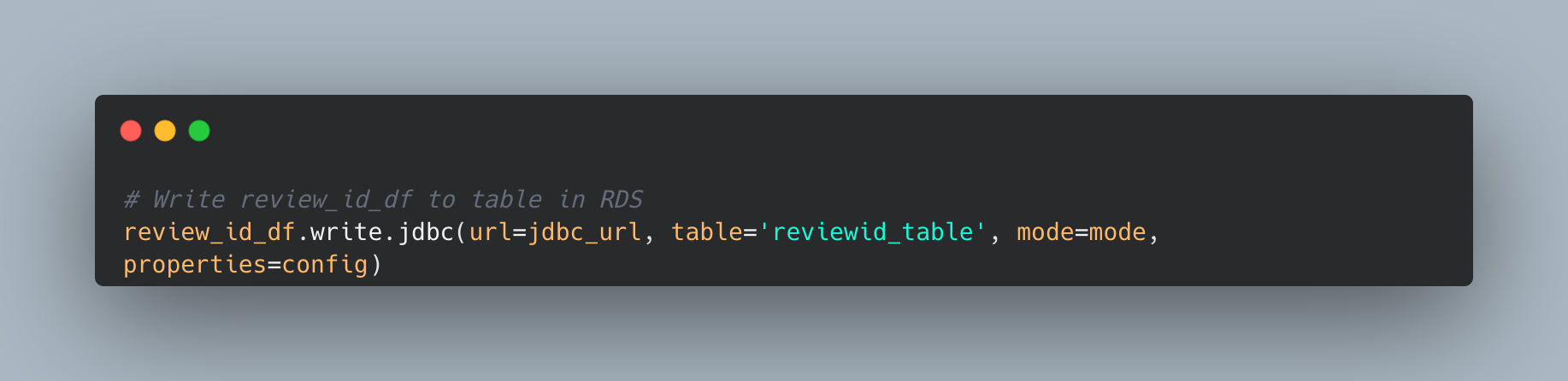
Load the Data into an RDS Instance
-
Export each DataFrame into the RDS instance to create four tables for each dataset.
Part 2 - Extract two Amazon customer review datasets and use either SQL or PySpark to analyze whether reviews from Amazon's Vine program are trustworthy.
In Amazon's Vine program, reviewers receive free products in exchange for reviews. Amazon has several policies to reduce the bias of its Vine reviews
But are Vine reviews truly trustworthy? Your task is to investigate whether Vine reviews are free of bias. Use either PySpark or, for an extra challenge, SQL to analyze the data.
If you choose SQL, first use Spark on Colab to extract and transform the data and then load it into a SQL table on your RDS account. Perform your analysis with SQL queries on RDS.
While there are no strict requirements for the analysis, consider steps you can take to reduce noisy data, such as filtering for reviews that meet a certain number of helpful votes, total votes, or both.
Submit a summary of your findings and analysis.
References Amazon Customer Reviews Dataset. (n.d.). Retrieved April 08, 2021, from: https://s3.amazonaws.com/amazon-reviews-pds/readme.html