Personal Project - NBA Data Analysis using machine learning, web scraping, and Python visualization
Data: Every single NBA player's stats and their likelihood of being voted as MVP from the years 1991-2021. The chance of winning MVP is measured using the award_share column. Value between 0 and 1 derived from voting panel. This model can predict voting panel scores for MVP candidates with a 97% accuracy rate using player information such as 3Pt percentage, assists, blocks, steals, freethrow percentage, etc during a season.

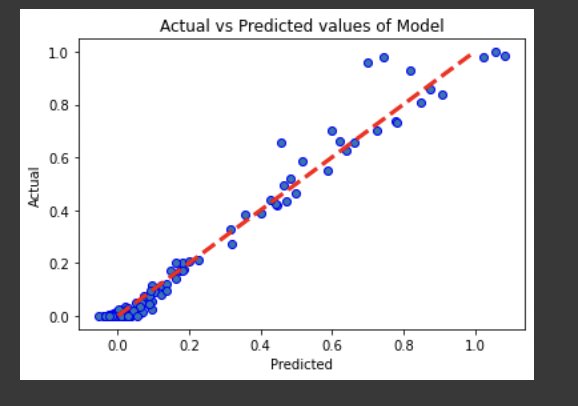
Various statistical tests including R^2, MSE, RMS demonstrate error rate < 4%. Strong R^2 value .97 close to 1. Graph of actual and predicted values of MVP voting points is very similar, with most predicted values lying on actual values line.
#################################################
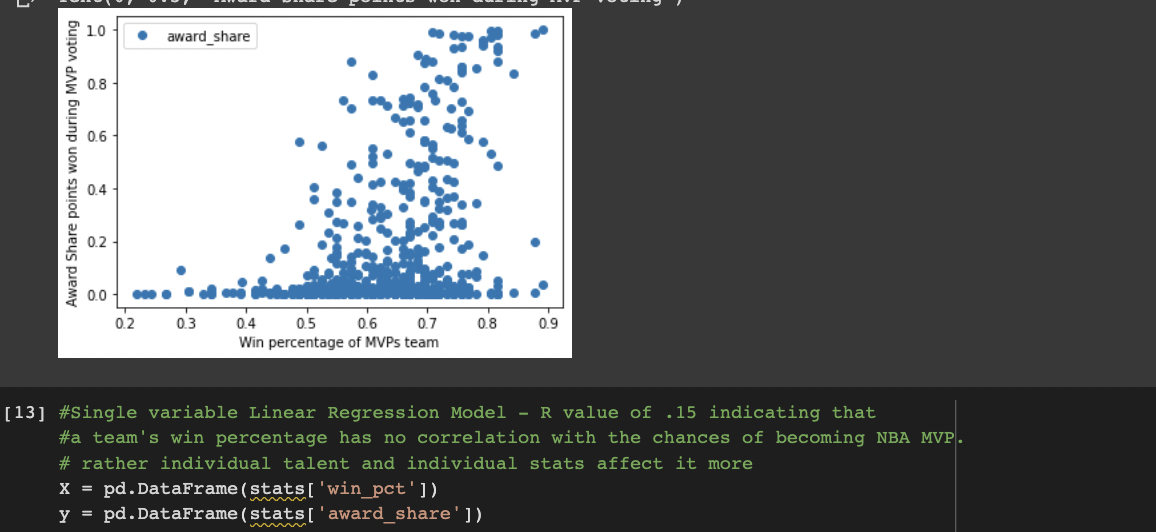
Single variable linear regression. Asseses how the win percentage of a candidate's team determines their chance of winning MVP. Poor r^2 value of .15 demonstrates no correlation. Scatter plot also demonstrates points all over the place with no line of best fit.

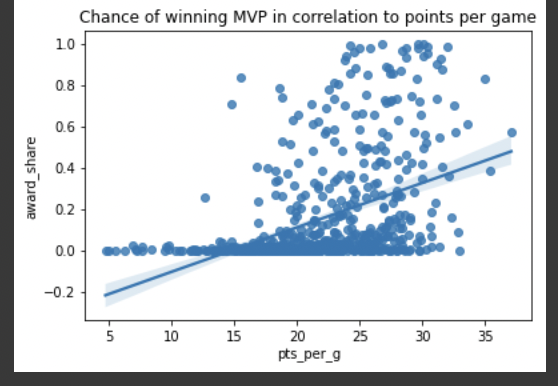
Rather this model allows us to infer that MVP is purely based on an individual player's performance rather than team performance. Graph of player's points per game and likelihoodof winning MVP shows strong positive correlation. Logistic regression model demonstrated poor correlations and statistics, indicating it is incorrect choice of prediction.
PART 2 of Project: Web Scraping
Scraped Golden State Warrior's page on basketballreference.com and extracted roaster stats through python's beatiful soup library.
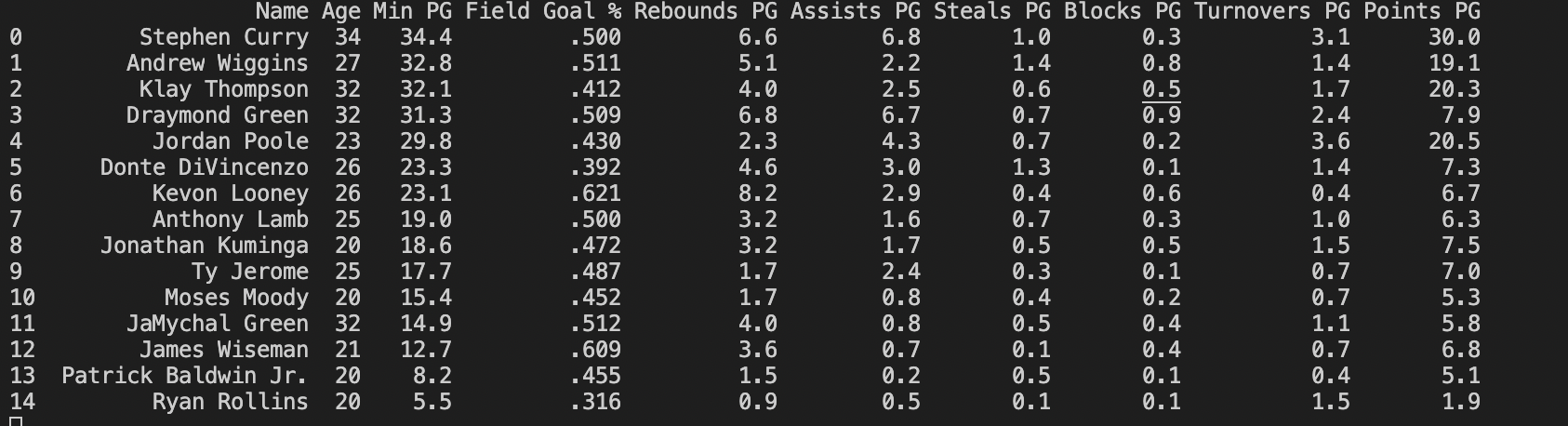
Iteratively extracted players individual person achievements by scraping their personal websites through URL data concatenation. Derived every warrior's player's achievement during their career. Also scraped personal demographic data such as height, weight, twitter handle, etc by iteratively scraping. Get_stats function on index.py provides every players data from 1991-2021 when a year in inputted.
