Releases: abhi777/Cloud-based-Web-Scraper
Scrapify
Scrapify v1.0.10
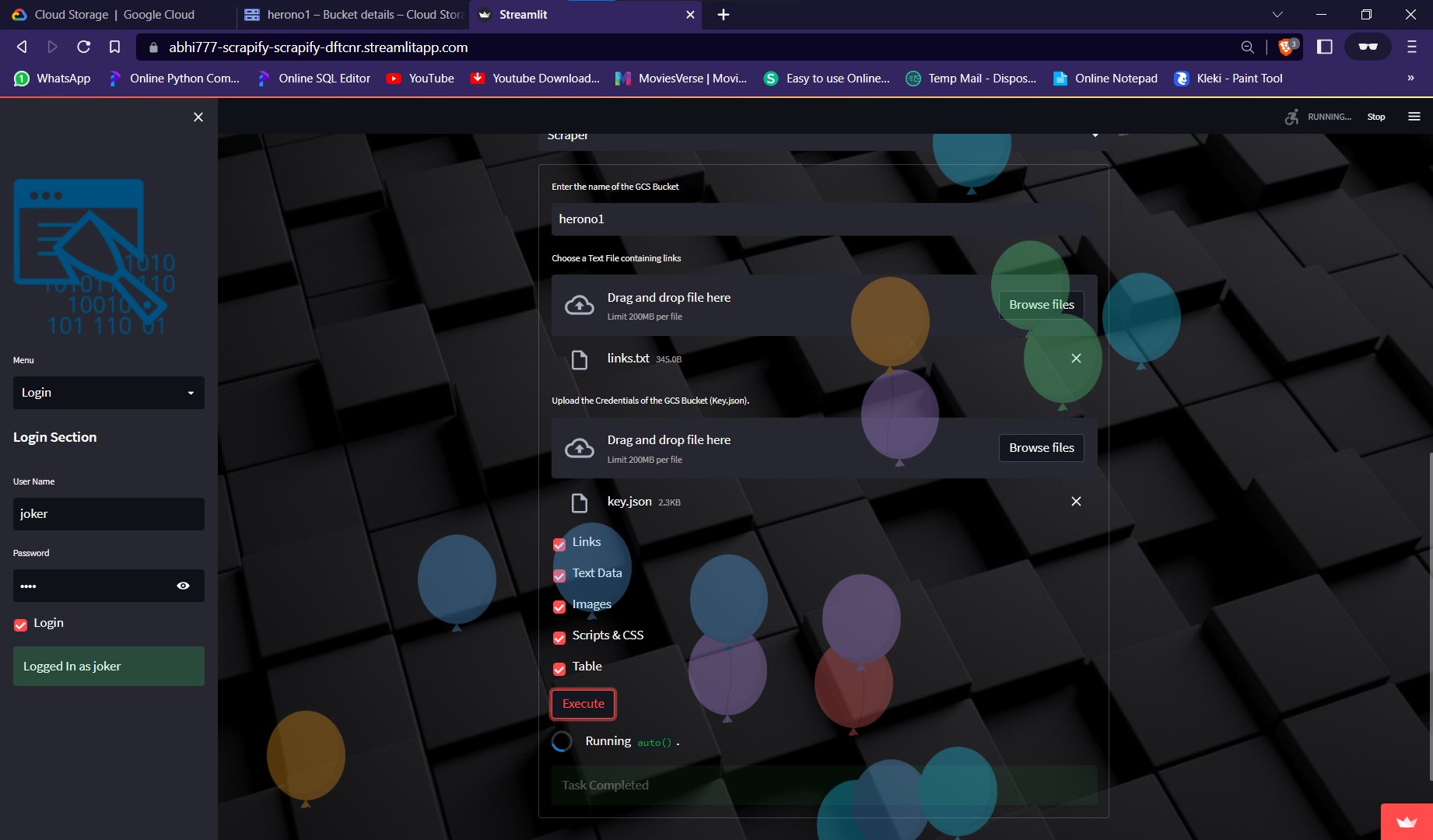
This is a Web Application developed using Python which can scrap Data from the web and save the extracted Data in Google Cloud Storage. It's also very convenient to use, even for a Non-Technical Person as it provides a really nice UI.
To check out the live version of my project, Click Here...
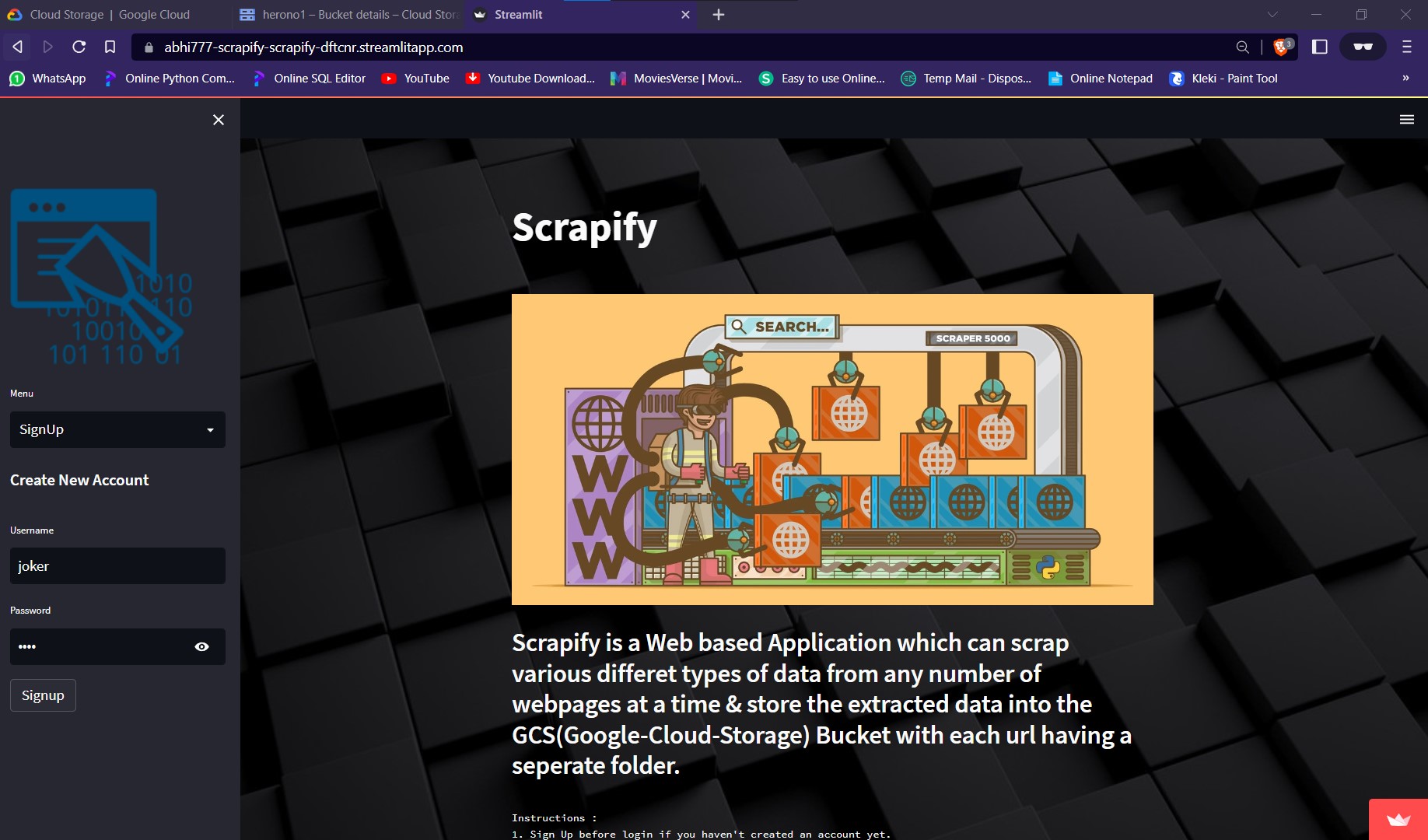
First, We need to signup by clicking on the Sign Up section present in the side bar and Login using the newly created credentials.

It needs various inputs like:
- Name of the GCS Bucket
- A text file containing a list of links of webpages line by line
- A json file containing the credentials of the GCS(Google Cloud Storage)
- Types of Data to be scraped
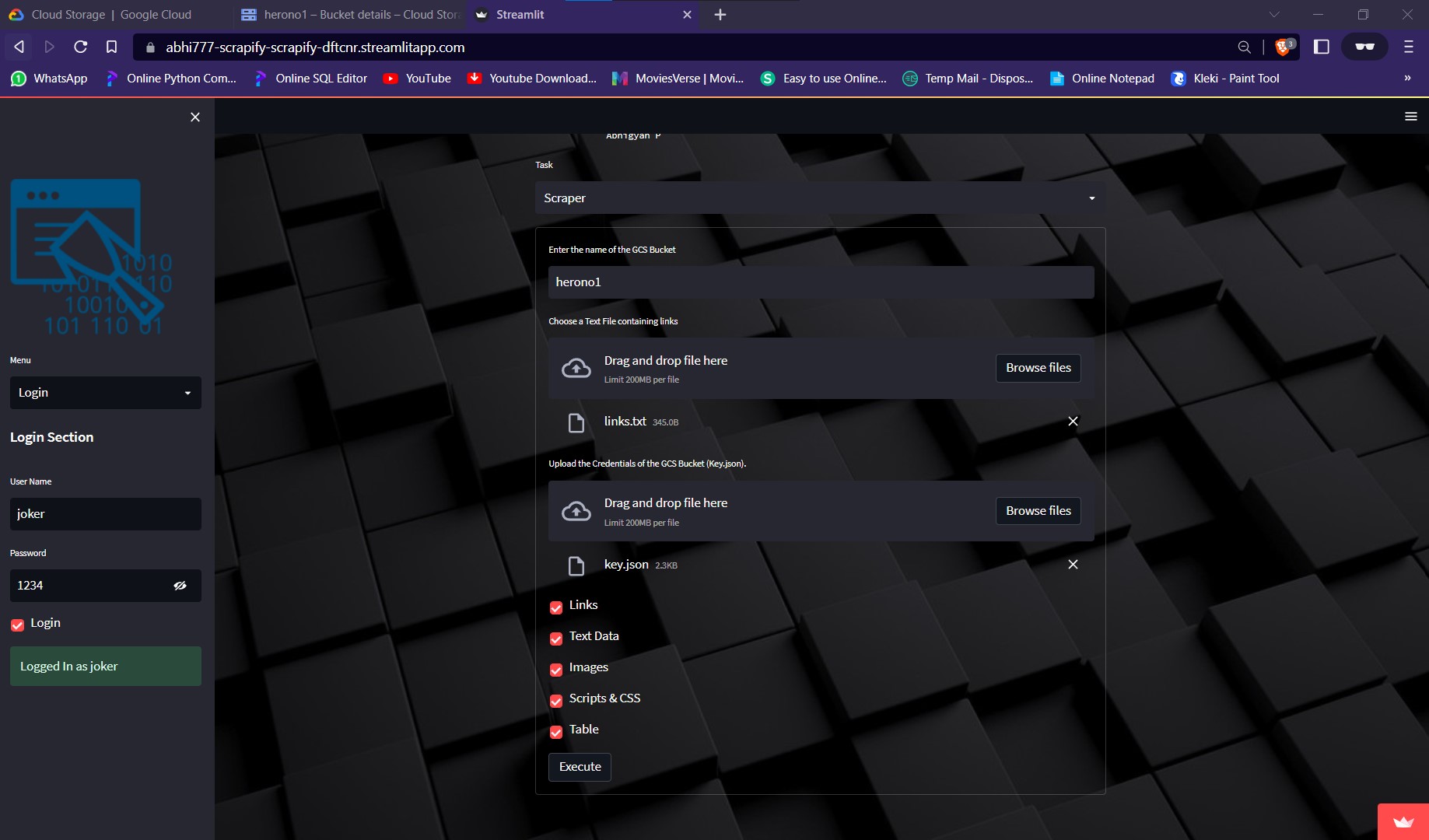
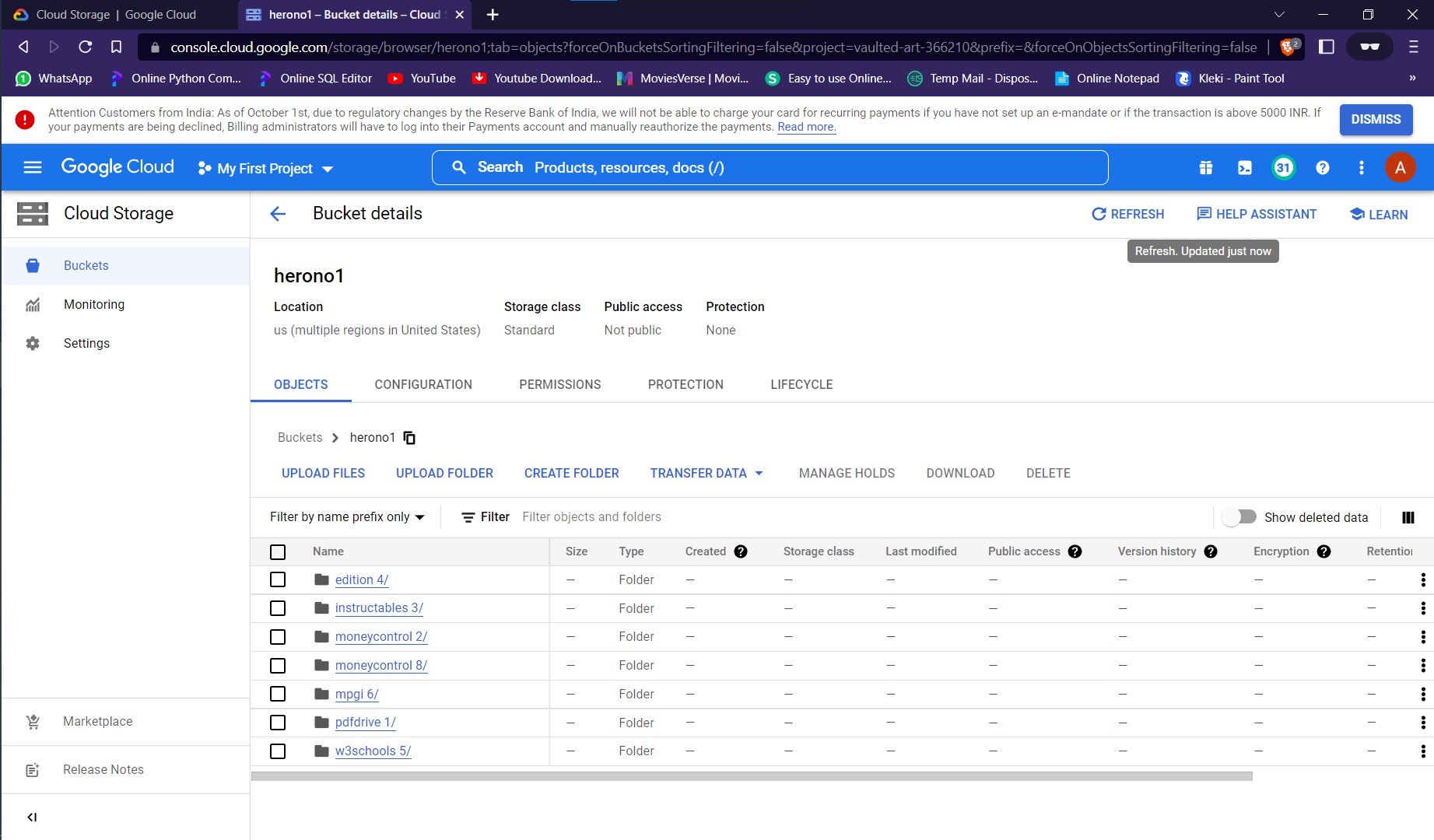
Executing the script after providing the inputs would start saving the required data into the GCS Bucket.
Requirements
- Python (v3.6 or above)
- webpage_links.txt (a text file containing links of webpages)
- requirements.txt
- key.json (credentials of GCS Bucket)
Usage
- Download the Repository using the command given below from the terminal or by downloading the archive from above.
$ git clone https://github.com/abhi777/scrapify.git - Install modules in requirements.txt by executing the command given below in cmd or in the terminal of your Code Editor.
$ pip install -r requirements.txt - A Google Cloud Account must be created before executing the script and the credentials of the GCS Bucket must be kept in the same directory.
- Run the Python Script using terminal or cmd.
$ python scraper.py
$ python -m streamlit run scraper.py - Provide inputs to the script and execute it.
GUI based Web Scraper
GUI based Web Scraper v1.0.7
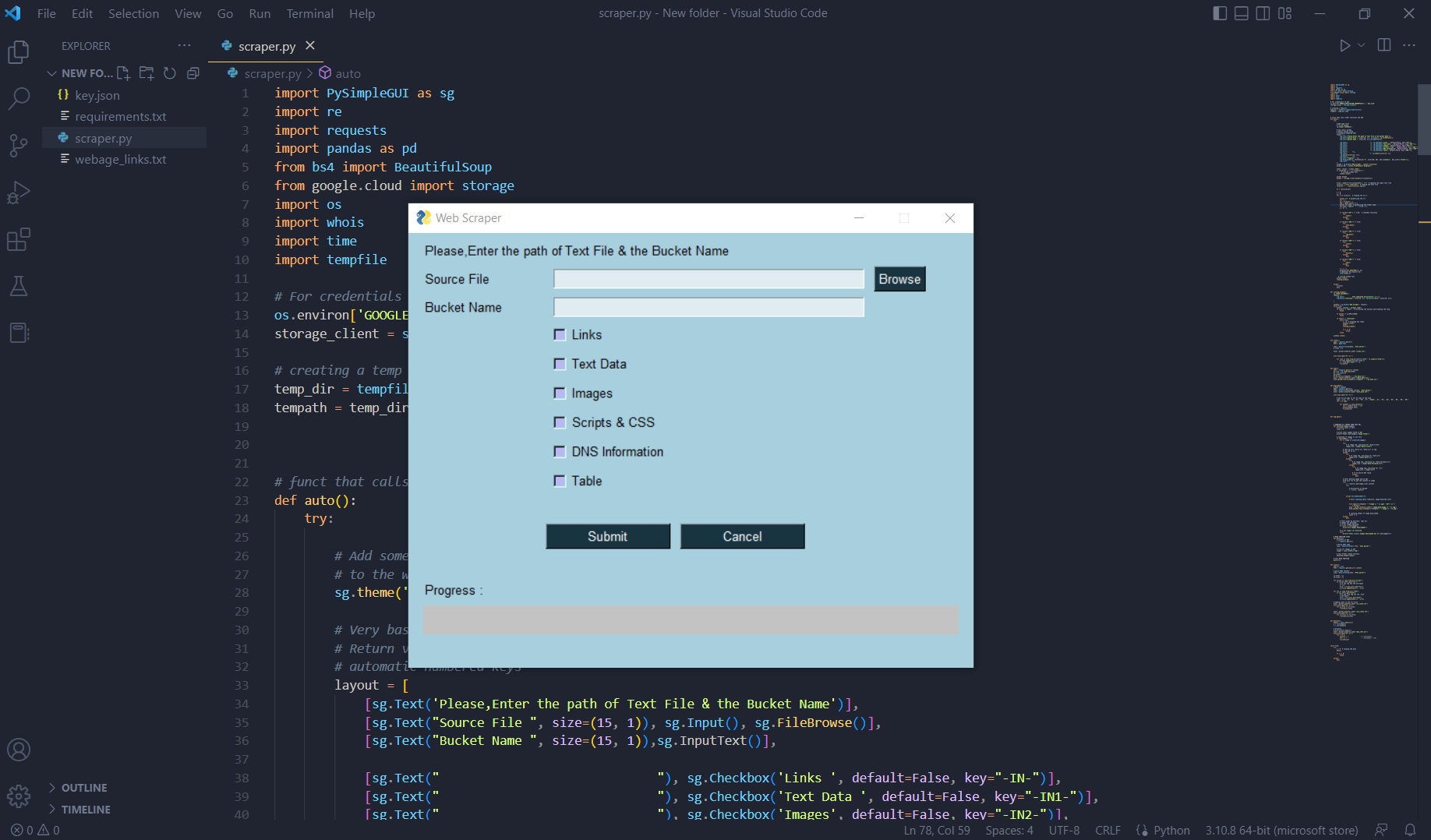
This is a Web Scraping Tool developed using Python which can scrap Data from the web and save the extracted Data in Google Cloud Storage. It's also very convenient to use, even for a Non-Technical Person as it provides a GUI.
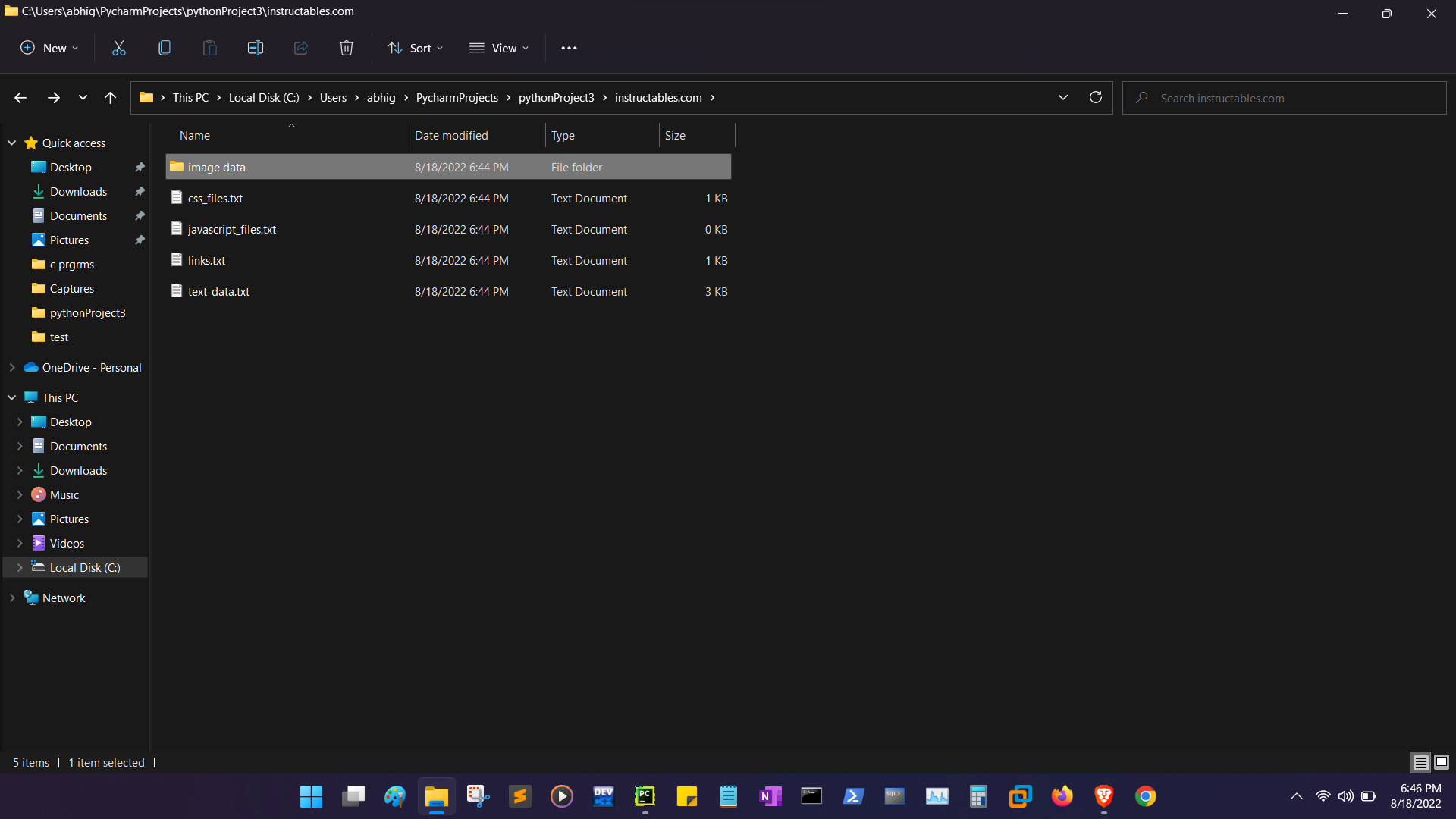
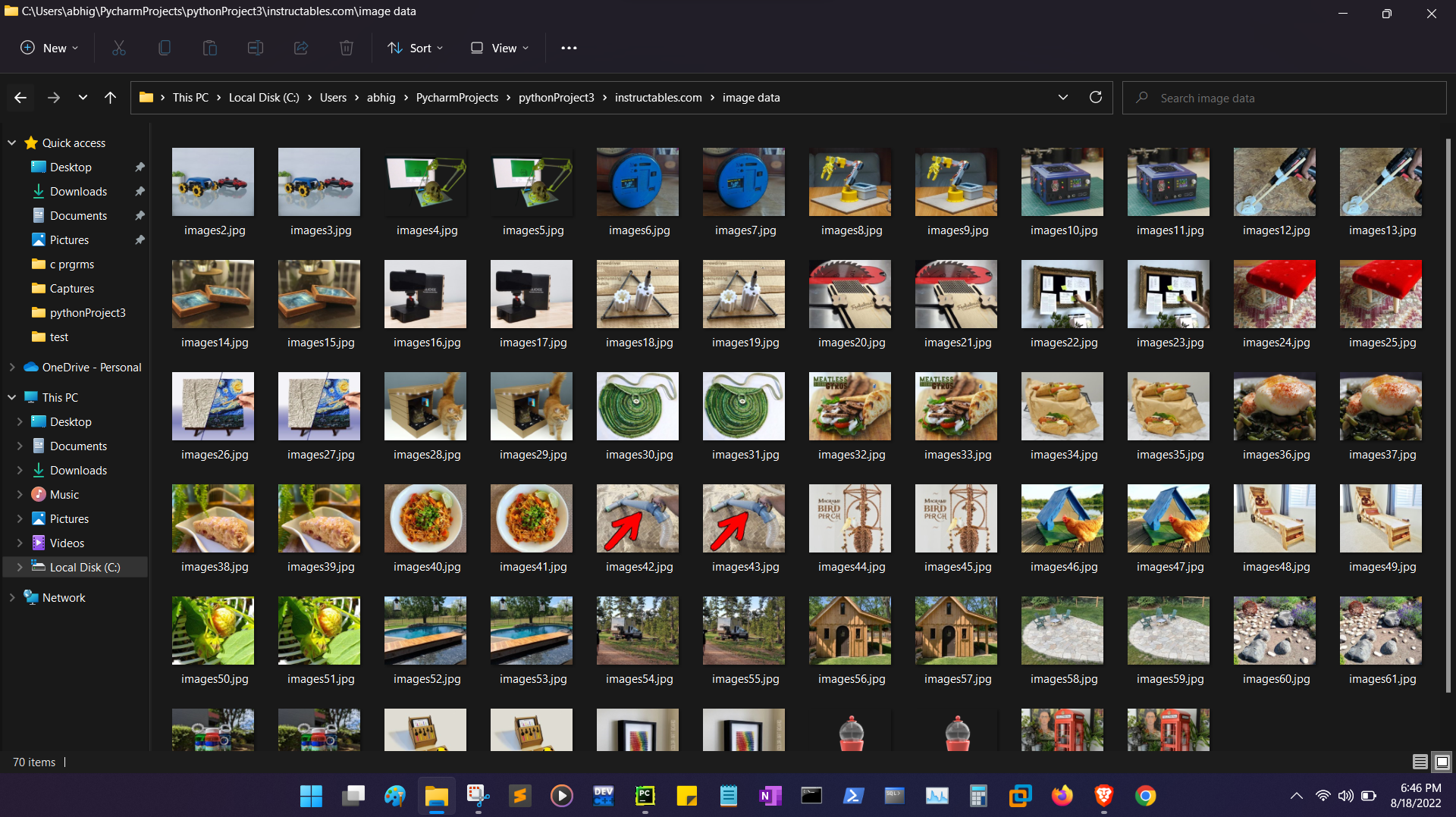
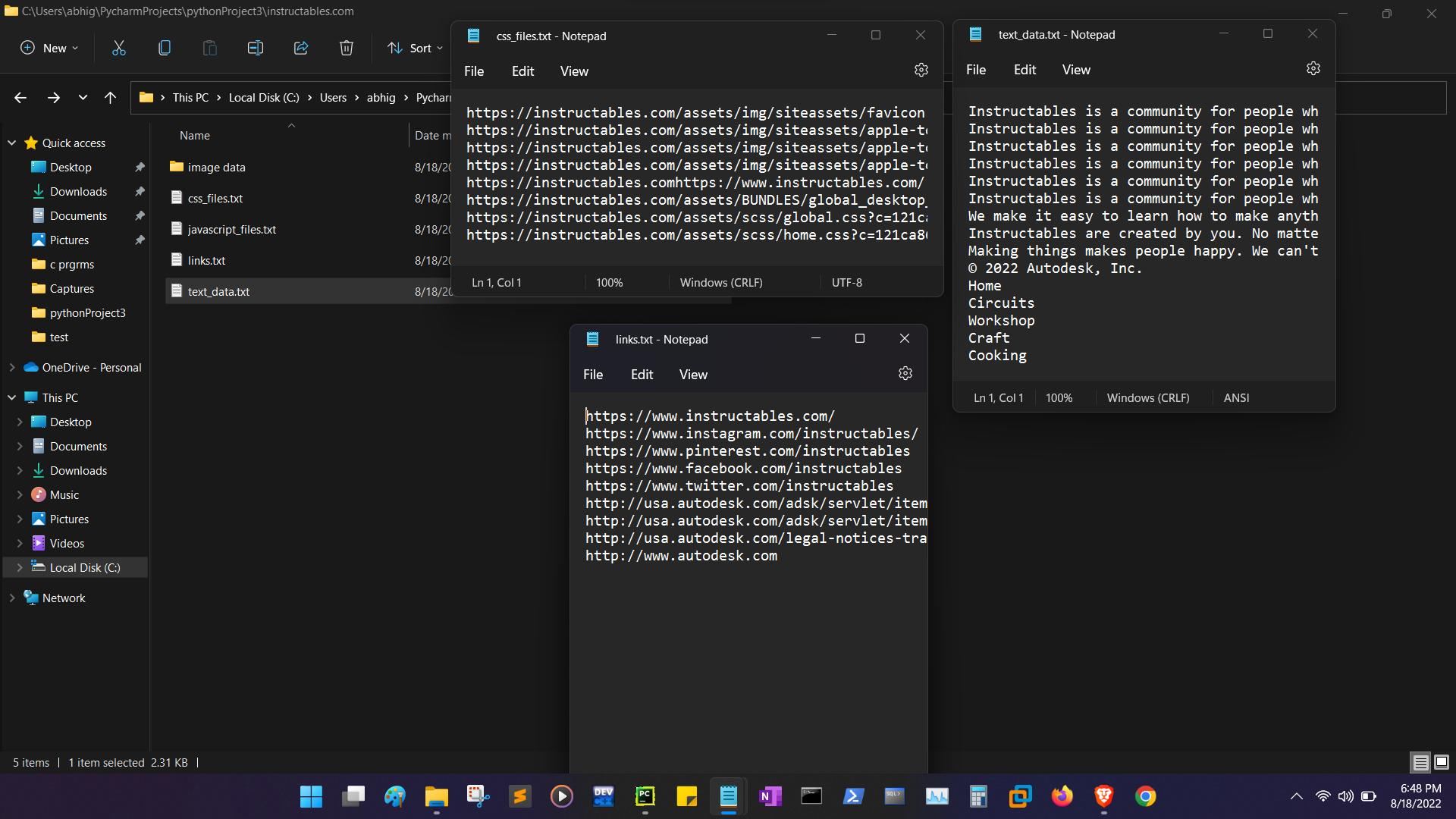
It needs a text file as an input containing a list of links of webpages line by line, name of the GCS Bucket and the types of Data to be scraped.
Executing the script after providing the inputs would start saving the required data into the GCS Bucket.
Requirements
- Windows OS
- Python (v3.6 or above)
- webpage_links.txt (a text file containg links of webpages)
- requirements.txt
- key.json (credentials of GCS Bucket)
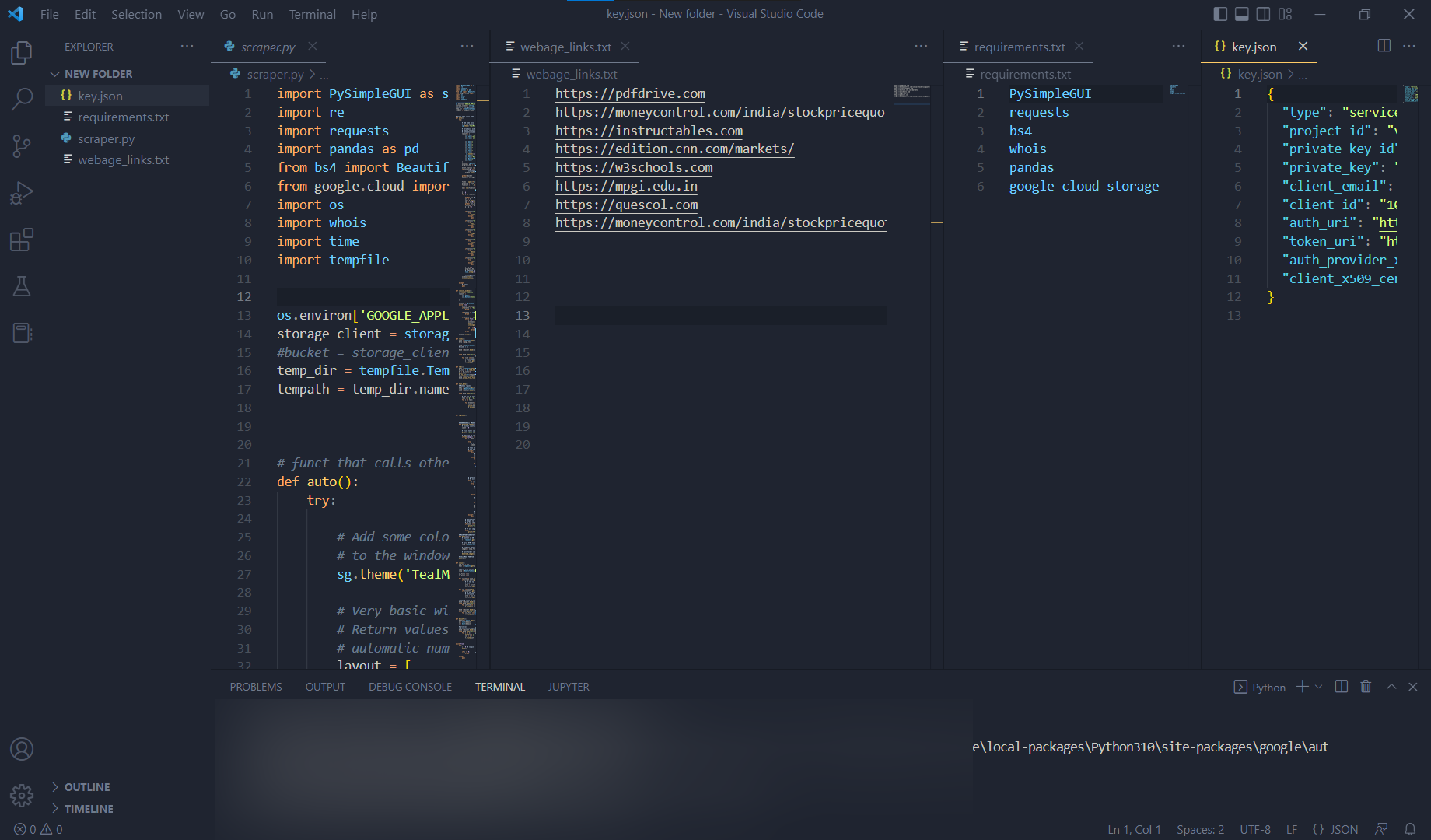
Usage
- Download the Repository using the command given below from the terminal or by downloading the archive from above.
$ git clone https://github.com/abhi750/GUI-based-Web-Scraper.git - Install modules in requirements.txt by executing the command given below in cmd or in the terminal of your Code Editor.
$ pip install -r requirements.txt - A Google Cloud Account must be created before executing the script and the credentials of the GCS Bucket must be kept in the same directory.
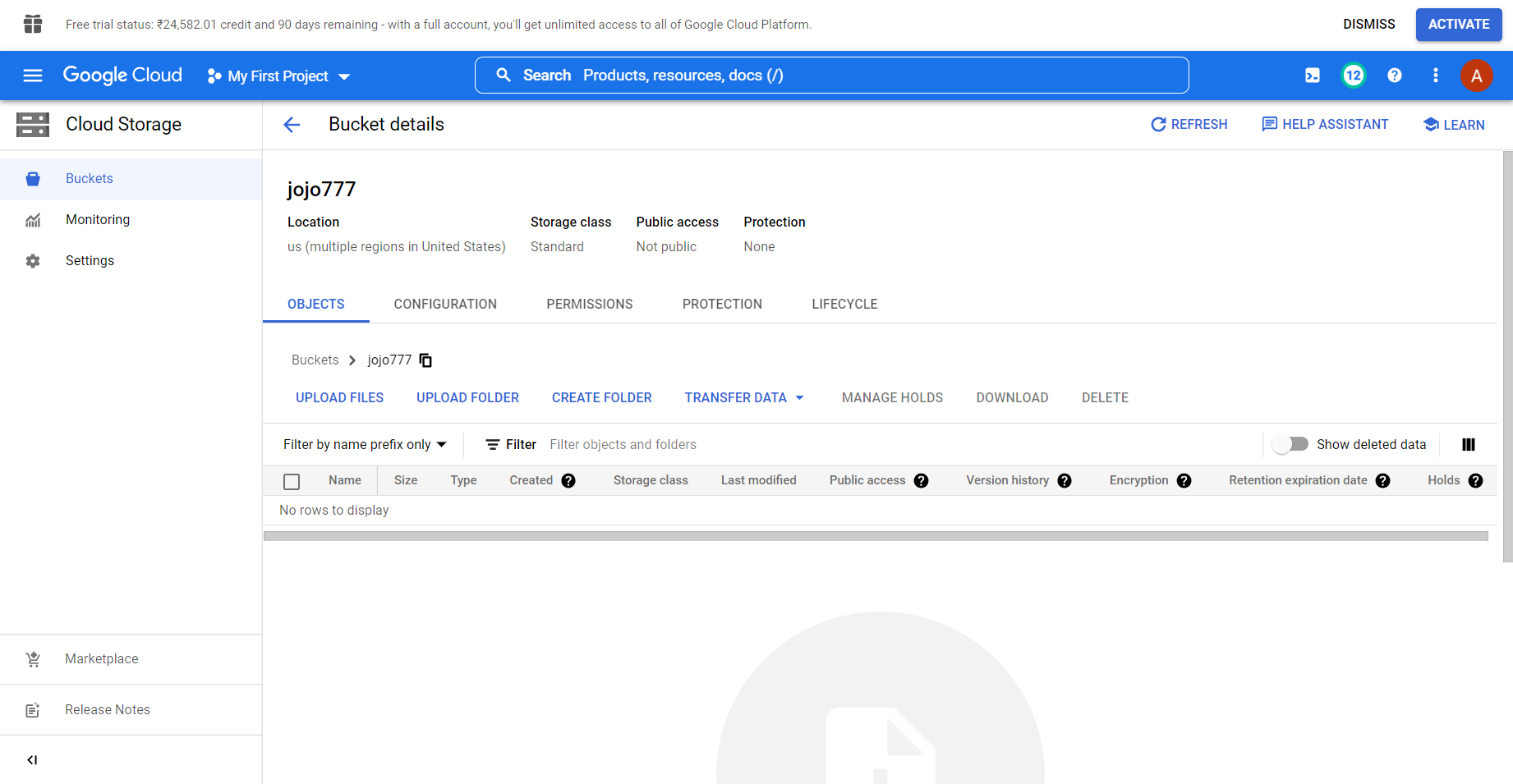
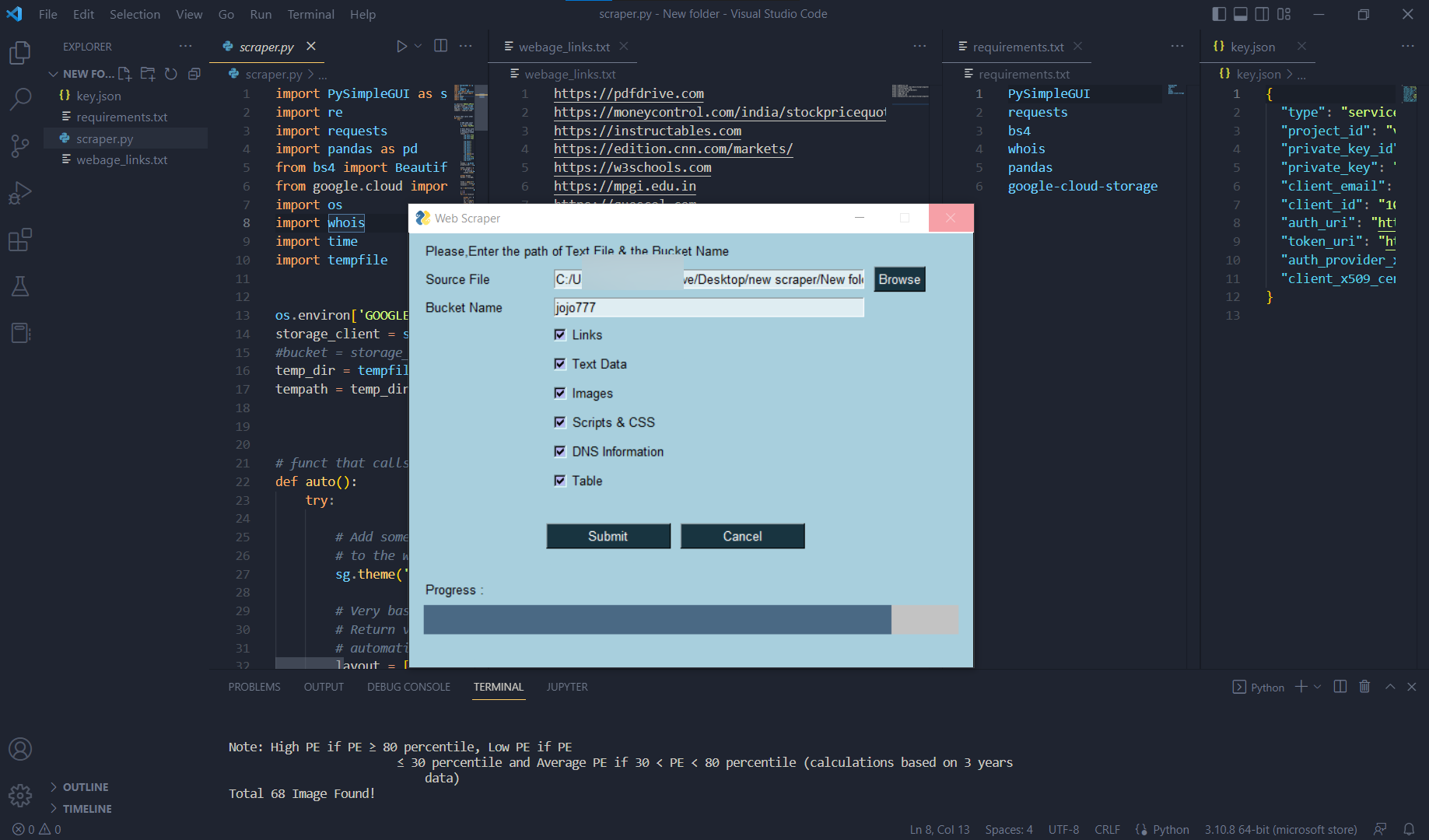
- Run the Python Script using terminal or cmd.
$ python Web Scraper (GUI).py - Provide inputs to the script and execute it.
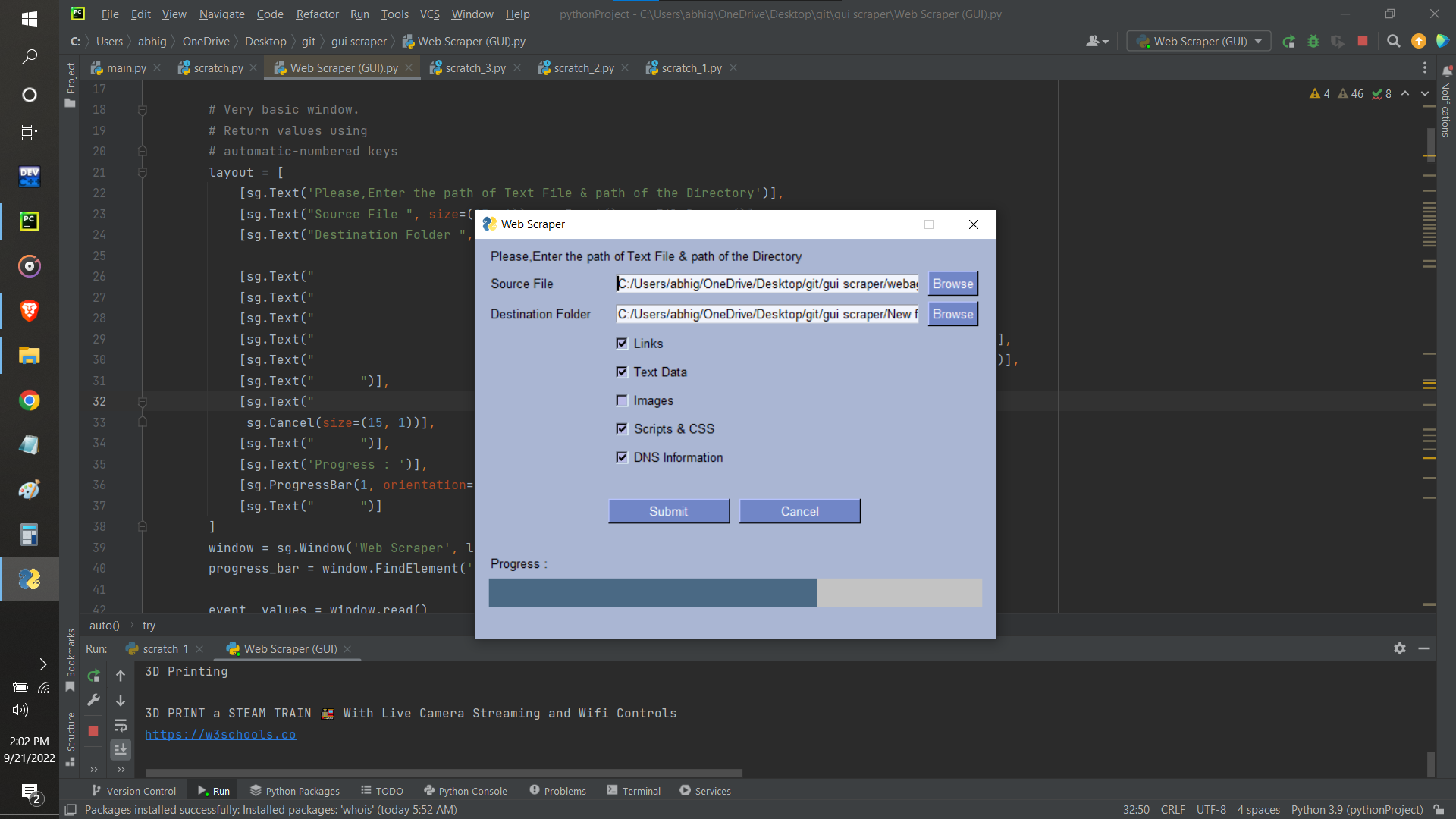
Working
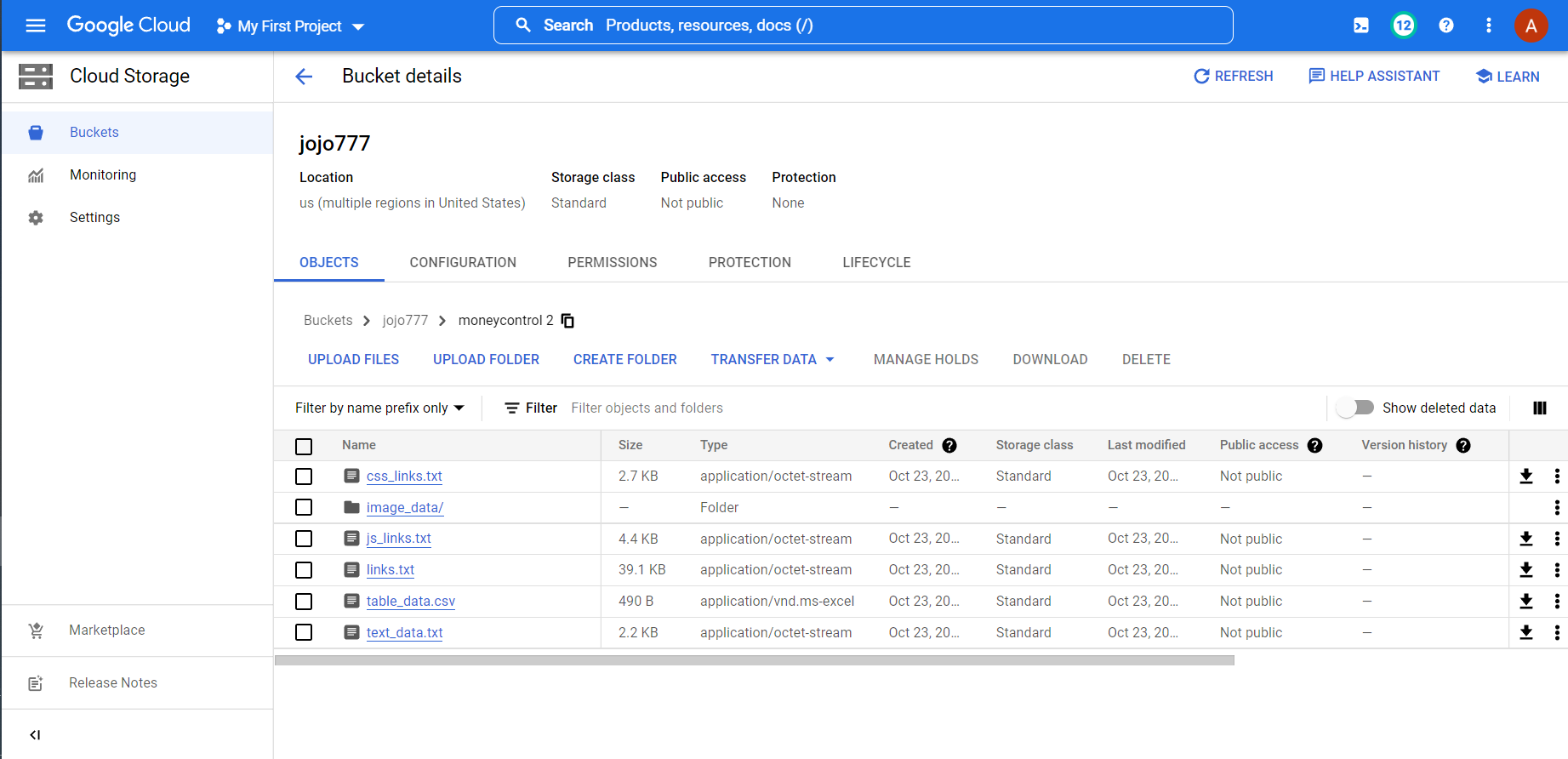
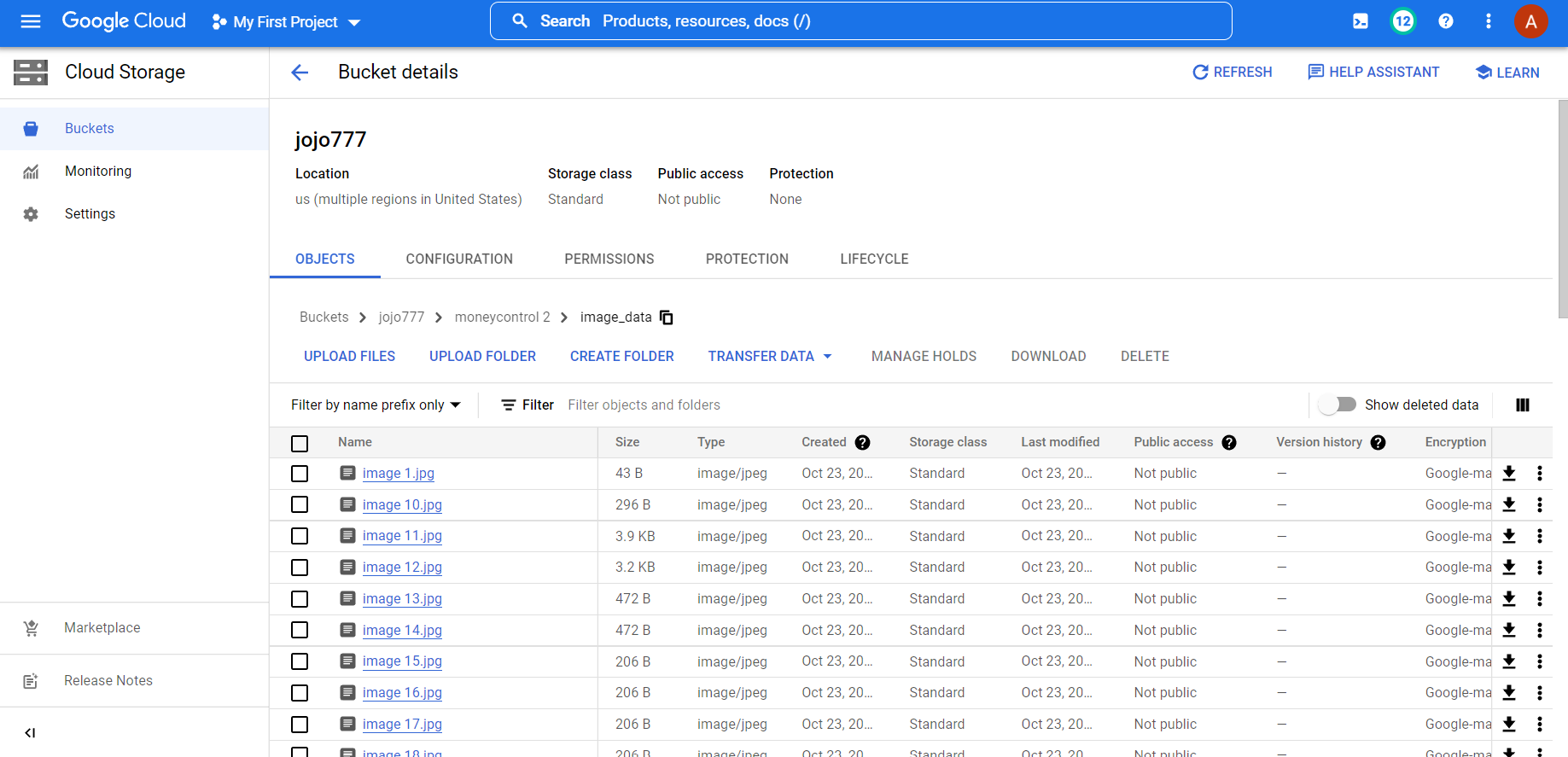
On executing the script, the marked data would be scraped from the specified webpages and would be stored in the GCS Bucket of the user.
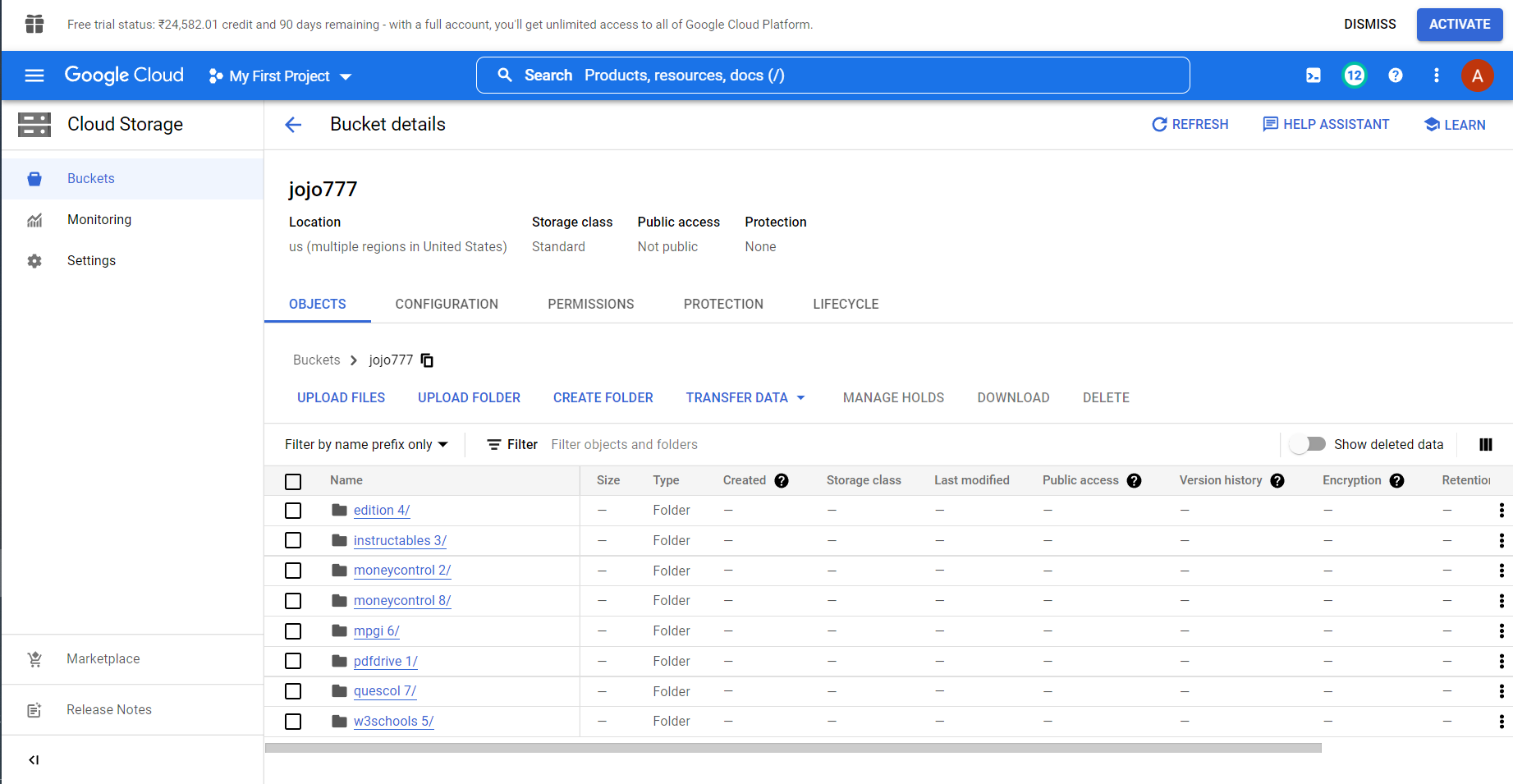
Updates
- A Progress Bar to show the current status of the task.
- Improved Performance and Bug fixes.
- Cloud Storage
GUI based Web Scraper v1.0.2
GUI based Web Scraper v1.0.2
This is a Web Scraping Tool developed using Python to scrap Data from the web and it's also very convenient to use,even for a Non-Technical Person as it provides a GUI.
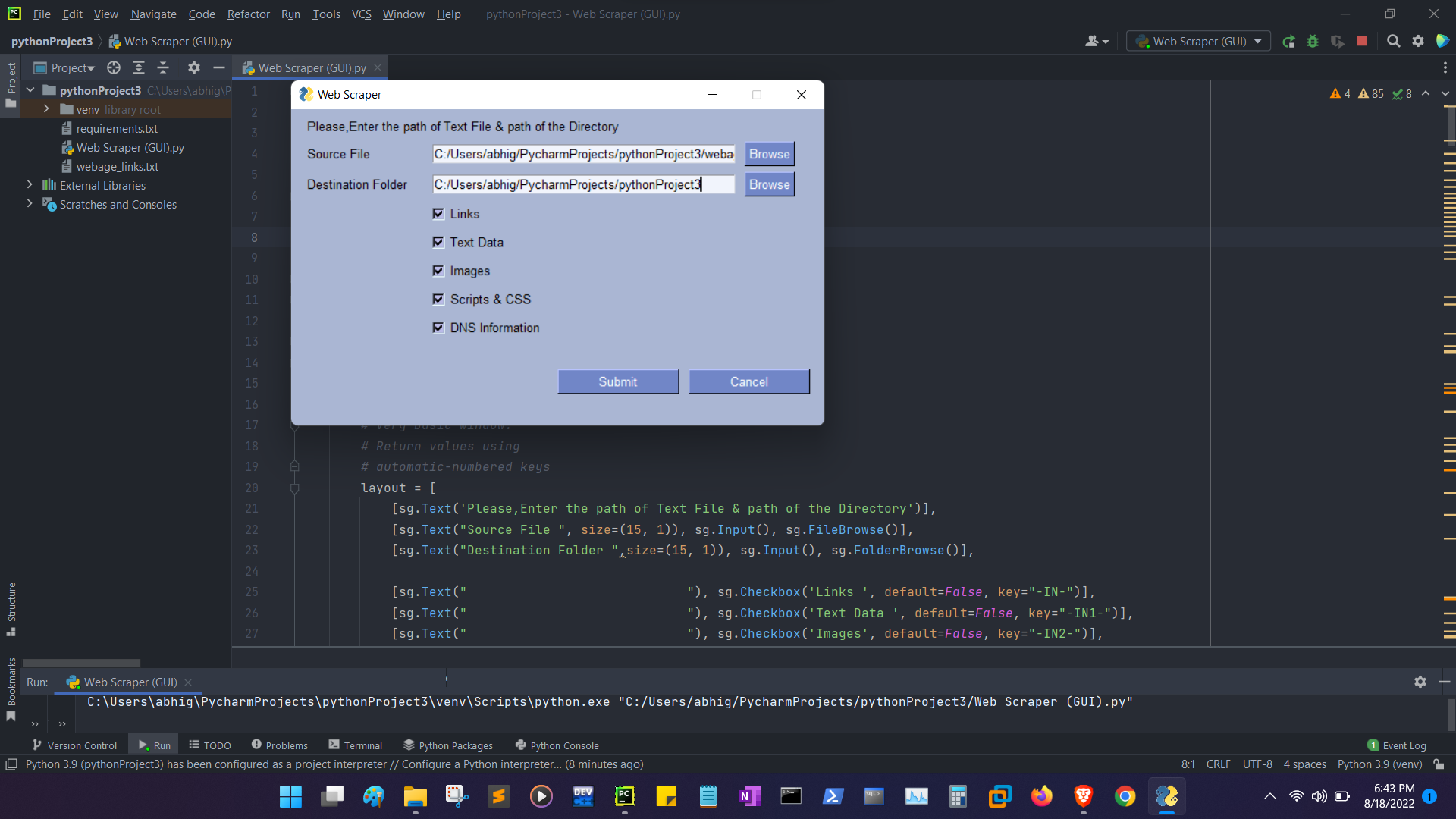
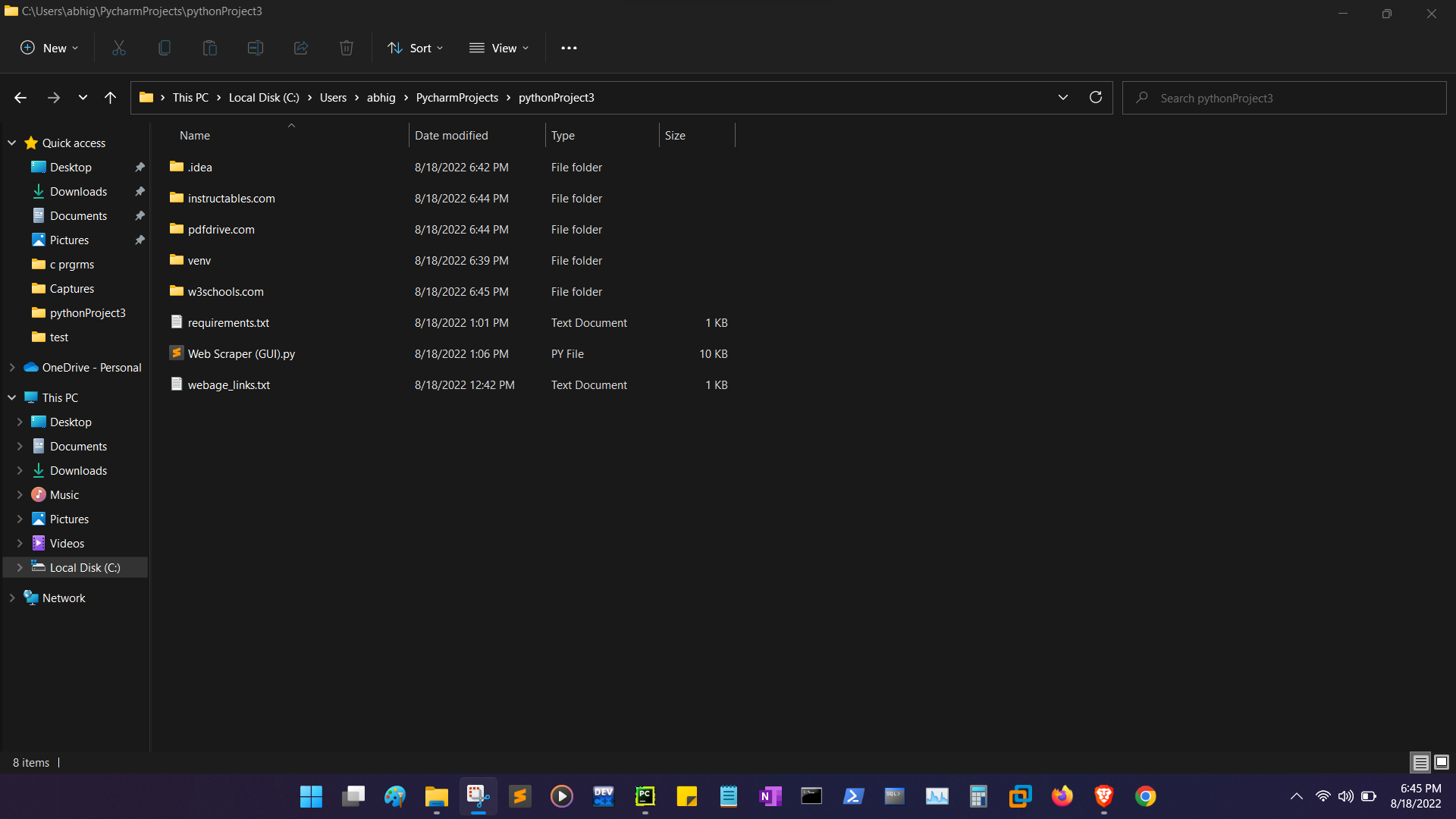
It needs a text file as an input containing a list of links of webpages line by line and a Destination Folder to save data and the types of Data to be scraped.
Executing the script after providing the inputs would start saving the required data into the Destination Folder.
Requirements
- Windows OS
- Python
- requirements.txt
Usage
- Download the Repository using the command given below from the terminal or by downloading the archive from above.
$ git clone https://github.com/abhi750/GUI-based-Web-Scraper.git - Install requirements.txt by executing the command given below in cmd or in the terminal of your Code Editor.
$ pip install -r requirements.txt - Run the Python Script using terminal or cmd.
$ python Web Scraper (GUI).py - Provide inputs to the script and execute it.
Updates
- A Progress Bar to show the current status of the application.
- Improved Performance and Bug fixes.
Screenshots