Resource Pool API by Adam Jacobs
resource_pool_cli is a tool originally written by developer Gerardo Laracuente (@glaracuente) while he was at Insight Data Science.
I have forked and adapted it here with permission.
resource_pool_cli provides a command-line interface that leverages a tool
written in Python for automatically creating, resizing, and destroying
Kubernetes clusters on in-house hardware. It regards these clusters as resource
pools that can be described in terms of cores and memory. The use-case is
ramping up deployment of existing software on modern, cloud-aware platforms
while still being able to keep the code in production without completely
refactoring to be cloud-native or robustly containerized.
This fork builds out high availability and self-healing, enabling exploration and prototyping of cloud-aware features as well as some initial benefits of a robust DevOps platform:
- Staged upgrades, maintenance, and trouble-shooting can be carried out in isolation, while keeping well-functioning parts of the infrastructure up
- Common cloud-native offerings, like elastic IPs (or equivalents) and availability zones have been built into my infrastructure (by me, this was not available in the original fork)
- A flexible, configurable testbest for designing, developing, and/or migrating apps for a cloud-native, hybrid, and/or multi-cloud set of environments.
Note on API vs CLI: Throughout this project, you may see resource_pool_cli. This is maintained for backwards compatibility and the functioning of the codebase. However, for clarity we have started renaming the project resource_pool_api, as the core of this project is an API that is exposed through a CLI. This API is designed to give developers immediate access to the features they need from k8s without having to know k8s. Further, they at most need to be able to edit an ansible playbook, rather than having to worry about properly configuring and deploying ansible throughout the infra.
Many institutions are not running in the cloud using modern deployment infrastructures. The reasons why are unique to each institution, but common reasons include: regulatory restrictions, the costs of robustly (securely!) refactoring existing production codebases to be cloud-native without any degradation in service, or the applications deployed utilize either specialized hardware that's not well-supported or relies on bare-metal, low-level access to hardware that is difficult to target on major cloud platforms.
Some of these institutions will get a net monetary benefit from ramping up and investing in developing cloud-native technologies, while others will get all the value they need by continuing to run their applications as-is while leveraging some of the benefits from technology that has emerged from the cloud: very cheap, fast deployment - in production -; decoupling development infrastructure from applications, enabling powerful monitoring and metrics that yield actionable insight; and letting everyone in the institution focus on what they're best at.
resource_pool_cli enables institutions in this position to start iterating on
solutions immediately, gaining insight into how they can leverage emerging
technology and what the cost-benefit analysis will look like.
-
Must implement
- auto-scaling: this is the primary motivation for the POC use-case, and is why I chose to fork from an infrastructure intended for system administrators which had made very good decisions regarding a flexible, native install of a k8s cluster
- result: basic auto-scaling is demonstrated
- fault-aware: this is the first step to self-healing, which brings us closer to production quality
- result: completed more robustly than anticipated
lay foundation for CI/CD pipline with a trivial install and slight build out of travisCI: this also prepares us for production and exposes more DevOps utilitySCOPED DOWN: this proved to be a less pressing priority as challenges arrised during my implementation of the MVP
- auto-scaling: this is the primary motivation for the POC use-case, and is why I chose to fork from an infrastructure intended for system administrators which had made very good decisions regarding a flexible, native install of a k8s cluster
-
Stretch goals
- stress test with model application and random service failures generated by hand to see how infrastructure responds
- result: I did some minor stress testing, mostly verifying the robustness of the captain node. However, more stress testing should be done on this architecture
- high-availability: build out availability with existing k8s deployment or in collaboration with
consul- result: I did this and found
consulto be over-engineering, but certainlyconsulshould be considered for particular buildouts of this base infrastructure.
- result: I did this and found
- self-healing: build on the fault-aware design to implement self-healing and/or fault-resiliency, especially addressing the AWS captain instance that's currently a single point of failure
- result: Completed. The captain node does not carry any important state, so can safely be restarted if needed. Though not yet implemented, my infrastructure makes it possible to build out automated failover of the captain node, as demonstrated by my manual failover tests seen in my demo. While my infra will likely not have enough concurrent users to make it necessary, one could also build out an active/passive set of redundant captain nodes if high availability of the node were mission-critical.
- production-viable load balancer: currently NodePort is utilized along with some calculations in the Python engine to do a basic, custom load balancer. Something like Metal LB is more appropriate in production for use-cases being considered on this platform
- result: This remains a stretch goal. Were an engineering firm to take my infra as intended, I would advise them to first explore replacing the custom balancer with Metal LB.
- stress test with model application and random service failures generated by hand to see how infrastructure responds
-
nice to haves
- replace all instances of "CLI" with "API", test to make sure the resulting directory name changes do not break the infra
- consider replacing TravisCI with the less developer-friendly but much more production-viable Jenkins
Python Resource Pool API + Ansible --> use-case appropriate k8s deployment
The API is written in Python and exposes a CLI utility. The backend is powered by Ansible, which is leveraged to very carefully deploy exaclty the k8s cluster deployment we need that works with existing apps. The API exposes the specific features of our k8s deployment needed, allowing users/developers to worry about their work, not how to install a custom k8s deployment.
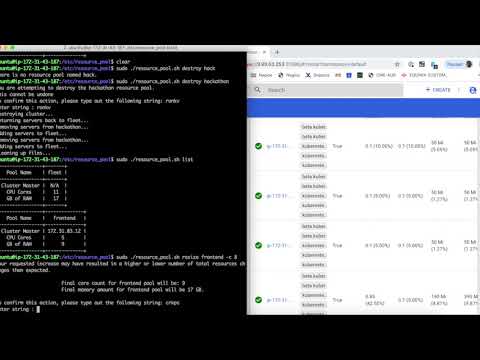
Examples of k8s functionality that are exposed through the API include: spawn new k8s clusters add nodes drain remove nodes
Note how the API thinks from the perspective of our users and developers, not bothering with potentially confusing k8s API object terminology, opting instead for the familiar terminology of clusters and nodes.
TODO: everything below this is the original draft from Gerry. To make this project my own, I need to rewrite it in my words and adapted for my different use-case.

In the top half of the archtecture diagram, I show what this would look like in the real world. The user would just need to have one server running docker. After running one simple bash script, everything will be set up for them. This server runs the CLI alongside Ansible inside of a docker container.
The bottom half shows what was used for development, and you can try this out yourself. I spun up mock "data centers" in AWS. These are just EC2 instances running Ubuntu 16.04, in the same VPC. I run the setup.sh script on one of them, and then use this instance to create k8s clusters out of the others.
Want to try it out?
- All you need is the setup.sh file from the user_facing directory.
- The server for running the CLI needs to have docker installed before running the setup script.
- This entire project has only been tested on Ubuntu 16.04.
Auto Healing - A scheduler needs to keep track of the desired resource counts for each pool. When a server goes down, the scheduler should notice the decrease in resources, and automatically replace the server and notify an admin, create a ticket, etc.
HA of Masters - The master of each cluster is currently a point of failure. The master should be a set of servers set up for HA.
Load Balancer - Since this should be able to run on baremetal, "Metal LB" needs to be added to the cluster in order to expose services properly. NodePort is currently used, but this is not a production ready method.