We decided to roll up our sleeves and implement the SRCNN architecture from scratch. We meticulously implemented each component of the network, including convolutional layers, activation functions, and loss functions. Despite our best efforts in optimization, our custom SRCNN implementation didn't quite meet our expectations. The resulting high-resolution images appeared noticeably blurry and lacked the crispness seen with the custom trained model.

The Super-Resolution Convolutional Neural Network (SRCNN) is a pioneering deep learning model developed for single-image super-resolution. It was proposed by Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang in their paper titled "Image Super-Resolution Using Deep Convolutional Networks" in 2014.
- Patch Extraction and Representation: Initially, low-resolution image patches are extracted and represented as high-dimensional feature vectors.
- Non-linear Mapping: These feature vectors undergo non-linear mapping through a convolutional neural network (CNN). This CNN consists of multiple layers of convolution, each followed by a ReLU activation function.
- Reconstruction: The mapped high-dimensional feature vectors are reconstructed to obtain the high-resolution image.
- SRCNN was one of the early successful attempts at utilizing deep learning for single-image super-resolution.
- It showed significant improvements over traditional interpolation-based methods in terms of perceptual quality metrics like Peak Signal-to-Noise Ratio (PSNR) and Mean Squared Error (MSE).
Single image super-resolution, which aims at recovering a high-resolution image from a single low resolution image, is a classical problem in computer vision. This problem is inherently ill-posed since a mul tiplicity of solutions exist for any given low-resolution pixel. In other words, it is an underdetermined in verse problem, of which solution is not unique. Such a problem is typically mitigated by constraining the solution space by strong prior information. Image super-resolution is the process of generating a high-resolution (HR) image from a low-resolution (LR) input. This problem is crucial in various fields such as computer vision, medical imaging, and satellite imagery analysis. The importance lies in enhancing the visual quality of images, enabling better perception and analysis of details. Traditional methods for image super-resolution often suffer from computational complexity and the loss of image details.
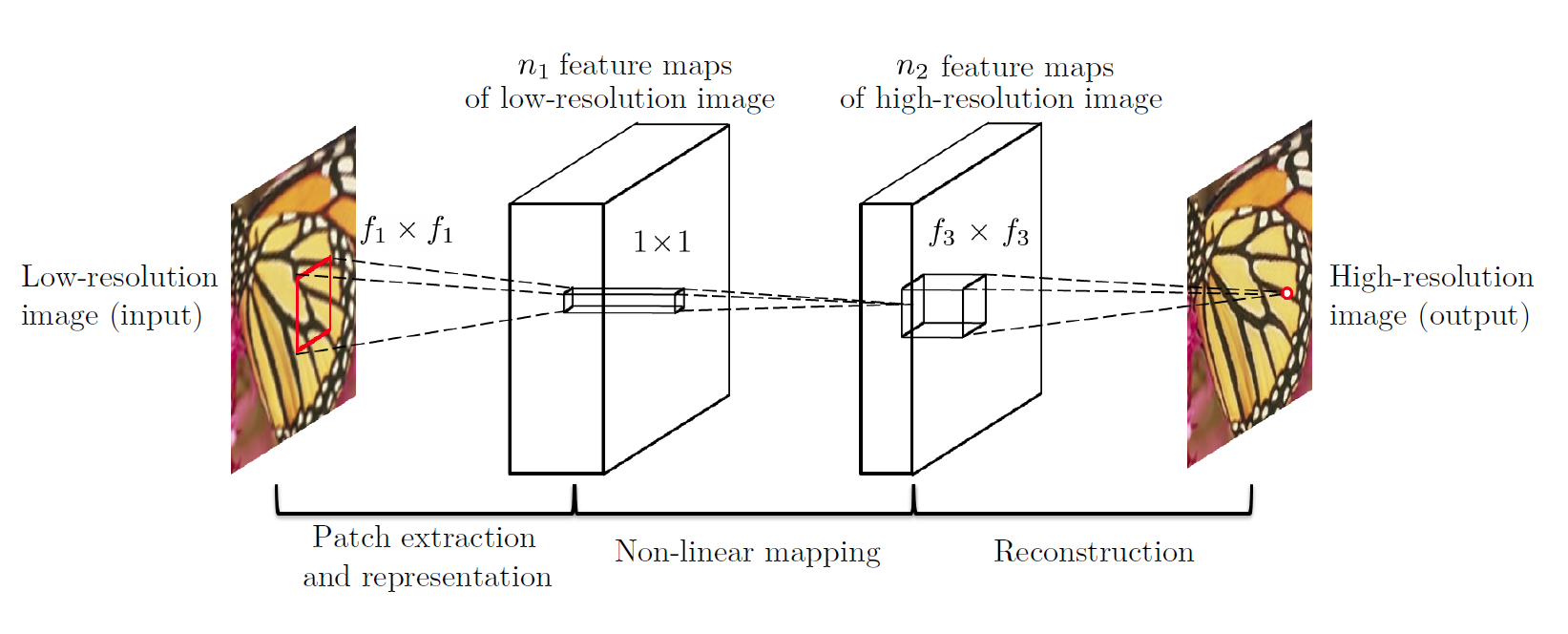
The Super-Resolution Convolutional Neural Network (SRCNN) method addresses these challenges by leveraging deep learning techniques. SRCNN has shown promising results in generating high-quality super-resolved images efficiently. It builds upon prior work in deep learning-based image processing, particularly in convolutional neural networks (CNNs) and image reconstruction.
In this project, we show that the aforementioned pipeline is equivalent to a deep convolutional neural network. Motivated by this fact, we consider a convolutional neural network that directly learns an end-to-end mapping between low- and high-resolution images. This method differs fundamentally from existing external example-based approaches, in that this method does not explicitly learn the dictionaries or manifolds for modelling the patch space. These are implicitly achieved via hidden layers. Furthermore, the patch extraction and aggregation are also formulated as convolutional layers, so are involved in the optimization. In this method, the entire SR pipeline is fully obtained through learning, with little pre postprocessing. The proposed SRCNN has several appealing properties. First, its structure is intentionally designed with simplicity in mind, and yet provides superior accuracy compared with state-of-the-art example-based methods.
Gound truth folder containes the 91 training dataset which has been used to train the SRCNN model.
Set5 and Set14 datset has been used to test dataset where as Set14 only used as an validation dataset.
The datasets used in this project for testing are Set5 and Set14, which are commonly used for testing in Super-Resolution Convolutional Neural Network (SRCNN) models. These datasets contain high-resolution images that are used to evaluate the performance of the model.
For tranining the images we have used the 91 images from the training dataset of the SRCNN model original paper that they have used.
The method used in this project is the SRCNN model, which is a deep learning model designed for image super-resolution. The model is trained using the Mean Squared Error (MSE) loss function, which measures the average squared differences between the estimated and actual values.
Trained the model with different hyperparameters such as batch size, epochs, etc and the key results of each experiment. This includes code snippets for running the experiments and figures generated as a result of the experiments.
- Peak Signal-to-Noise Ratio (PSNR): PSNR is a commonly used metric to evaluate the quality of reconstructed images. It measures the ratio between the maximum possible power of a signal and the power of corrupting noise that affects the fidelity of its representation. In the context of super-resolution, PSNR compares the quality of the high-resolution image produced by a super-resolution algorithm to the original high-resolution image. Higher PSNR values indicate better reconstruction quality.
- Mean Squared Error (MSE): Mean Squared Error (MSE) is another metric used to measure the difference between the original image and the reconstructed image. It calculates the average of the squares of the differences between corresponding pixels of the original and reconstructed images. Lower MSE values indicate better reconstruction quality.
Below is the output of the some of the images that we have used and its PSNR,MSE and SSIM values that we got. As we stated above more the PSNR higher the resolution. and higher the MSE , higher the noise in the image. SSIM is value between 0 to 1, the image closer 1 shows the more similarity between two images and closer to zero means more difference between them.
-
t11.bmp
PSNR: 24.59313993758269
MSE: 677.4661835748792
SSIM: 0.8335180797283744 -
t59.bmp
PSNR: 30.09751015568441
MSE: 190.74387449569141
SSIM: 0.929094609511656 -
t27.bmp
PSNR: 24.032034436326377
MSE: 770.900224161778
SSIM: 0.8604474478701217
We trained the model for 500 epoches on google colab gpu after which it shows the below graph. At the top indicates early stopping at epoch 25, as the validation loss did not improve from 0.02373. Early stopping is a form of regularization used to prevent overfitting when training a learner with an iterative method.
- The graph below represents the training and validation loss of a Super-Resolution Convolutional Neural Network (SRCNN) model over a series of epochs. The x-axis represents the number of epochs, which are full iterations over the entire dataset. The y-axis represents the loss, a measure of how well the model's predictions align with the actual values.
- At the beginning of the training process (around 0 epochs), both the training and validation losses are relatively high, indicating that the model's predictions are not yet accurate. However, these losses decrease sharply as the number of epochs increases, suggesting that the model is learning and improving its predictions.
- As the number of epochs continues to increase, the decrease in loss slows down and eventually plateaus. This plateau indicates that the model has likely reached its optimal state of learning, where further training does not significantly improve its performance. This is a common phenomenon in machine learning and is often referred to as convergence.
- The close proximity of the training and validation loss lines throughout the graph suggests that the model is generalizing well to unseen data. There is no significant divergence between the two, indicating that the model is not overfitting (where the model performs well on the training data but poorly on the validation data) or underfitting (where the model performs poorly on both the training and validation data).
- The model is a sequential model with three convolutional layers. The first layer has 64 filters, the second layer has 32 filters, and the third layer has 1 filter. The model's architecture and the choice of hyperparameters could be discussed in relation to its performance as depicted in the graph.
- This graph effectively demonstrates the learning process of the SRCNN model over time. It provides a clear visual indication of how the model's performance improves with training and eventually converges to an optimal state.

Fast Super-Resolution Convolutional Neural Network (FSRCNN) is an improvement over SRCNN, proposed by Jo et al. in 2016. It aimed to enhance both the computational efficiency and the reconstruction quality of single-image super-resolution.

- Model Architecture: FSRCNN utilizes a shallower network compared to SRCNN, which leads to faster inference times. It replaces the time-consuming iterative operations like deconvolution with more efficient up-sampling layers.
- Parameter Efficiency: FSRCNN reduces the number of learnable parameters compared to SRCNN, making it more computationally efficient.
- Performance: Despite its simplified architecture, FSRCNN achieves comparable or sometimes better performance than SRCNN in terms of PSNR and MSE.
In summary, both SRCNN and FSRCNN are deep learning models designed for single-image super-resolution, with FSRCNN being a more computationally efficient variant. PSNR and MSE are metrics commonly used to evaluate the quality of reconstructed images, where higher PSNR values and lower MSE values indicate better reconstruction quality.
The model takes a low-resolution image as input and outputs a high-resolution version of the same image. The SRCNN model achieves this by passing the low-resolution images through a series of non-linear functions.
Mathematically, if Y is the low-resolution image, the SRCNN model applies a function F such that the output X is a high-resolution version of Y. This can be represented as X = F(Y)¹¹. In the SRCNN model, n1 and n2 represent the number of output channels of the convolutional layers, and fx x fx represent the kernel sizes of the convolutional layers.
Bilinear and bicubic measurements are two common methods used in image interpolation, which is the process of estimating pixel values in an image.
-
Bilinear Interpolation: This is a technique for two-dimensional interpolation on a rectangle. It estimates a function's value at any location inside a rectangle if its value is known at each of the rectangle's four corners. The weights are based on the separation between the point and the corners for a
(x,y)position inside the rectangle. The weight of the corner increases the closer it is to the tip. -
Bicubic Interpolation: This method considers the closest 4x4 neighborhood of known pixels — for a total of 16 pixels. Since these are at various distances from the unknown pixel, closer pixels are given a higher weighting in the calculation.
In the context of your SRCNN model output, the bilinear and bicubic measurements can be used as baseline comparisons to evaluate the performance of the SRCNN model. The SRCNN model aims to produce higher resolution images that are closer to the original high-resolution images than those produced by bilinear or bicubic interpolation methods.
Lets take an example of one of the Set5 dataset output , flwoers: Its Bilinear and Bicubic value that we got are:Bicubic:
Degraded Image:
PSNR: 27.248686459559124
MSE: 367.56400047398984
SSIM: 0.8690622024599293
Bilinear:
Reconstructed Image:
PSNR: 19.376280568802578
MSE: 2252.026821898329
SSIM: 0.49185912300096296
- Bicubic Method:
- Degraded Image: This refers to the image after it has been downscaled and then upscaled using the bicubic method.
- PSNR (Peak Signal-to-Noise Ratio): The PSNR of 27.25 dB indicates the ratio of the maximum possible power of the signal to the power of corrupting noise. A higher PSNR indicates a better quality of reconstruction.
- MSE (Mean Squared Error): The MSE of 367.56 is the average squared difference between the original and the reconstructed image. A lower MSE indicates a better quality of reconstruction.
- SSIM (Structural Similarity Index): The SSIM of 0.87 measures the similarity between the original and the reconstructed image. A value closer to 1 indicates a better structural similarity.
- Bilinear Method:
- Reconstructed Image: This refers to the image after it has been downscaled and then upscaled using the bilinear method.
- PSNR: The PSNR of 19.38 dB is lower than that of the bicubic method, indicating a lower quality of reconstruction.
- MSE: The MSE of 2252.03 is higher than that of the bicubic method, indicating a lower quality of reconstruction.
- SSIM: The SSIM of 0.49 is lower than that of the bicubic method, indicating a lower structural similarity.
In summary, based on these metrics, the bicubic method appears to provide a better quality of image reconstruction than the bilinear method for your flower images. This information can be useful in your research paper to discuss the performance of different interpolation methods in the context of image super-resolution.
Test has been done on the Set5 dataset. Below output firgure shows how the SRCNN model perfomrs on the test dataset. As we can see it has not been acurate model yet. It shows the blurriesness into the output and more smoothness than the required. However, noise have been reduced than the low resolution image. More training and dataset has been required to train the model and get the accuarate reults.




In this project, we delved into the fascinating realm of single-image super-resolution, with the aim of improving the quality of low-resolution images to higher resolutions. Our main focus was on implementing the Super-Resolution Convolutional Neural Network (SRCNN) architecture, both by using pre-trained models and building the model from scratch.
Initially, we took advantage of a pre-trained SRCNN model obtained from the MarkPrecursor SRCNN GitHub repository to upscale low-resolution images. The results we obtained were quite impressive, showing significant enhancements in image quality, sharpness, and overall detail. This demonstrated the effectiveness of SRCNN in elevating image resolution.
Several factors may have contributed to the differences in performance between the pre-trained and custom SRCNN models. The pre-trained model benefited from extensive training on large-scale datasets, which allowed it to capture intricate patterns and details crucial for accurate image reconstruction. On the other hand, our custom implementation may have been hampered by limited training data or less-than-optimal hyperparameter settings, leading to less impressive results.
Furthermore, the nuances of the SRCNN architecture, such as kernel sizes, depth of convolutional layers, and learning rates, greatly influence the model's effectiveness. Even slight deviations in these parameters can have a significant impact on the model's ability to learn meaningful representations and generate high-quality reconstructions.
Moving forward, overcoming these challenges will require thorough exploration and experimentation with hyperparameter tuning, data augmentation techniques, and architectural adjustments. Additionally, exploring advanced super-resolution techniques, such as Generative Adversarial Networks (GANs) or attention mechanisms, holds promise for further enhancing image quality and realism.
In conclusion, while our attempt to implement the SRCNN architecture from scratch provided valuable insights and learnings, the superior performance of the pre-trained model highlights the importance of leveraging established frameworks and methodologies in tackling complex tasks like single-image super-resolution. Future research endeavors should focus on refining our custom implementation and exploring innovative approaches to push the boundaries of image enhancement and reconstruction.
#Directory Information
* Requirements
Python 3.x
TensorFlow
Keras
OpenCV
NumPy
Matplotlib
scikit-image
SRCNN_2XFactor.ipynb is using 2 factor of resize images- FINAL SUBMISIION IS THIS FILE
SRCNN_4XFactor.ipynb is using 4 factor of resize images
PDF conversion not showing text descriptions properly and not showing uploaded images
Data Preparation:
* img_matrix.py and img_resize.py files contain utility functions for image processing and resizing.
* HR (High-Resolution) images are required for training and testing. They can be stored in the ground_truth directory.
* LR (Low-Resolution) images can be generated from HR images using the img_resize.py script. The LR images are stored in the LR_Images directory.
Training:
* Run the train.h5 script to prepare the training data.
* Train the SRCNN model using the prepared training data by executing the srcnn_model.py script.
Testing:
* Ground_truth - Images used for training later converted into Low Resolution and saved in LR_Images folder
* Test the trained SRCNN model on Set5 and Set14 datasets using the predict5 and predict14 functions in the srcnn_model.py script.
* Evaluate the performance of the model by comparing PSNR (Peak Signal-to-Noise Ratio), MSE (Mean Squared Error), and SSIM (Structural Similarity Index) scores.
Results Visualization:
* Visualize the results by comparing the original HR images, degraded LR images, and reconstructed HR images using the SRCNN model.
Use the img_matrix.py script to calculate image quality scores.