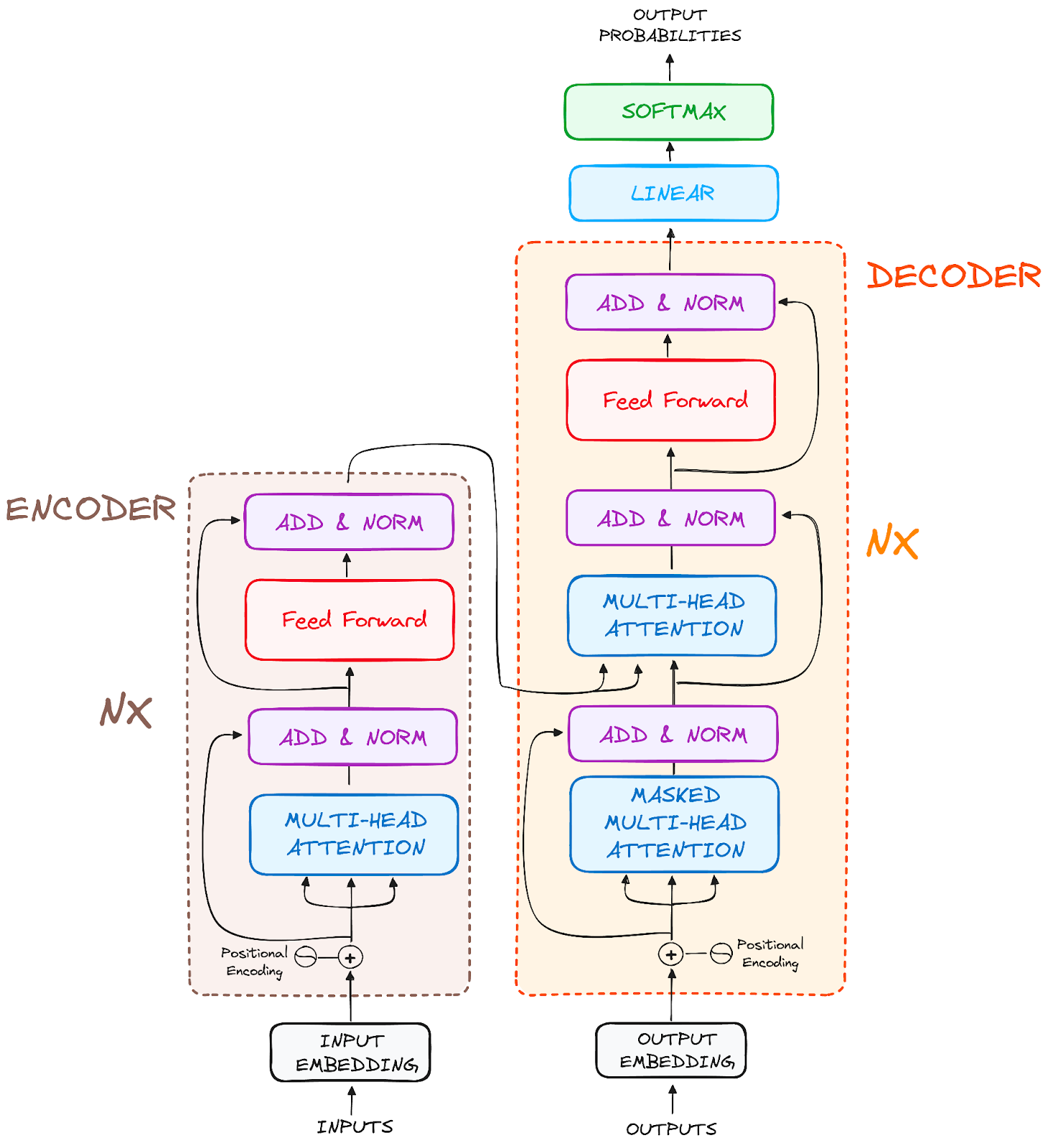
This project provides a comprehensive PyTorch implementation of the Transformer architecture as introduced in the paper "Attention Is All You Need" by Vaswani et al. This implementation serves as both a functional model for NLP tasks and an educational resource for understanding the inner workings of transformers.
- Overview
- Architecture Deep Dive
- Installation
- Usage Guide
- Customization Options
- Training Process
- Results and Visualization
- Common Issues
- References
The Transformer architecture revolutionized NLP by replacing recurrent layers with attention mechanisms, enabling more efficient parallelization and better modeling of long-range dependencies. This implementation includes the complete encoder-decoder architecture with all components as described in the original paper.
class InputEmbedding(nn.Module):
def __init__(self, d_model : int, vocab_size : int):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)The embedding layer converts token IDs into dense vector representations. The multiplication by √d_model helps maintain the variance of the initialized embeddings, improving training stability.
class PositionalEncoding(nn.Module):
def __init__(self, d_model : int, sequence_length : int, dropout : float):
super().__init__()
self.d_model = d_model
self.sequence_length = sequence_length
self.dropout = nn.Dropout(dropout)
# Create positional encoding matrix using sine and cosine functions
pos_encoding = torch.zeros(sequence_length, d_model)
pos = torch.arange(0, sequence_length, dtype=torch.float).unsqueeze(1)
divisor = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pos_encoding[:, 0::2] = torch.sin(pos * divisor)
pos_encoding[:, 1::2] = torch.cos(pos * divisor)
pos_encoding = pos_encoding.unsqueeze(0)
self.register_buffer('pos_encoding', pos_encoding)Since the Transformer doesn't use recurrence or convolution, positional encodings inject information about the position of tokens in the sequence. The implementation uses sine and cosine functions of different frequencies to create unique encodings for each position.
class MultiheadAttention(nn.Module):
def __init__(self, d_model : int, h : int, dropout : float):
super().__init__()
self.d_model = d_model
self.h = h
self.dropout = nn.Dropout(dropout)
assert d_model % h == 0, 'd_model is not divisible by given number of heads(h)'
self.dk = d_model // h
# Initialize parameter matrices
self.Wk = nn.Linear(d_model, d_model, bias=False)
self.Wq = nn.Linear(d_model, d_model, bias=False)
self.Wv = nn.Linear(d_model, d_model, bias=False)
self.Wo = nn.Linear(d_model, d_model, bias=False)The heart of the Transformer, multi-head attention allows the model to attend to information from different representation subspaces. It projects the input into query, key, and value vectors, computes scaled dot-product attention, and concatenates the results.
class FeedForward(nn.Module):
def __init__(self, d_model : int, d_ff : int, dropout : float):
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))The feed-forward network consists of two linear transformations with a ReLU activation in between. This component processes each position independently, adding non-linearity to the model.
class LayerNormalization(nn.Module):
def __init__(self, eps : float = 10**-6):
super().__init__()
self.eps = eps
self.gamma = nn.Parameter(torch.ones(1))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.gamma * (x - mean) / (std + self.eps) + self.biasLayer normalization helps stabilize the training process by normalizing the inputs across the feature dimension. It's applied after each sub-layer within the encoder and decoder.
class ResidualConnection(nn.Module):
def __init__(self, dropout : float):
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm_layer = LayerNormalization()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm_layer(x)))Residual connections help with gradient flow through deep networks by providing a direct path for gradients. The implementation uses the "Add & Norm" approach where the input is added to the output of each sub-layer.
To get started with this project, follow these steps:
- Python 3.7+
- PyTorch 1.8+
- CUDA-compatible GPU (recommended but not required)
-
Clone the repository
git clone https://github.com/yourusername/transformer-from-scratch.git cd transformer-from-scratch -
Create a virtual environment
python -m venv venv # On Windows venv\Scripts\activate # On MacOS/Linux source venv/bin/activate
-
Install dependencies
pip install torch torchvision torchaudio pip install tokenizers datasets tqdm tensorboard
-
Configure the model parameters
config = { 'batch_size': 8, 'num_of_epochs': 1, 'lr': 10**-4, 'sequence_length': 350, 'd_model': 512, 'src_lang': 'en', 'target_lang': 'it', 'model_folder': "weights", 'model_basename': 'transformer_model', 'preload': None, 'tokenizer_file': 'tokenizer_{0}.json', 'experiment_name': 'runs/transformer_model' }
-
Train the model
python train.py
-
Monitor training with TensorBoard
tensorboard --logdir=runs
-
Inference/Translation
from inference import translate sentence = "Hello, how are you today?" translated = translate(sentence, model, src_tokenizer, target_tokenizer, config) print(translated) # Outputs the translated sentence
-
Tokenize input sentence The source sentence is tokenized into tokens using the source language tokenizer.
-
Encode the tokens The tokens are converted to embeddings and positional information is added.
-
Pass through encoder The encoded input is processed through the encoder stack.
-
Initialize decoder with start token The decoder begins with a start-of-sequence token.
-
Generate tokens sequentially The decoder generates one token at a time, using the encoder output and previously generated tokens.
-
Stop when end token is reached The generation stops when the end-of-sequence token is produced.
d_model: Dimension of embeddings and model (default: 512)h: Number of attention heads (default: 8)N: Number of encoder and decoder layers (default: 6)d_ff: Dimension of feed-forward network (default: 2048)dropout: Dropout rate (default: 0.1)
batch_size: Number of samples per batch (default: 8)num_of_epochs: Number of training epochs (default: 1)lr: Learning rate (default: 10^-4)sequence_length: Maximum sequence length (default: 350)
Change the source and target languages by modifying:
config['src_lang'] = 'en' # Source language
config['target_lang'] = 'fr' # Target language (changed to French)- English to/from: Italian, French, German, Spanish, Portuguese, Romanian
The training process uses the opus_books dataset, which contains bilingual book excerpts. The data is tokenized using custom WordLevel tokenizers for both source and target languages.
def get_dataset(config):
# Get the raw dataset
raw_dataset = load_dataset('opus_books', f"{config['src_lang']}-{config['target_lang']}", split='train')
# Build tokenizers
src_tokenizer = get_or_build_tokenizer(config, raw_dataset, config['src_lang'])
target_tokenizer = get_or_build_tokenizer(config, raw_dataset, config['target_lang'])
# Split dataset into training and validation
train_size = int(0.9 * len(raw_dataset))
validation_size = len(raw_dataset) - train_size
raw_train_data, raw_validation_data = random_split(raw_dataset, [train_size, validation_size])The training loop processes batches of source and target sentences, calculates the loss, and updates the model weights:
for epoch in range(config['num_of_epochs']):
model.train()
batch_iterator = tqdm(train_dataloader, desc=f'Processing Epoch {epoch:02d}')
for batch in batch_iterator:
encoder_input = batch['encoder_input'].to(device)
decoder_input = batch['decoder_input'].to(device)
encoder_mask = batch['encoder_mask'].to(device)
decoder_mask = batch['decoder_mask'].to(device)
# Forward pass
encoder_output = model.encode(encoder_input, encoder_mask)
decoder_output = model.decode(decoder_input, decoder_mask, encoder_output, encoder_mask)
projection_output = model.projection_pass(decoder_output)
# Calculate loss
label = batch['label'].to(device)
loss = loss_function(projection_output.view(-1, target_tokenizer.get_vocab_size()), label.view(-1))
# Backpropagate and optimize
loss.backward()
optimizer.step()
optimizer.zero_grad()Training progress can be monitored in real-time using TensorBoard:
writer = SummaryWriter(config['experiment_name'])
# During training
writer.add_scalar('train_loss', loss.item(), global_step)
writer.flush()The model is saved at the end of each epoch:
model_filename = get_weight_file_path(config, epoch)
torch.save(
{
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'global_step': global_step
},
model_filename
)Transformers can be memory-intensive. If you encounter out-of-memory errors:
- Reduce the
batch_size - Reduce the
sequence_length - Reduce the
d_modeldimension
For faster training:
- Use a GPU with CUDA support
- Reduce the dataset size for experimentation
- Use a smaller model by reducing
N(number of layers)
If you encounter tokenization errors:
- Check that your dataset has been properly loaded
- Verify the tokenizer file paths
- Make sure the vocabulary size matches what's expected
- Attention Is All You Need - Original paper
- The Illustrated Transformer - Visual guide
- The Annotated Transformer - Implementation walkthrough
- PyTorch Documentation - Framework reference