A PDF Question Answering model using RAG Architecture using LlamaIndex🦙
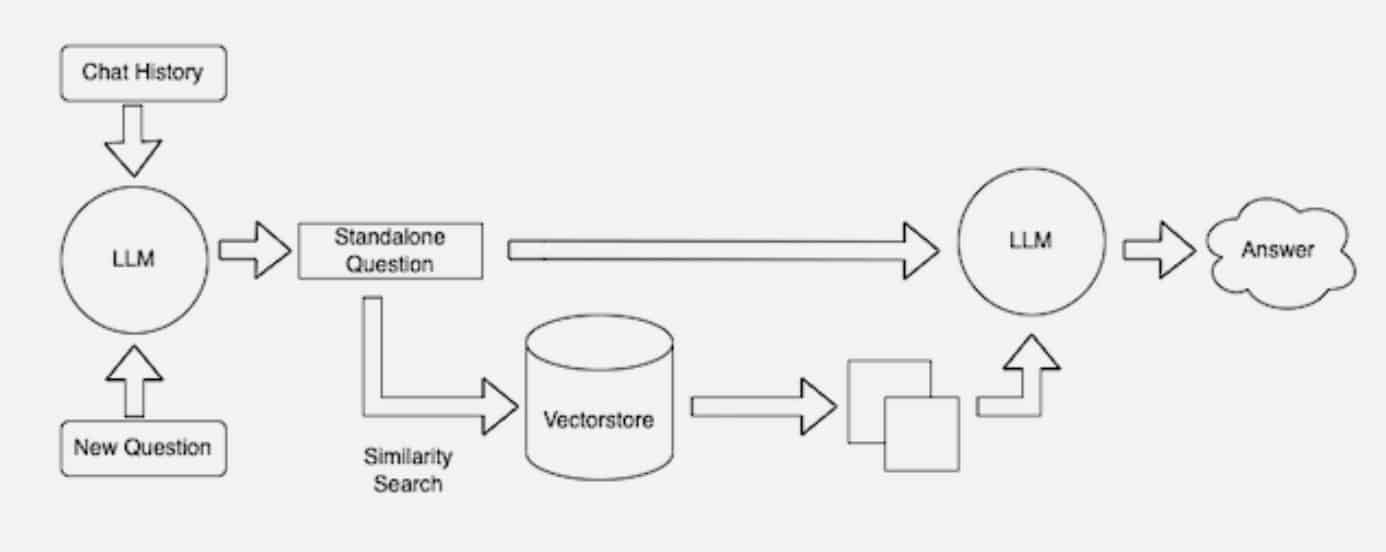
The model incorporates Retrieval Augumented Generation Arrchitecture which allows the LLM to respond the to the prompt from the provided context. Generally speaking the LLMs respond to the queries from the training data it was trained with, using RAG architecture we make use of the ability of the llm that generates text with the content Retrived from the documents we provide to the model
Just execute the code from the shell file in bash or just execute the statements in it separately in command prompt.
If you are gonna use a model from Huggingface you may need to login or authorized to use some gated models For that do the following in cmd on your virtual environment
huggingface-cli login
then login using your Huggingface token from your account and you can load any models from huggingface.
If you are not using HuggingFace LLMs you can modify the '
model_loading.py' file with the model path to yout local
The data loading is not automated yet, so you have to manually put path of the document in data_processing.py file
Soon this will be automated
After setting up everything just run the 'prompt_testing.py' and if you get a response with 10 answers then the model is functioning well and good.
Currently working on making this a interactive tool ,to have conversations with the document content
Note : The Code is still under development, currently working on implementing rag on csv files in addition to pdfs
]