
Wendong Bu1,2*,
Yang Wu2*,
Qifan Yu1*,
Minghe Gao1,
Bingchen Miao1,
Zhenkui Zhang1,
Kaihang Pan1,
Yunfei Li2,
Mengze Li3,
Wei Ji4,
Juncheng Li1†,
Siliang Tang1,
Yueting Zhuang1,
1Zhejiang University, 2Antgroup, 3The Hong Kong University of Science and Technology, 4Nanjing University
- [June 5, 2025] We have released the exploration code for collecting subtask instructions in OmniBench, as well as the evaluation script used to evaluate virtual agents.
- Release paper.
- Release OmniBench virtual environment.
- Release test tasks for 10 capabilities in OmniBench.
- Release automated data collection pipeline.
- Release OmniBench-36K training data.
- Release training scripts.
Welcome to the GitHub repository for our paper titled "What Limits Virtual Agent Application? OmniBench: A Scalable Multi-Dimensional Benchmark of Essential Virtual Agent Capabilities". In this work, we introduce OmniBench, a self-generating, graph-based benchmark with an automated pipeline for synthesizing tasks of controllable complexity through subtask composition. To evaluate the diverse capabilities of virtual agents on the graph, we further present OmniEval, a multidimensional evaluation framework that includes subtask-level evaluation, graph-based metrics, and comprehensive tests across 10 capabilities. Our synthesized dataset contains 36k graph-structured tasks across 20 scenarios, achieving a 91% human acceptance rate. Training on our graph-structured data shows that it can more efficiently guide agents compared to manually annotated data. We conduct multidimensional evaluations for various open-source and closed-source models, revealing their performance across various capabilities and paving the way for future advancements.
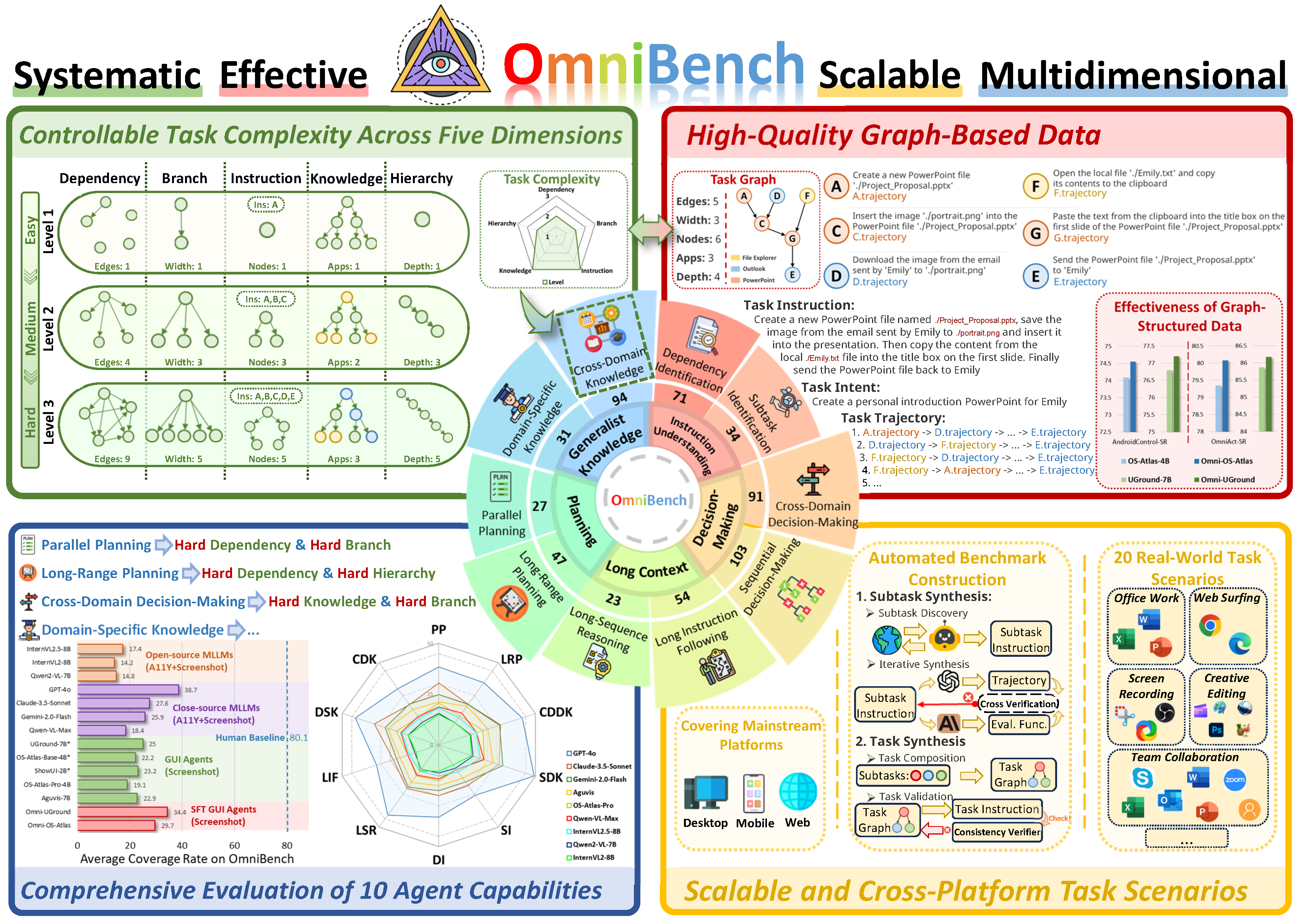
Overview of OmniBench, a systematic benchmark with five-dimensional task complexity and bottom-up automatic task synthesis for generating structured task graphs. It evaluates ten virtual agent capabilities using high-quality graph-based data, ensuring scalable and realistic task assessments.
We designed a bottom-up automated pipeline to synthesize tasks with controllable complexity. This pipeline consists of four processes:
(1) Subtask Discovery: First, we synthesize a series of simple subtask instructions from the explorable environment.
(2) Iterative Synthesis: Then, we iteratively synthesize subtask trajectories and evaluation functions.
(3) Task Composition: Next, the subtasks are combined into a task bottom-up.
(4) Task Validation: Finally, we validate the semantics of the tasks.
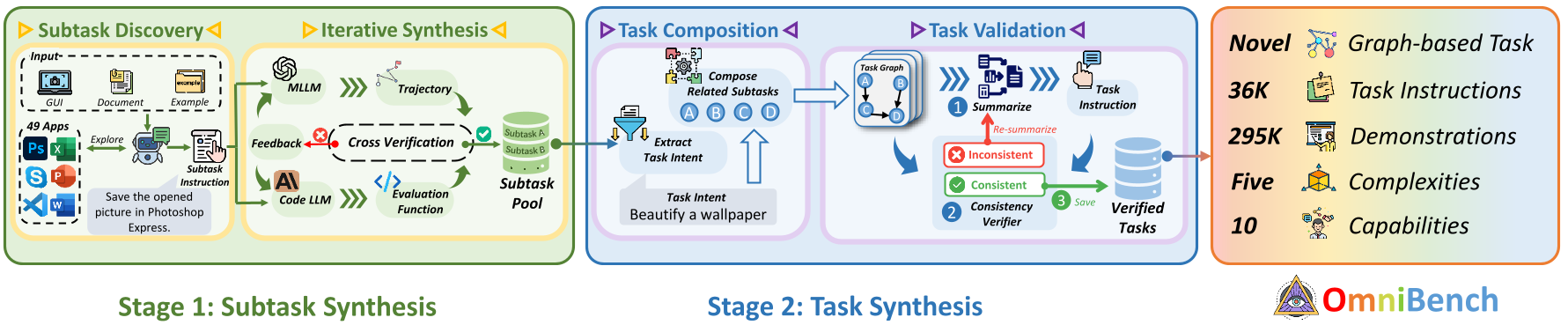
Bottom-up task synthesis pipeline of OmniBench.
We propose a graph-based multidimensional evaluation framework, OmniEval. In contrast to previous coarse-grained evaluation methods, we introduce a graph-based evaluator that applies subtask-level evaluation functions in OmniBench. Specifically, we design two novel fine-grained metrics to evaluate agents' performance on graph-structured tasks and their alignment with human logic. Based on OmniBench, we comprehensively evaluate 12 virtual agents, including both open-source and proprietary models, across all 10 capability dimensions as shown in the main figure, fully revealing the capability boundaries and providing concrete directions for future improvement.
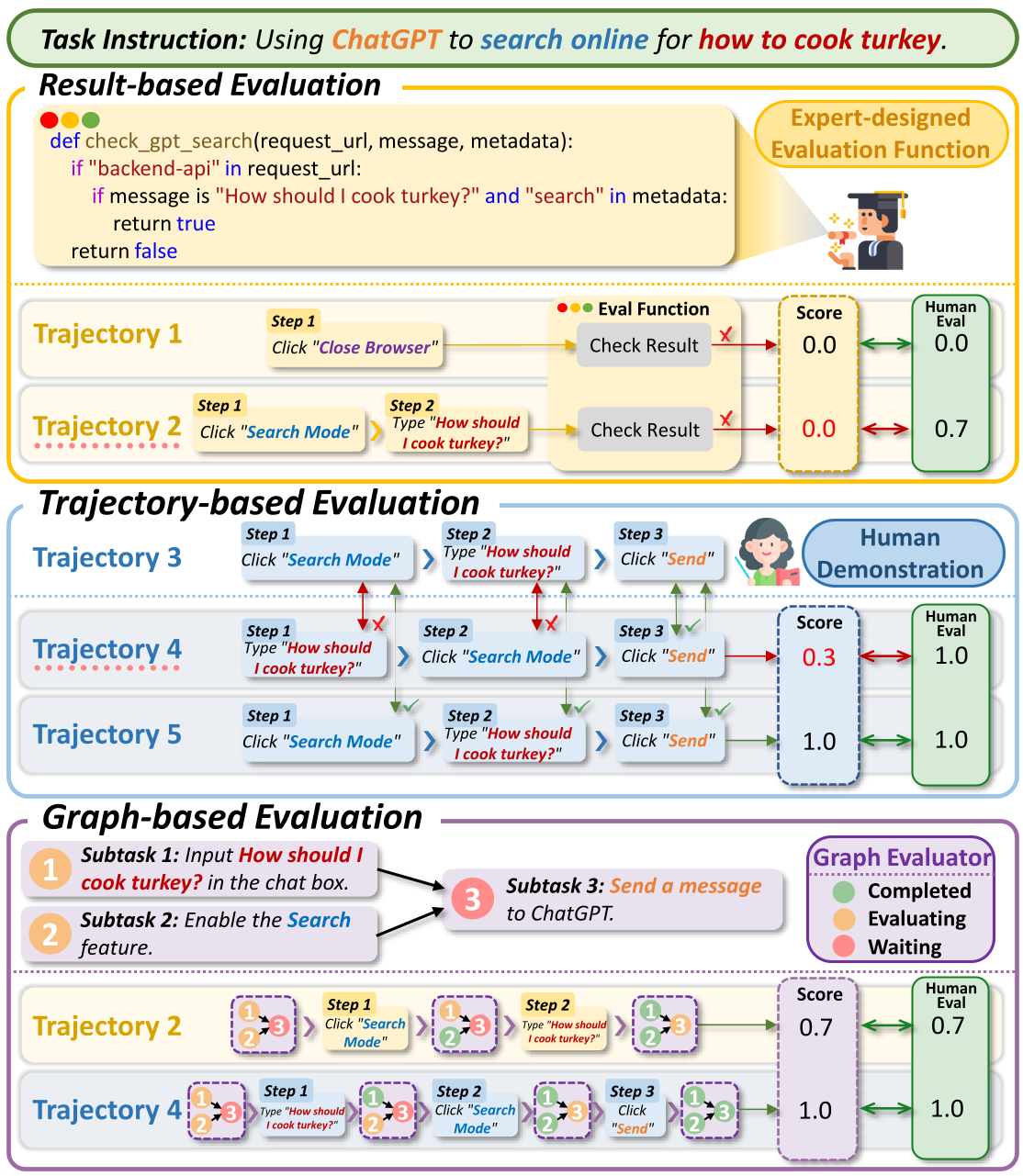
Comparison of mainstream virtual agent evaluation strategies with the evaluation strategy we propose.
We carefully examine some sampled error instances for each model from the OmniBench evaluation. Specifically, there are five types of errors:
(1) Instruction Understanding. We observe that 23% of the failures are due to the agent's misunderstanding of the instructions.
(2) Lack of Knowledge. We find that 21% of the failures are caused by the agent's lack of knowledge about the target application.
(3) Environmental Error. We observe that 3% of the failures result from environmental interference, such as network delays.
(4) Grounding Error. We find that 17% of the failures are due to the model's lack of grounding ability.
(5) Hallucinatory Success. Finally, 36% of the failures occur when the agent incorrectly assumes the task is complete.
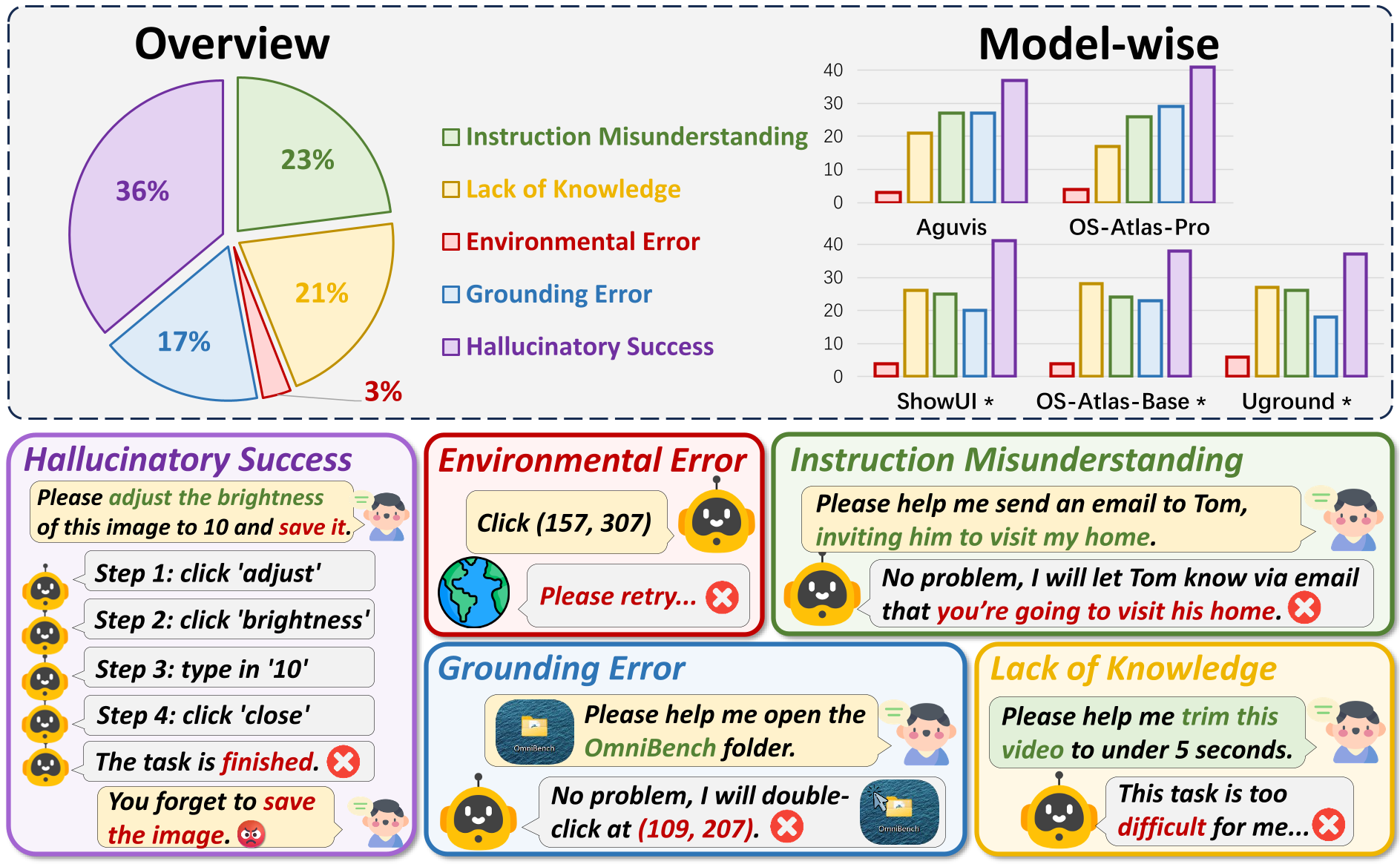
The top illustrates the distribution of the five main failure causes. The bottom presents examples of these five failure causes.