This repository contains the source code to mining algorithm that identifies subpopulations where outliers are defined differently than in the rest of the population and might need adjustments in their protection.
Note: The user interface is in development and may contain bugs, incomplete form, and other interface affordances.
- Python 3.9
- Qt 6.1.2
Use the requirements.txt file with pip to install the necessary packages.
pip install -r requirements.txt
python main.py
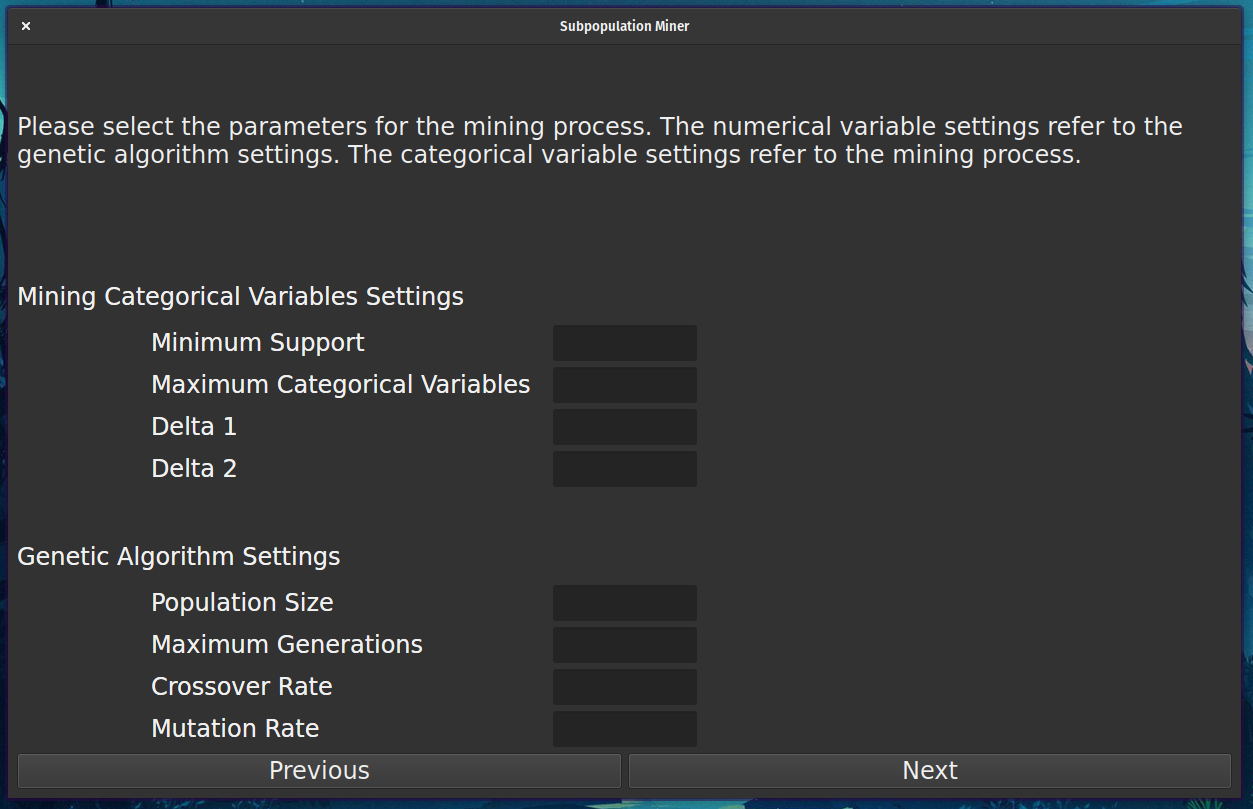
The user interface provides 5 step wizard to guide the user through the process.
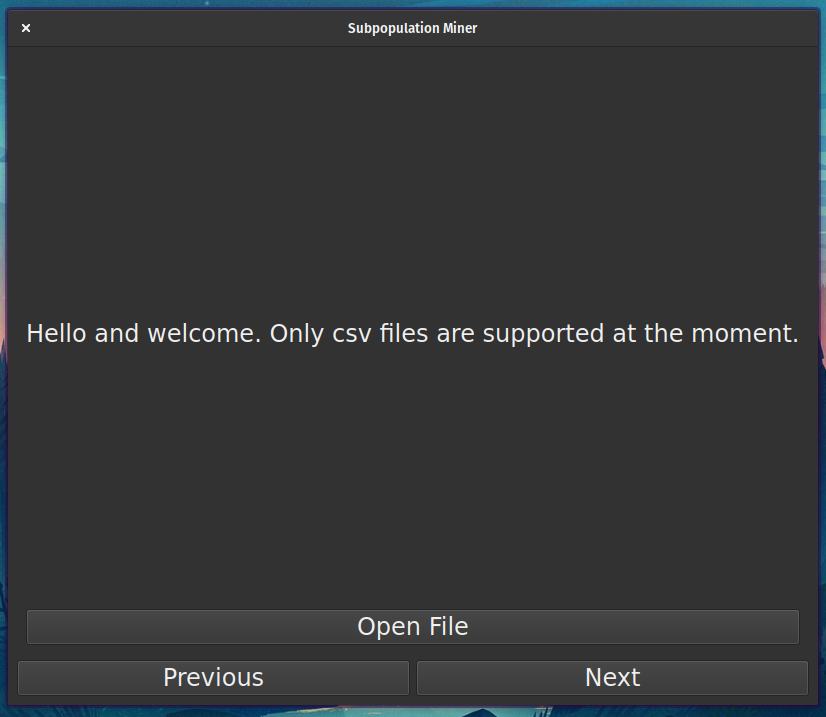
Load data: The user can load the data from a CSV file. The CSV file must contain a header row.
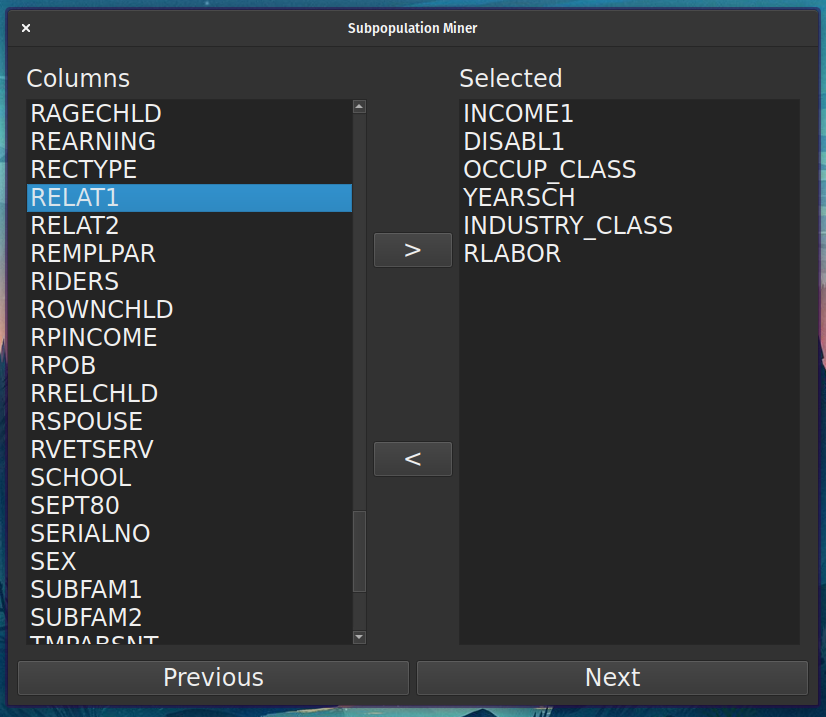
Select relevant columns: The user can select the columns that are relevant to the data protection project.
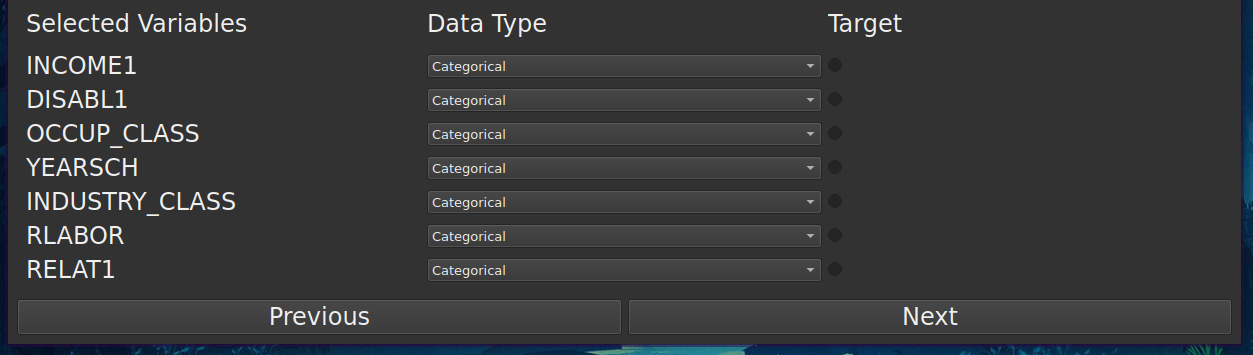
Indicate data types: The user needs to indicate the data types of the
selected columns. The data types are considered in two levels: the first
level is the general data type (numeric, categorical), and the second
level indicates if the variable is dependent or independent.
The dependent variable is a numerical variable outlier of which must be protected. The independent variables are categorical and continuous variables that define subpopulations.
The variable subject to protection is indicated by the user by selecting the target radio button.