{kind=link}
{kind=link}
{kind=link}
{kind=link}
In this project, I developed and implemented an ETL pipeline for processing well log data using advanced data engineering technologies in Databricks, Spark Structured Streaming and Delta Live Tables (DLT). The pipeline enabled the ingestion, validation, cleaning, and transformation of large volumes of well data, facilitating the extraction of valuable information for geophysical analysis.
Responsibilities:
- Implemented automated pipelines for converting LAS files to JSON format and loading them into Delta Lake.
- Transformed data using PySpark and SQL, including the creation of new metrics and data validation.
- Optimized pipelines by utilizing partitioning and Delta Tables.
- Developed interactive dashboards for visualizing and monitoring processed data.
- Automated real-time data ingestion processes.
Technologies: Delta Live Tables, Spark Structured Streaming, Auto Loader, SQL, PySpark.
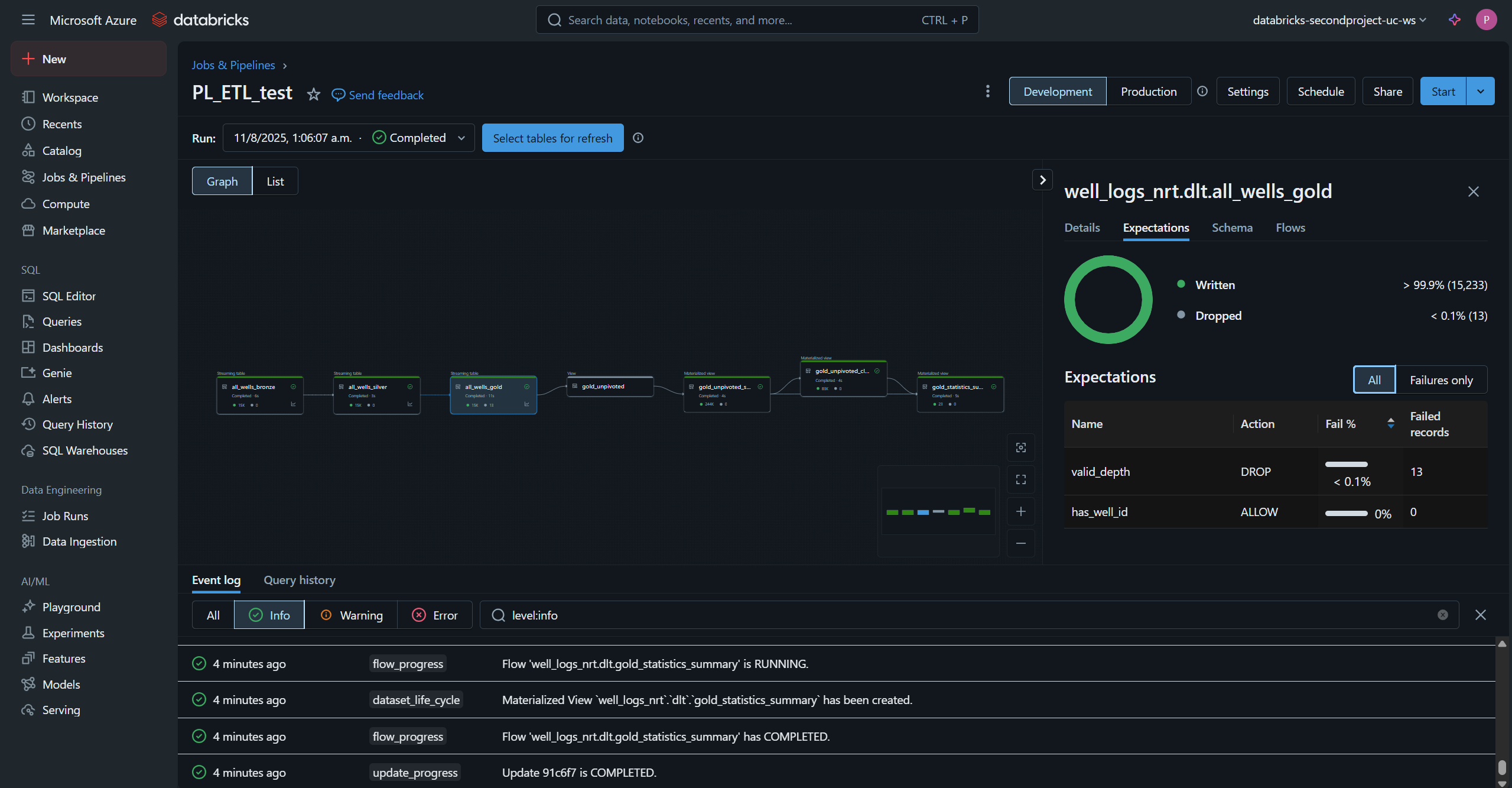
This diagram presents a detailed representation of the complete ETL process implemented to accomplish the proposed objectives for this project.

This graphyc shows some logs (i.e. GR, ILD, ILM and NPHI) from well 20_8_7.

Here you can find, for each available log, metrics such as the maximum, minimum, mean, standard deviation, and the range of valid measurements (i.e., only non-null values), among others.

This is the part that allows us to orchestrate the execution of DLT tasks (DLT decorator & functions) defined in the notebooks. Here you can see created tables and their lineage.