版本:这是第二版文档,正式定名挑战网大计基, 第一版为2024年做e时代的主人>
推荐用手机或者平板,可以躺在床上或者沙发上。在电脑上也可以使用 WIN + ← 将此文档放到屏幕一侧,右边可以用自己的IDE动手做实验。
可以按照顺序阅读,也可以直接跳到感兴趣的章节。
符号约定:
 这个用来表示暂时无需完全理解的细节问题,供深入研究和思考所用;
这个用来表示暂时无需完全理解的细节问题,供深入研究和思考所用;
 这个用来表示联想内容或是温馨提示;
这个用来表示联想内容或是温馨提示;
 这个用来表示下面的内容是一段笑话或是在项目开发过程出现的梗;
这个用来表示下面的内容是一段笑话或是在项目开发过程出现的梗;
 这个用来表示下面的内容是容易犯错的地方,特此警告;
这个用来表示下面的内容是容易犯错的地方,特此警告;
我们会在每章前面使用⭐标出本章难度,5星即为最重要的内容,只用文本难以阐述完全,需要大家查阅更多资料。也会指出本章涉及的编程语言,避免产生歧义。
写给读者:
这只是一份参考文档,并不能作为学习的唯一工具,我们推荐自己动手查阅更多资料,学习如何阅读官方文档,这对以后的学习开发非常重要。我们的培训不能覆盖到所有方面,而现实情况下我们遇到的问题和困难却是防不胜防的。本文档也将着力向大家传授部分阅读官方文档的方法。
另一方面,我们也不希望读者会对开发项目和写代码这些概念理解的过于沉重,代码只是我们在信息时代的一款语言,我们不需要去死记硬背各种标签或是函数,但是我们需要理解它们是一种什么样的存在,以及为什么而存在。
第二版特别增加了一些AI工具和debug工具的使用,这是为了更好的帮助现在大模型时代“沉浸式编程”的学习和工作。最后由于最近使用linux发行版系统人数越来越多, 而且,以后从事计算机相关工作的话难免会遇到linux系统或者服务器,于是适当增加了些linux的知识, 包含一些小配置和操作技术,具体可以直接参见最后一章, 当然其他内容里面也有一些零星的小知识点
最后一点,在计算机领域虽然看似很抽象,但是却比现实世界要单纯许多。希望我们社团的培训能够使大家产生对计算机的兴趣,进一步学会更多技能。也希望大家正确对待计算机,多多学习和实践,成为e时代的主人。
Note
本章作者:syl + wjj
难度:⭐
涉及语言:cmd bash
开机方法比较简单,连接电源通电后按下电脑 / 机箱的开机键,如果有需要的话再开启显示屏即可开机。
关机的方法多样,可以通过系统提供的关机选项,也可以使用命令行 (cmd, powershell, bash 等) 关机。以 cmd 举例:
#shell
#设置多少秒后关机
shutdown -s -t 秒数bash同理
-> shutdown --help
shutdown [OPTIONS...] [TIME] [WALL...]
Shut down the system.
Options:
--help Show this help
-H --halt Halt the machine
-P --poweroff Power-off the machine
-r --reboot Reboot the machine
-h Equivalent to --poweroff, overridden by --halt
-k Don't halt/power-off/reboot, just send warnings
--no-wall Don't send wall message before halt/power-off/reboot
-c Cancel a pending shutdown
--show Show pending shutdown
This is a compatibility interface, please use the more powerful 'systemctl halt',
'systemctl poweroff', 'systemctl reboot' commands instead.Windows 自带截屏工具,可以在 开始 -> 所有应用 里找,也可以使用更快捷的方法:Win + Shift + S
macOS,可使用 Command + Shift + 4,进行截屏
如果上面两种方式你都不喜欢,那么你也可以使用 QQ 的截屏工具,如下图

请务必不要使用手机拍屏,因为图片质量非常差,完全没法看清楚内容

快捷键打开:Win + R 然后输入 cmd 或者 powershell 就可以打开。
常用指令
说起路径,我们就不得不提到两个名词:绝对路径和相对路径。
绝对路径是从硬盘的根目录或者Web站点的根目录开始,指明文件的真实位置,路径单一,不易更改。
相对路径是从当前工作目录出发,指定一个文件的路径。使用相对路径时,路径是相对于当前目录的,这样可以使得文件在不同的目录下可以被访问。
例:
F盘的绝对文件(夹) F:\Riot Games\VALORANT
指向当前目录的子目录中的文件的相对路径 Genshin Impact Game\YuanShen.exe
指向从上一层目录开始的文件的相对路径 ..\osu!\scores.db
在相对路径中, .\ 指当前目录, ..\ 指当前目录的上一级目录, 后者可以嵌套使用, 如 ..\..\HMCL.exe
#shell
cd <目标路径> // 切换到目标路径
ls // 查看当前路径下的所有文件
mkdir -p <路径名称> //创建一个文件夹,如果没有-p参数,在重名的情况下会覆盖原来的文件夹
code <路径> // 用vscode打开目标路径。后面会讲vscode的安装和配置
exit // 退出终端-
最常用的肯定就是浏览器,推荐 Microsoft Edge 或者 Google Chrome 浏览器,当然 FireFox 也很好。至于国内那些逆天厂商的,只能说懂得都懂。现在的浏览器一般除了访问网页的基本功能以外也可以增加丰富的插件,大家可以按需求添加。
-
文件阅览的工具:大学中最常用到的就是 word 文档和 PPT, 也有 pdf 文档。可以使用系统自带的(如 Microsoft office),当然 pdf 直接就可以在浏览器中打开。我们社团也会经常用到 markdown 文档,这是 Github 主流的文档。可以使用 Typora 等工具预览和修改 markdown 文档,也可以使用 vscode(配置 vscode 见入门篇其 3)。
-
压缩工具:推荐 7zip, xz 等。在需要传输多个文件时,通常会打包成一个文件(可压缩可不压缩)再把这个文件发送给对方。在 Windows 11 / Mac OS 下压缩文件,可以直接选中想要压缩(打包)的文件,右键选择压缩即可。Linux 用户可参见实践篇其 1。
-
命令行工具:后续学习中将涉及到一些基本命令,Windows 用户可以学习一下 powershell, 比 cmd 好用。
 Linux 用户就默认会用了。
Linux 用户就默认会用了。其他的可以按需配置。
文件后缀名(File Extension)是一个在文件名后面的标识,用来指示文件的类型或格式。它通常由一个句点(.)后跟一到多个字符组成,例如 .txt、.jpg、.pdf 等。文件后缀名是计算机操作系统和应用程序用来识别文件类型的一种方式。
不同的文件后缀名通常表示不同的文件格式。例如:
.txt 表示纯文本文件。
.jpg 或 .jpeg 表示 JPEG 图像文件。
.pdf 表示 Adobe PDF 文档。
.html 表示 HTML 网页文件。
这些后缀名有助于计算机系统和应用程序根据文件类型选择适当的程序来打开或处理文件。它们也有助于用户快速识别文件类型,以便进行适当的操作。
按照如下的流程来打开文件的扩展名显示

F12 开发者工具是浏览器内置的一个特殊工具,用于帮助网页开发者调试和优化网站。它提供了一些有用的功能,让开发者可以更容易地理解和修改网页。
点击左上角的箭头图标(或按快捷键 Ctrl + Shift + C)进入 元素选择模式,从页面中选择需要查看的元素,可以在开发者工具元素(Elements)一栏中快速定位到该元素源代码的具体位置。

使用控制台来进行一些代码调试

- 字体:后续面对代码场景时建议选用等宽字体,视觉效果会比较好,另外还有些特殊的图标也可以显示,比如 Hard Nerd Fonts,或者 JetBrains Mono 系列的。
- 网站避雷:下载东西或者查阅文档时强烈建议访问官方网站,现在国内有一堆逆天的高仿网站,把免费的东西高价出售,用什么一键安装就是为了骗小白。
- 搜索引擎:建议使用必应、谷歌。
- AI 工具:现在使用 AI 已经烂大街了,我们当然允许使用 AI 解决问题,但是自己也得有所学习。更重要的是我们以后遇到困难的方面比如逻辑关系、数据分析等,这些并非 AI 的强项,而是我们自己需要思考的地方。所以不应该过度依赖 AI。
- 更新:Windows 用户请注意多更新你的系统,因为 Windows 的漏洞和病毒太多了(若是存储不足可以清除更新完成之后的旧版本,在设置里面修改即可)。Linux 重要软件上建议使用仓库源的话是 stable 版本的,毕竟谁也不能保证 xz 后门事件再次出现。但是另一方面我们以后用到的技术性的软件或者框架等建议时刻保持最新版本,因为旧版本可能有很多不支持的问题或是功能不完善。
- 入门可以通过网课、简单的教程快速先把握一门语言的基本语法和基本要点,可以使用菜鸟教程等入门教程网站。
- 完成基本语法后可以继续精进,这一阶段建议查看官方文档和社区论坛。例如学习 C./C++ 可以查阅 cppreference 等。
- 后面就可以了解语言在实际业务的应用。这一块需要我们了解框架,学会自己阅读框架官方文档,可能也要去查看框架的源码。另一方面也需要了解业务方面的通用工具,比如基本的算法,设计模式,语言特性等。
总之一句话,要自己学会搜索查阅,以及如何查阅官方文档。
Note
本章作者:cgy + Claude Sonnet 4
难度:⭐
涉及语言:汉语
什么是大模型(生成式 AI)?
- 它能做什么:聊天、答题、写文案、写代码、改错、总结、翻译、分析数据。
- 把它当成超级聪明的助手:能听懂自然语言,执行你给的任务,但需要清晰的> 指令。
- 核心能力:理解(读懂你说的)、推理(按逻辑解决问题)、生成(写出内容)。
为什么需要掌握大模型工具?
- 提升学习效率:快速获取知识点、要点总结、例子对照。尤其在你不清楚一个知识的背景时,你可以追问它的回答中你不知道的概念,以全面理解相关知识。
- 辅助编程:生成代码、解释报错、编写单元测试、梳理思路与边界条件。
- 创意与文档:闪击各种水课的报告(不过请根据课程要求合理使用)
- 文本生成:我个人的推荐是 Claude, Gemini, ChatGPT
- 提问技巧:
- 核心原则:清晰、具体、有约束。不要问得太宽泛。
- 结构化:可提供背景、目标、限制、输出格式。
- 丰富上下文:模型需要足够的信息才能生成准确的答案。给你提供的上下文加上引号有助于模型判断哪些是你的指令,哪些是上下文信息。问 Gemini 日语单词的意思但不加引号,会导致它以为你说日语,然后用日语回答你
- 角色扮演:如果有特定领域需求,可让模型扮演相关角色。如“经验丰富的后端工程师”、“攻击力极强的贴吧老哥”(慎用)。
- 迭代与追问:可拆解相关问题,分步地来解决,一次性让模型完成大量需求效果可能偏差。
- 警惕 XY 问题:现今大模型大多是推理模型,且推理能力强大,因此只需给它期望结果,不必为它提供思维路径。
- 示例提示词:
- “我是一个计算机小白,给我讲解 RESTful API。请同时介绍背景知识,让零基础也能听懂。生成一份 md 文档”
- 提问技巧:
- 辅助编程:以 GitHub Copilot 为例
- 安装与配置:VS Code / JetBrains IDE → 扩展市场搜索“GitHub Copilot” → 安装 → 登录 GitHub → 启用建议。
 建议注册 GitHub Education Pack,可白嫖顶级大模型。
建议注册 GitHub Education Pack,可白嫖顶级大模型。- 用法速览:
- 注释驱动:写注释说明这个函数的行为,等待自动补全。
- 片段生成:选中函数签名,按下触发快捷键查看建议多样化方案。
- Copilot Chat:
 这个是重头戏,用好它会让你的写代码体验起飞。点击 VS Code 上方搜索栏右侧的小机器人,即可调出 Copilot Chat。有三种模式:chat, edit, agent。chat 模式下只会回答你的问题(回答中会包含建议代码),edit 模式会对你提供的上下文(即你希望它读取和修改的文件)进行修改,agent 模式会主动分析上下文以执行测试、重构等复杂任务(轮椅程度依次递增)。可根据需求来灵活使用。
这个是重头戏,用好它会让你的写代码体验起飞。点击 VS Code 上方搜索栏右侧的小机器人,即可调出 Copilot Chat。有三种模式:chat, edit, agent。chat 模式下只会回答你的问题(回答中会包含建议代码),edit 模式会对你提供的上下文(即你希望它读取和修改的文件)进行修改,agent 模式会主动分析上下文以执行测试、重构等复杂任务(轮椅程度依次递增)。可根据需求来灵活使用。

- 局限性
- 可能错误、过时、缺上下文;不懂你隐含的前提;对非公共数据一无所知;
- 目前大模型还 handle 不了复杂项目,单纯 vibe coding 会写成屎山,需求分析与架构设计仍需人工。
- “幻觉”与事实核查
- 由于大模型本质只是在重复它学到的模式,并不是真正的理解,因此有小概率生成看上去正确实则错误的结论。需要用户有辨别能力。
- 可要求给出来源链接或版本号;关键信息二次验证(官方文档/实验复现/运行结果)。
- 对代码:跑测试、看日志、加断言;对结论:用小样本先试,再推广。
- 避免过度依赖
- 模型只是辅助,目前仍无法替代人工。保留独立思考与基本功训练,才能让你在复杂项目的开发中得心应手。
- 多做“闭卷练习”:先自己写,再让模型评审与改进。
Note
本章作者:
难度:⭐
涉及语言:html, css
网页是构成网站的基本元素,是承载各种网站应用的平台。通俗地说,网站就是由网页组成的。网页是一个包含 HTML 标签的纯文本文件,它可以存放在世界某个角落的某一台计算机中,是万维网中的一“页”,是超文本标记语言格式(标准通用标记语言的一个应用,文件扩展名为 .html 或 .htm)。
网页由多个元素构成,每个元素都有其独特的功能和作用。
一般情况下,网页中最多的内容是文本,可以根据需要对其字体、大小、颜色、底纹、边框等属性进行设置。
丰富多彩的图像是美化网页必不可少的元素,用于网页上的图像一般为 JPG 格式和 GIF 格式(当然还有无限缩放而不失去清晰度的 SVG 格式)。网页中的图像主要用于点缀标题的小图片,介绍性的图片,代表企业形象或栏目内容的标志性图片,用于宣传广告等多种形式。
 这个挑战 logo 就是由以下代码导入的
这个挑战 logo 就是由以下代码导入的
<!-- .html文件 -->
<img src="images/tenzor.svg" alt="img" width="25px"> 上面的一串代码中,img 标签被添加了三个属性,其中 src 属性规定了图像的路径、alt 属性规定了图像无法显示时的替代文本、width 属性规定了图像的宽度。除此之外,img 标签还有 height、draggable 等属性,大家在后续学习中会逐渐接触到。
超级链接是 Web 网页的主要特色,是指从一个网页指向另一个目的端的链接。这个“目的端”通常是另一个网页,也可以是下列情况之一:相同网页上的不同位置、一个下载的文件、一副图片、一个 E-mail地址等。超级链接可以是文本、按钮或图片,鼠标指针指向超级链接位置时,会变成小手形状。
<!-- .html文件 -->
<a href='https://www.tiaozhan.com/'>跳转至挑战网首页</a>动画是网页中最活跃的元素,创意出众、制作精致的动画是吸引浏览者眼球的最有效方法之一。但是如果网页动画太多,也会物极必反,使人眼花缭乱,进而产生视觉疲劳。
下面的代码定义了一个动画,实现了一个元素颜色的变化。
/* .css文件 */
@keyframes animation {
from {
color: red;
}
to {
color: green;
}
}表单是用来收集访问者信息或实现一些交互作用的网页,浏览者填写表单的方式是输入文本、选中单选按钮或复选框、从下拉菜单中选择选项等。
姓名: 性别: 男 女
<!-- .html文件 -->
<input placeholder="请输入你的姓名" style="background-color:white">
<input type='radio' name="gender" style="background-color:white">男
<input type='radio' name="gender" style="background-color:white">女Note
本章作者:syl + wjj
难度:⭐
涉及语言:无
另外提醒一下,我们后端首选的是golang语言,但是windows defender会去在你编译go代码的时候扫你的文件,导致编译时间长的离谱(傻逼微软)。因此,真心推荐(不是强制)使用linux发行版,或者次一点用wsl(windows subsystem linux),当然你要是能忍受一个代码编译几分钟以上的,我也没什么说的
编辑器和 IDE $$ 编辑器 \neq IDE! $$
编辑器是程序员用于编写和修改源代码的软件工具。它提供了文本编辑的基本功能,如插入、删除、复制和粘贴等,以及针对编程语言的特定功能,如语法高亮、代码折叠和自动完成等。本身并不参与代码的执行和转换,如 vscode,记事本。
IDE 是一种集成了多种开发工具和功能的软件应用程序,旨在提高软件开发的效率和质量。它通常包括源代码编辑器、编译器、调试器、构建工具、版本控制系统等,为程序员提供了一个全面的开发环境。集成了多种开发工具,方便程序员在同一个界面下完成开发任务。提供了丰富的功能和插件,满足不同开发需求。支持代码自动完成、语法高亮、代码重构等,提高编程效率和质量。可以自动管理代码库、构建工具和文档等,减少手动操作的时间和错误。如 Visual Studio,IDEA,Pycharm。
我们在入门过程中不需要完全理解编译器的原理,而是选择使用合适的编辑器或者 IDE 来开发项目。我们推荐使用 vscode 来进行开发工作。
使用记事本来写代码显示我们太逊了 😇,我们需要一个更酷炫更方便的开发工具。
这里推荐大家使用 Visual Studio Code 编辑器,先到其 官网下载 安装。选择适合自己电脑的发行版进行安装。windows 就一条龙到底就行了。记得选择添加到 PATH 中,这样方便以后在终端直接 code . 打开这个项目文件夹。桌面快捷方式可以自行选择是否创建。

现在我们已经完成了软件的安装。但是打开 vscode 的话里面还是空空的,因为它本身只是一个文本编辑器,我们需要安装一些插件来让它变得强大 (:yum: vscode 补全计划)
下面我们以配置 html 开发环境为例,其他语言如何配置可以查阅相关文档。先介绍 vscode 上几个常用组件。
插件市场
vscode 自身的产品思路就是一个轻量级的开发工具加上繁荣开放的插件市场组成。因此很多强大的功能需要通过安装插件来实现,目前 vscode 的插件市场中已经有着几万个插件。通过 侧边栏上的按钮 或快捷键 Ctrl + Shift + X 打开 vscode 的插件市场。

命令面板
vscode 的命令面板能让我们快速方便地执行很多功能与命令,包括自身的设置和插件提供的功能等。
通过 View -> Command Palette 或者快捷键 Ctrl + Shift + P 可以打开命令面板。

配置面板
通过 File -> Preferences -> Settings 或 Ctrl + , 打开配置面板。

简单的配置启动 HTML
在插件市场搜索并下载一些插件,下面是一些常用的开发 html 的插件,当然你也可以自行下载:
-
中文插件
-
Live Server可以将当前项目映射到本地的 IP 的端口,通过这个端口就可以像访问网站一样访问项目文件,对我们前端项目开发中的实时预览很有帮助。 -
Prettier是一款强大的格式化插件,支持多种前端语言。
安装插件后还要配置一下,按下 Ctrl + , 打开配置面板,输入 format 过滤配置项。将 Default Formatter(默认格式化工具) 选择为 Prettier,我个人还习惯将 Format On Save(保存时格式化) 勾选上。
-
CSS Peek能够帮助我们快速地定位、预览样式的定义。 -
JavaScript (ES6) code snippets可以帮助我们快速地插入代码块,支持以下多个前端语言。
- JavaScript (.js)
- TypeScript (.ts)
- JavaScript React (.jsx)
- TypeScript React (.tsx)
- Html (.html)
- Vue (.vue)
下载了一些插件之后,就可以进行简单的 html 网页开发了。
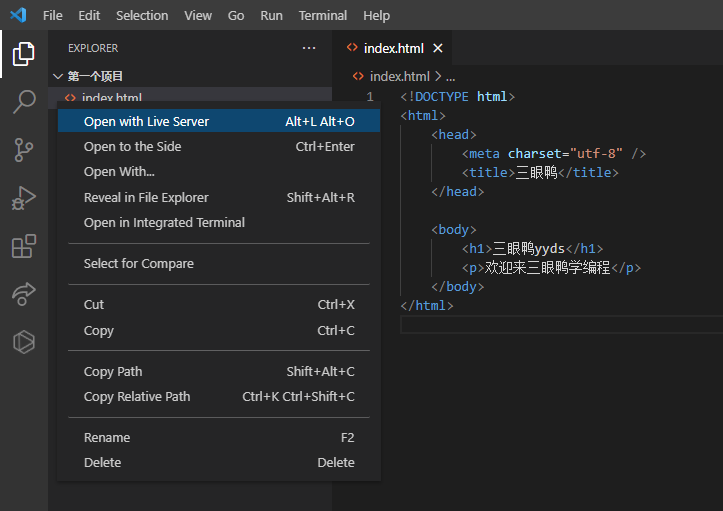
新建一个 HTML 文件,输入代码保存。右键 Open with Live Server 便会打开一个浏览器实时显示我们的页面
我们经常需要将某些路径添加到系统变量中,这样方便我们可以快速调用它们。下面以 windows 平台为例,演示如何添加环境变量。

点击“环境变量”选项后,可以设置变量名和值。

完成以后点击确定,就可以保存到环境变量了 😊
我们上网冲浪的时候,经常会看到好多人在吵用什么工具写程序是最好的。下面是全网统计的编译器 / IDE 受欢迎图:
但是 😰 visual studio 太重了!!而且 vs 主要经营 .Net 的开发和调试,也不是我们的主力语言。相比之下 vscode 便捷而且拥有海量插件,配置的好的话也不会比 vs 差到哪去。
不过市场上其他的编译器和 IDE 同样值得推荐,比如 Jetbrains 全家桶中的 idea(收费,建议使用学信网去申请个教育包),vim(门槛较高),用起来也是很爽的。IDE 的好处是开盖即用,不需要再过多配置,但是可能比较重而且不够自由。
Note
本章作者:syl
难度:⭐⭐
涉及语言:C/C++
注:考虑到大部分人会学大学计算机,这门课有的使用的是 C 语言,所以我们也是用 C 语言举例。可以先行配置 C 语言环境,Windows 用户需要提前下载 MSVC(下载并配置到 VSCode 里的流程点这里)或者 MinGW(下载并配置到 VSCode 里的流程点这里)。
正如同现实世界中将物质分成了各种类型一样,计算机世界里也将数据存储为了各种类型。相对的,也存在这最小的存储单元:位 (bit,或者缩写为 b),也就是一个 0 或者 1。我们通常的信息计量单位是字节 (byte,缩写为 B),一个字节是 8 个位。同样的,数据的不同类型也有着不同的大小 (size)。下图列举了一些常见的类型和其大小。以 C 语言中的为例:
| 类型 | 占用存储空间 | 表示范围 |
|---|---|---|
| bool | 1 字节 | true 或者 false |
| 单精度 float | 4 字节 | -3.403e38 ~ 3.403e38 |
| 双精度 double | 8 字节 | -1.798e308 ~ 1.798e308 |
| int | 32 位系统 4 字节 64 位系统 8 字节 | -2^31 ~ 2^31-1 或 -2^63 ~ 2^63-1 |
| uint | 32 位系统 4 字节 64 位系统 8 字节 | 0 ~ 2^32-1 或 0 ~ 2^64-1 |
| char | 1 字节 | 存储 ASCII 字符 |
另外还有类似 int8,int64,string 等类型,大家可以自行搜索做了解。
这些数据在计算机底层都是存储在某个地址中,可能是 0x00 这个位置上存了一个 int 值 1,地址就相当于是变量家的门牌号,变量值就像家里的东西,知道了门牌号自然就知道了如果找到这个房子,进而知道了家里的东西是什么。
当我们知道了如何表示和存储数据后,就可以来尝试来一段代码了:这里就用 C 语言来演示 声明/定义变量的方式:[变量类型] 变量名 = 某个值或者表达式
//C
#include<stdio.h>
int main(void){
int integer = 1;
bool condition = false;
char letter = 'a';
printf("my first variable: %d",integer); // 输出 my first variable: 1
// ... 其他也可以自行尝试查看如何输出
}
我们也可能会遇到定义的变量类型和我们需要的类型不一致的情况,这时我们需要转换这个变量。一般情况下有隐式转换和显示转换两种方式,读者可以自行查阅了解相关内容,如何转换以及什么情形下可以转换。
注意:有些符号我们称之为“关键字”,这是语言本身提供的,用来编写代码的元素。比如上面的 int, bool 等。我们给变量起名时不可以和关键字重名。大家可以自行查阅常用关键字。
有没有想过把一堆同样类型的变量放到一起?就像我们学校每个专业都是同学的集合一样。我们可以使用一个叫做 数组 的数据结构来存储。顺便一提,数组本身也是一个变量,我们会在指针章节细说。
//C
//声明和使用数组:以 c 语言为例
// 变量类型 数组名[大小] = {好多变量 用“,”隔开}
//举一个整型数组的例子:
int arr1[3]={1,2,3}; //这里的 3 是数组大小,如果后面括号里写出了所有要存储的变量的话可以省略大小,编译器会自动推断出来。
//访问数组:通过 数组名[索引] 找到对应位置的变量值
int a1 = arr1[0]; //注意不同语言索引计数可能不一样,c 语言是从 0 开始的
arr[2] = 10; //给对应位置赋值/修改值
int a3=arr1[3]; //出界啦!![]() 课外阅读:编程语言是怎么被实现出来的? 这篇文章用生动的语言简述了编程的底层逻辑,有精力的话推荐阅读下。
课外阅读:编程语言是怎么被实现出来的? 这篇文章用生动的语言简述了编程的底层逻辑,有精力的话推荐阅读下。
将变量通过某些运算符号连接起来,就是表达式了。比如在 C 语言中,
//C
int v1 = 100;
float v2 = 200;
// 表达式举例
float expression_1 = v1+v2;
float expression_2 = v2-v1;
bool equal = v1==v2;
//表达式也可以连接起来:使用 () 来改变运算顺序
float expression_3 = 3*(expression_1+expression_2)
// 更多可以自行探索一般来说基本运算符是:+,-,*,/ :这是表示四则运算的符号。使用 % 取余。不同语言可能有差异。
逻辑运算会返回真,假两个值其中之一,判断规则是第二列所示。这里还是使用 C 语言的运算符演示:
| 符号 | 含义 |
|---|---|
| == | 左右两个元素是否相等 |
| != | 左右两个是否不相等 |
| > | 左边是否大于右边 |
| < | 左边是否小于右边 |
| >= | 左边是否不小于右边 |
| <= | 左边是否不大于右边 |
| && | 左边和右边同时成立 |
| || | 左边或者右边成立 |
| ! | 逻辑非,将真变为假,假变为真 |
一般情况下,编程语言中都是在 if 关键字语句中使用逻辑运算,也称 "控制语句",例如在 C 语言中:
// C
// 格式:
// if (condition) {
// code here will be executed if condition is true
// } else {
// code here will be executed if condition is false
// }
int a = 10;
int b = 20;
if (a >= 0 && b <= 30) { //判断如果 a 不小于 0,同时 b 不大于 30,如果成立则执行 if 语句内部的代码
printf("right!");
}
if (a != b){ //判断如果 a 不等于 b,成立则执行内部代码
//...
} else if (a < b){ // 继续判断,如果 a 小于 b, 执行内部代码
printf("a is smaller!");
} else { //如果之前的判断都不成立,执行这个内部的代码
pritnf("b is smaller!");
}另一方面,我们也有所谓的“循环语句”,以 for 关键字为例,
// C
// 全写格式是: for(initial; final; operation)
int i = 0;
for (; i < 10;) {
printf("%d", i);
i = i + 1;
}
// 这个等价于
for (int j = 0; j < 10; j++) {
printf("%d", j);
} 可以自行查询 switch, while, goto 等控制、循环语句关键字的作用
(这一部分建议自行了解,下面的表格还是以 C 语言为例)
| 符号 | 描述 | 运算规则 |
|---|---|---|
| & | 与 | 两个位都为 1 时,结果才为 1 |
| | | 或 | 两个位都为 0 时,结果才为 0 |
| ^ | 异或 | 两个位相同为 0,相异为 1 |
| ~ | 取反 (非) | 0 变 1,1 变 0 |
| << | 左移 | 各二进位全部左移若干位,高位丢弃,低位补 0 |
| >> | 右移 | 各二进位全部右移若干位,高位补 0 或符号位补齐 |
位运算我们一般用的不多,不过可能有时候会出现左移和右移的代码,通俗来讲,左移后移就是乘以 2 的某次幂:
// C
int a = 1;
a << 2; // = a * (2^2)
a >> 1; // = a / (2^1) 在开发过程中往往会有多个运算符出现在一起,和数学上的运算一样,这时候需要规定运算顺序,以及如何改变运算顺序。
在开发过程中往往会有多个运算符出现在一起,和数学上的运算一样,这时候需要规定运算顺序,以及如何改变运算顺序。
这里是一份以 C 语言为例的运算符优先级排序,其他语言可以自行查阅了解。 有些运算符我们现在还没有提到,可以搜索看看都是什么。
| 优先级 | 操作符 | 描述 |
|---|---|---|
| 1 | ++ -- |
后缀自增自减运算符 |
() |
函数调用 | |
[] |
数组下标 | |
. |
类成员变量 | |
−> |
类成员变量(指针访问) | |
(*type*){*list*} |
复合字面量 | |
| 2 | ++ -- |
前缀自增自减运算符 |
+ − |
一元加减法 | |
! ~ |
逻辑非和位运算非 | |
(*type*) |
显式类型转换 | |
* |
解引用 | |
& |
取地址 | |
sizeof |
Size-of | |
_Alignof |
对齐 | |
| 3 | * / % |
乘法,除法,取余 |
| 4 | + − |
加法和减法 |
| 5 | << >> |
左移和右移 |
| 6 | < <= |
小于和不大于 |
> >= |
大于和不小于 | |
| 7 | == != |
等于和不等于 |
| 8 | & |
位运算与 |
| 9 | ^ |
位运算异或 |
| 10 | | |
位运算或 |
| 11 | && |
逻辑运算与 |
| 12 | || |
逻辑运算或 |
| 13 | ?: |
三元条件判断符 |
| 14 | = |
赋值运算 |
+= −= |
加、减到左边 | |
*= /= %= |
乘、除、取余到左边 | |
<<= >>= |
左移、右移到左边 | |
&= ^= |= |
位运算到左边 | |
| 15 | , |
逗号 |
Note
本章作者:syl
难度:⭐⭐⭐
涉及语言:C/C++
什么是函数:我们一般将某个可以 控制何时使用,可以 传入参数,处理后 存储返回信息 的代码块称作过程,在高级编程语言中,它也被称为函数。
举个例子:C 语言中函数的结构是这样的:
// 定义
[返回值类型] 函数名(传入参数) {
//函数体
return 某个需要返回的值或表达式
}
// 调用
函数名(选择传入某些参数) //这里()是必需的,调用函数会得到这个函数返回的类型和值来几个术语:
调用:在代码中某个地方使用已经定义的函数
传参:将需要的参数传入函数进行处理
函数体:在{}中处理参数的过程
返回:函数处理传入的参数后返回结果
下面是 C 语言一个完整的函数定义与调用:
//C
int twice(int i){
return i*2;
}
int main(){
int i=1;
int j=twice(i);
printf("%d",j);
} 你可以把定义过的函数视作一个待使用的变量,可以扔到另一个函数里调用 (称为回调,会在指针章节谈到),也可以自己调用自己 (称为递归)。但是如何使用变量和函数需要注意它们的生命周期,我们会在后面介绍生命周期这个概念。
//递归的例子:计算第n项斐波那契数列的值
int fibonacci(int n){
if(n == 1)
return 1;
if(n == 2)
return 1;
return fibonacci(n-1)+fibonacci(n-2);
}-
变量和函数都遵循先声明后使用的原则,虽然近年来大部分语言支持了部分变量和函数的声明可以在调用的之后,但是出于良好的学习和实践代码开发规范的需求,我们还是推荐先声明再使用的原则。
-
一般情况下,一个 {} 里的全部内容称作代码块,代码块内部可以定义变量,调用函数等。我们称在某个代码块内部定义的变量为它的局部变量,对应的,在整个代码文件中、在所有 {} 之外定义的就是全局变量。如果 A 代码块在 B 代码块的外部,那么 A 代码块是不能使用 B 代码块的局部变量的。(相当于你的钥匙没法打开隔壁宿舍的门,更进一步的,你也可以认为某些实数域上的法则是不能放到复数域的)。
下面是 C 语言中的一个例子:
//C
int global_number = 1;
void foo(){
int function_number = 2;
}
int main(){
//这里是main函数的内部
int local_number = 3;
printf("global variable: %d",global_number); //可以使用这个变量
printf("foo variable: %d",function_number); //出错啦,这是个foo的局部变量
printf("main variable: %d",local_number); //可以,这是main函数自己的变量
}当然你可以在一个 {} 内写另一个 {},而更内部的能访问外部的,类似于你能打开自己的宿舍门,也能打开宿舍里面的柜子门。
这边是变量的生命周期的概念之一,{} 结束时,里面的局部变量会被自动销毁,除此之外我们还可以手动控制一些变量的生命周期。
我们需要介绍几个概念,栈、堆,静态区和常量区。这里它们不是数据结构的栈和堆,而是在内存中的位置。栈用来存储局部变量、函数以及函数的返回值,这一部分我们用户是没法去干涉的。堆则是我们手动分配的内存,可以去做改变。(这一部分我们会在讲到指针的时候讲解,先做了解)。静态区存储全局变量和静态变量,常量区则是存储常量。
顺便提一下,函数也是一个变量,函数名便是指向了它地址的指针。我们会在讲指针时细说。当然众所周知,指针各方面威力都很大,所以我们现代很多语言默认都不提供指针操作了。这里就还是用 C 语言举例子:
//C
//常量
#define PI 3.14
//静态变量
static int zero = 0;
//栈上变量,也称为自动生命周期变量
void test(){
int tmp=10;
}
int main(int argc, char** argv) {
int tmp=20;
test();
}
//在函数 test中声明的 tmp变量只有在test函数被调用时才会分配空间,当函数调用结束后自动释放。
//同时main中tmp变量也局部变量。虽然 test和main函数中有同名的 tmp变量,两者是互不可见的,或者说两者存在于 2 个不同的时空中
//手动分配内存,分配了10个int类型大小的内存给了数组array
int array[10]=(int *)malloc(10*sizeof(int)) 大家可以自行了解更多相关概念,比如静态变量是什么,语言的内存结构是什么。
当然我们也有各种方式来管理变量生命周期,比如使用移动等方式。这些我们会在以后学习中遇到。
在 C 语言中,我们写一个 swap 函数如下
//C
void swap(int a,int b){
int tmp = a;
a = b;
b = tmp;
}
int main(){
int a=1;
int b=2;
swap(a,b);
printf("a= %d,b= %d",a,b); //仍然是a=1 b=2;
} 我们说调用函数时传入了实际参数,简称实参; 而函数接收的参数是形式参数,简称形参,顾名思义这就是实参的副本,所以对形参动手动脚是不会影响实参的。我们称这种传参方式为值传递。导致值传递没有交换成功的原因,还是之前说的那个生命周期的问题。要明确的一点是,形参其实就是函数的局部变量。
//这是古早的c的写法,可以看到形参真正的样子是这样的
void swap(){
int a;
int b;
// ...
}看了这个古早 C 语言,你应该立刻理解了为什么说形参就是实参的副本这个原理。所以如果想要改变实参,方法有两个,一个是用返回值把实参覆盖掉,另一个就是传入实参的地址。后者便是下文的解决方法。
一个解决方法是使用引用传递,对于变量进行修改,我们不传入变量的值,而是传入变量的地址,我们会在指针章节细说这是怎么实现的,现在可以先做了解:
//C
void swap(int *a,int *b){
int tmp = *a;
*a = *b;
*b = tmp;
}
int main(){
int a=1,b=2;
swap(&a,&b);
printf("a=%d,b=%d",a,b); //现在就是a=2 b=1了
}((((这其实就像我们数学上,先设了一个矩阵是 A, 然后把 A 带入了某个变换中,得到了 B 是变换后的值。但是 A 还是原来的 A.
另一种曲线救国,但是其实本质上还是引用传递(后续章节会解释这是为什么)。
我们之前提过数组这个概念,所以可以这样设计:
//C
void swap(int arr[]){
int tmp = arr[0];
arr[0] = arr[1];
arr[1] = tmp;
}
int main(){
int arr[] = {1,2};
swap(arr);
printf("a=%d,b=%d",arr[0],arr[1]);
}Note
本章作者:wjj
难度:⭐⭐⭐
涉及语言:C/C++
经过上面的简单介绍,你应该已经了解了简单的代码知识。现在我们就来实践一下,如何写出一个简单的程序。
// C
#include "stdio.h"
void insertionSort(int arr[], int n) {
int i, key, j;
for (i = 1; i < n; i++) {
key = arr[i];
j = i - 1;
while (j >= 0 && arr[j] > key) {
arr[j + 1] = arr[j];
j = j - 1;
}
arr[j + 1] = key;
}
}
void output(int arr[],int len) {
for (int i = 0; i < len; i++) {
printf("%d ",arr[i]);
}
printf("\n");
}
int main() {
int arr[] = {454, 7, 16, 644, 76, 78, 13};
int len = 7;
printf("排序前的数组:");
output(arr, len);
insertionSort(arr, len);
printf("排序后的数组:");
output(arr, len);
}这是一个插入排序的例子,将一个 int 数组按从小到大的顺序排序。 在安装了 Code Runner 插件的前提下你可以在 vscode 代码区右键,然后点击 RunCode 即可运行。顺便一提,Code Runner 可以支持多种语言的运行与调试,也可以手动配置编译选项(我们会在编译章节介绍编译参数选项),大家可以自行尝试更多功能。如下图所示,vscode 中右键后出现在最上面的 Run Code 选项就是这个插件的效果之一。
插入排序:维护一个已经排序好的数组,依次将后面的元素按大小顺序插入到合适的位置。将第一个元素看作已经排序好的数组,然后将后面的元素依次插入,时间复杂度是 $O(n^{2})$

Note
本章作者:syl
难度:⭐⭐⭐⭐⭐
涉及语言:C/C++,Go
你可能早就听闻了指针的大名。2024 年的全球 Windows 蓝屏的原因就是一个经典的野指针访问。(图片来自 b 站 epcdiy)

另一个臭名昭著的叫调用空指针,同样是程序爆炸的典中典了。
下面是摘自维基百科的定义:
在计算机科学中,指针是一种最简单形式的 引用(reference)。
指针有两种含义,一是作为数据类型,二是作为实体。前者如字符指针、浮点数指针等等;后者如指针对象、指针变量等。
指针引用(reference)了存储器中一个地址。通过被称为指针解引用(dereference)的动作,可以取出在那个地址中存储的 值。保存在指针指向的地址中的 值,可能代表另一个 变量、结构、对象 或 函数。但是从指针值是无法得知它所引用的存储器中存储了什么资料类型的信息。可以打个比方,假设将存储器当成一本书,那么一张记录了某个页码加上行号的 便利贴,可以被当成是一个指向特定页面的指针;根据便利粘贴面的页码与行号,翻到那个页面,把那个页面的那一行文字读出来,就相当于是对这个指针进行解引用的动作。可做一模拟以增强对指针的理解:整数(integer)也是一类数据类型及其对象或 变量,可定义具体的数据类型如短整数(short)、长整数(long)、超长整数(long long)、无符号整数(unsigned)等等;也可以用于称呼整数值、整数对象、整数变量等。又如,一个浮点数指针(float *),可称作指向了一个浮点数类型的对象。
这一段话初看可能很迷惑,但是重点就在于,指针存储的信息,是内存中某一变量的地址,而不是直接存储变量的值。
这里解释一下值和引用的区别:如果我想知道你在家里做什么,值相当于你告诉我在做什么,是一个给出了一个副本的过程;引用就是相当于指针找到了你家的门牌号,通过指针就可以直接找到你在哪里、在家里做什么。 我们可以参考这个图片:

在 C 语言中,指针和引用的使用方式是这样的:
//C
//取出某个变量地址,用 &
int a = 1;
printf("address of a is %p", &a);
//定义指针使用 [类型]*指针名 = 变量地址
int *p = &a;
// 使用指针需要解引用,使用 *
int b = *p + 1;
printf("b is %d",b); //2在了解了指针的概念后,我们可以深入探讨以下前面写过的变量生命周期的问题。先来了解一下编程语言的内存结构(不同语言可能有不同的标准内存结构),我们以 C 语言内存结构 为例介绍变量是如何存储的(实际上这就是 linux x86_64 gnu 的内存结构)

我们主要描述堆和栈,其他大家自行了解即可。
我们在上面提到过,栈区 是编译器 自动管理的部分,我们用户不能也不需要干涉。这里主要是存储 局部变量、函数以及返回值,它们有时候也被称为 自动生命周期变量。而 堆区 就是我们用户手动管理的区域。下面是 C 语言申请堆区内存的例子:
//C
// 需要头文件 #include<stdlib.h>
int *arr = (int*)malloc(10*sizeof(int)); //申请了10个int大小的空间
free(arr); //记得释放这个空间,要不然会撑爆内存的(重启电脑除外) 是不是感觉这和数组很像?没错,数组是一坨连续的内存组成的结构,它的数组名就是指向这一串变量的第一个的指针,也就是数组名就是指向索引为 0 的那个元素的指针。
//C
//所以数组也可以写做:
int *array = {1,2,3,4,5};
//可以输出 *array,发现就是array[0]这一部分大家知道概念即可,因为更先进的语言已经不需要我们再这么深入底层研究了,有很多方便的方式来分配内存,比如 Go 语言中,使用 make:
//Go
slice := make([]int, 10)
for i := 0; i < 10; i++{
slice[i] = i;
}
fmt.Println(slice) // 会输出 0 1 2 3 4 ... 9有时候基本类型没有办法满足我们的使用需求,比如下面这个场景:统计全班的年龄 (char*)、身高 (int)、体重 (double) 等数据。
如果我们在 C 语言中还是每种类型的数据都定义一个数组,可能是这样的:
//C
char* names[] = {"程锦鑫", "孙源隆", "王俊杰"};
int height[] = {xxx, xxx, xxx};
double weight[] = {xx.xx, xx.xx, xx.xx};然后我们还需要记住每个数组中变量的顺序和对应其他数组的同一个人的数据,很麻烦。所以,我们可以考虑把数据放到一个整体中去。
我们通常称这种聚合的结构是结构体,C 语言中结构体可以如下方式定义:
//C
struct Student{
char* name;
int height;
double weight;
};
//结构体数组,也可以用指针表示
struct Student[] students = {
{"程锦鑫", xxx, xx.xx},
//...更多了例子
} 结构体中可以放入多种不同类型,一个结构体的大小也等于其中所有类型的总和。
另一方面,我们知道函数是一种类型,所以结构体中也可以放入函数,这也是面向对象的一个重要的实现方式。我们会在下面章节接触面向对象的内容。
我们继续探讨 C 语言中向函数传递参数的问题。现在可以解释之前 swap 函数的问题了,我们使用指针,是直接找到了变量 a,b 的地址,将存储在这个地址上的值进行了交换,而 a,b 指针的生命周期在函数 swap 之外,所以它们交换成功。同样的,使用数组也是一个道理。
//C
void swap(int *a,int *b){
int tmp = *a;
*a = *b;
*b = tmp;
}
int main(){
int a = 1,b = 2;
swap(&a, &b);
printf("a=%d,b=%d", a, b); //现在就是a=2 b=1了
} 我们有提到过函数存储在栈上,其函数名也是指向函数的指针,大家可以自行了解是什么作用,我们只写一个例子演示:函数指针两个主要用途:第一个是 回调函数,这个概念我们也会在实际开发中经常用到,会在 异步编程 的章节详细讲述。
//C
int add(int a, int b){
return a + b;
}
int substract(int a, int b){
return a - b;
}
//回调函数
//定义方式: [返回类型](*指针名)(形参列表)
//调用方式: 函数名(实参列表)
void operation(int a, int b, int (*func) (int a, int b)){
printf("result is %d", func(a, b));
}
int main(){
operation(10, 5, add);
operation(10, 5, substract);
return 0;
}第二种用途:通过函数指针也可以实现 结构体中的函数(一般称这种函数为方法),这是面向对象的重要内容:
//C
struct Student{
char* name;
int* scores;
//计算总分:假设scores是 {1,2,3,4,5}
int (*f)(int *arr);
}
int sum(int *arr){
int res = 0;
for(int* i=arr;i<=arr+5;i++){
res+=*i;
}
return res
}
int main(){
struct Student *s = (struct Student) malloc(sizeof(struct Student));
s->name = "函数指针";
s->scores = (int*) malloc(sizeof(int) * 5);
for(int i = 0; i <= 5; i++){
s->scores[i] = i;
}
s->f = sum;
printf("%d: ", s->f(s->scores));
} C/C++ 已经被白宫列为了危险的东西,那群老登现在都在鼓吹 rust。Linux 系统也委员会也因为是否使用 rust 开发内核处于几乎内战的状态了。说到 C/C++ 内存问题,99% 都是因为指针的破坏力太大了。我们举一个例子:
//C
int a = 1;
int *p = &a;
printf("p is %p, p+1 is %p", (void*) p, (void*) (p+1); // 加减法会将地址值加减一个此类型的大小WC,指针居然也能做加减运算,但如果你不小心运算到了某个没有存储数据的随机地址,然后你又去尝试取它的数据,便会触发一个叫脏内存的东西。顾名思义,这就是随机的数据,可能导致你的程序崩溃退出。
另一方面,如果你已经使用 free 手动释放了指针,指针将变为野指针,顾名思义这将指向不可访问/不可预测的区域,如果你不小心又访问或者释放了一次,寄寄。
上面就是野指针的危害,相对的,空指针就是指向没有存储数据的地址,即 0 地址处,称为 NULL 或者 nil, 这里是没有东西的。我们就不演示空指针和野指针了,大家可以自行了解。
Note
本章作者:wjj
难度:⭐⭐
涉及语言:Go
面向过程其实是最为实际的一种思考方式,就算是面向对象的方法也是含有面向过程的思想。可以说面向过程是一种基础的方法。它考虑的是实际地实现。一般的面向过程是从上往下步步求精,所以面向过程最重要的是模块化的思想方法。面向过程编程,最典型的一个编程语言就是 C 语言。
所有的编程语言都提供抽象机制。可以认为,人们能够解决的问题的复杂性直接取决于抽象的类型和质量。
------ 不知道谁说的
你可以将现实生活中的任何事物都看作是(抽象为)一个对象(Object),对象的特点是:拥有自身的属性行为能力。也就是说,对象拥有属性和方法。
属性是对象所拥有的一些数据,例如如果把班级抽象成一个对象的话,这个班级的专业,人数等等都是这个对象的属性,同时,每个对象都可以包含其他对象,例如,一个班级对象可以拥有许多学生对象,一个年级对象可以拥有许多班级对象。
方法是对象能够进行的操作,例如一个班级对象可以拥有班会,考试等方法。一般来说,某一特定类型的所有对象都可以调用同样的方法。例如,王俊杰和孙源隆都是属于挑战网部长类型的对象,他们都可以调用讲课方法,但是因为他们是不同的对象,所以调用讲课方法的结果可以不一样。
面向对象的三大特点是封装、继承、多态。封装将对象的属性和方法划分为公有和私有,保证了外部和内部的稳定和效率。继承简单地说就是一种层次模型,这种层次模型能够被重用。层次结构的上层具有通用性,但是下层结构则具有特殊性。在继承的过程中类则可以从最顶层的部分继承一些方法和变量。多态是指不同事物具有不同表现形式的能力。多态机制使具有不同内部结构的对象可以共享相同的外部接口,通过这种方式减少代码的复杂度。

函数式编程(Functional Programming,FP)是一种编程范式,它把计算过程视为数学上的函数运算,并将程序中的计算抽象为函数。与面向对象编程(OOP)不同,函数式编程强调“函数”的概念,注重纯函数、不可变数据和函数的组合。
在函数式编程中,函数是一等公民,这意味着一个函数,既可以作为其它函数的输入参数值,也可以从函数中返回值,被修改或者被分配给一个变量。λ 演算是这种范型最重要的基础,λ 演算的函数可以接受函数作为输入参数和输出返回值。这里使用 Go 语言演示:
//C
//作参数:
func add(a, b int) int{
return a + b
}
func operator(a, b int, f func(int, int) (int)){
f(a, b)
}
func main(){
operator(1, 2, add)
}
//作返回值:
func checkrole(level int){
return func(c *gin.Context){
loginLevel := getLoginStatus().Level()
if loginLevel < level{
c.Error(errors.New("您无权访问此接口"))
}
}
}上面的函数,将另一个函数作为返回值,就是函数式编程思想的体现
Note
本章作者:挑战以往资料 + syl
难度:⭐⭐⭐
涉及语言:API 规范
前排提醒,这种纯知识点类的,对于实际开发基本没有作用,地位就类似于理工科课本里面给你讲历史一样,属于自己看看就好的那种。所以要是觉得云里雾里的,也没什么大事。
计算机网络包括两个或更多个通过电缆(有线)或WiFi(无线)连接的计算机,用于传输、交换或共享数据及资源。可以使用硬件(例如,路由器、交换机、接入点和电缆)和软件(例如,操作系统或业务应用程序)来构建计算机网络。
通常按地理位置来定义计算机网络。例如,局域网(LAN)可连接特定物理空间(例如办公大楼)中的计算机,而广域网(WAN)可连接各大洲的计算机。互联网是最大的WAN,它连接了全球数十亿台计算机。
常见网络类型是:
• 局域网(LAN):LAN可在相对短的距离内连接计算机,以便它们可以共享数据、文件和资源。例如,LAN可以连接办公大楼、学校或医院中的所有计算机。通常,LAN由私人拥有和管理。
• 无线局域网(WLAN):WLAN类似于LAN,但以无线方式连接网络上的设备。
• 广域网(WAN):顾名思义,WAN可以连接一个广阔区域(例如跨地区或跨大洲)内的计算机。互联网是最大的WAN,它连接了全球数十亿台计算机。集体所有权模型或分布式所有权模型都是常见的WAN管理模型。
• 城域网(MAN):MAN通常比LAN大,但比WAN小。MAN通常由城市和政府单位拥有和管理。
• 个人区域网(PAN):一个PAN为一个人提供服务。例如,如果您同时拥有iPhone和Mac,那么您很有可能已经建立了一个PAN,可以在两个设备之间共享和同步内容(短信、电子邮件、照片等)。
• 校园网(CAN):CAN也可表示企业区域网。CAN比LAN大,但比WAN小。CAN可以为学院、大学和商业园区等场所提供服务。
• 虚拟专用网(VPN):VPN是两个网络终端之间安全的点到点连接。VPN建立了一个加密通道,该通道将保留黑客都无法访问的用户身份和访问凭证以及所传输的所有数据。
• IP地址:IP地址是为使用互联网协议进行通信的网络中连接的每个设备分配的唯一编号。每个IP地址都会标识设备的主机网络以及设备在主机网络上的位置。当一个设备向另一个设备发送数据时,数据包含一个"标头",其中包含发送设备的IP地址和目标设备的IP地址。
• 节点:节点是网络内可以接收、发送、创建或存储数据的连接点。每个节点都要求您提供某种形式的身份来接收访问权限,例如IP地址。节点的一些例子包括计算机、打印机、调制解调器、网桥和交换机。节点实质上是可以识别和处理信息并将信息传输到任何其他网络节点的任何网络设备。
• 路由器:路由器是用于在网络之间发送数据包中包含的信息的物理或虚拟设备。路由器会分析数据包中的数据,以确定将信息传输到最终目的地的最佳方式。路由器会转发数据包,直至其到达目标节点。
• 交换机:交换机是一种设备,它可以连接其他设备并管理网络内节点间通信以确保数据包到达最终目的地。路由器是在网络之间发送信息,而交换机是在单个网络中的节点之间发送信息。在讨论计算机网络时,"交换"是指在网络中的设备之间传输数据的方式。
• 端口:端口将标识网络设备之间的特定连接。每个端口均由一个编号标识。如果将IP地址比作酒店的地址,那么端口就是该酒店内的套房或房间号。计算机使用端口号确定哪个应用、服务或进程应接收特定报文。(扩展知识:端口转发,一个端口承担多个作用)
• 网络电缆类型:最常见的网络电缆类型包括以太网双绞线、同轴电缆和光纤。电缆类型的选择取决于网络的规模、网络元素的排列以及设备间的物理距离。
这些东西阅读了解即可,具体的 TCP/IP 协议内容很多,今后将会逐步学习
计算机网络使用电缆、光纤或无线信号来连接计算机、路由器和交换机等节点。利用这些连接,网络中的设备便可以进行通信并共享信息和资源。
网络需要遵循协议,而协议定义了发送和接收通信内容的方式。协议是规则的集合,在网络中要做到有条不紊地交换数据,就必须遵循一些事先约定好的规则。这些规则明确规定了所交换的数据的格式以及相关的同步问题。为进行网络中的数据交换而建立的规则、标准或约定称为网络协议(Network Protocol),它是控制两个(或多个)对等实体进行通信的规则的集合。设备可使用这些协议进行通信。例如,网络上的每个设备都会使用TCP协议或IP协议来进行通讯。
路由器是可使不同网络进行通信的虚拟或物理设备。路由器会分析信息,以确定数据到达最终目的地的最佳方法。交换机可连接设备并管理网络内的节点间通信,从而确保信息包通过网络到达最终目的地。
最顶层的是一些应用层协议,这些协议定义了一些用于通用应用的数据报结构,包括FTP及HTTP等。中间层是UDP协议和TCP协议,它们用于控制数据流的传输。UDP是一种不可靠的数据流传输协议,仅为网络层和应用层之间提供简单的接口。而TCP协议则具有高的可靠性,通过为数据报加入额外信息,并提供重发机制,它能够保证数据不丢包、没有冗余包以及保证数据包的顺序。对于一些需要高可靠性的应用,可以选择TCP协议;而相反,对于性能优先考虑的应用如流媒体等,则可以选择UDP协议。
最底层的是网际网络协定,是用于报文交换网络的一种面向数据的协议,这一协议定义了数据包在网际传送时的格式。目前使用最多的是IPv4版本,这一版本中用32位定义IP地址,尽管地址总数达到43亿,但是仍然不能满足现今全球网络飞速发展的需求,因此IPv6版本应运而生。在IPv6版本中,IP地址共有128位,“几乎可以为地球上每一粒沙子分配一个IPv6地址”。IPv6目前并没有普及,许多网际网络服务提供商并不支持IPv6协议的连接。但是,可以预见,将来在IPv6的帮助下,任何家用电器都有可能连入网际网络。
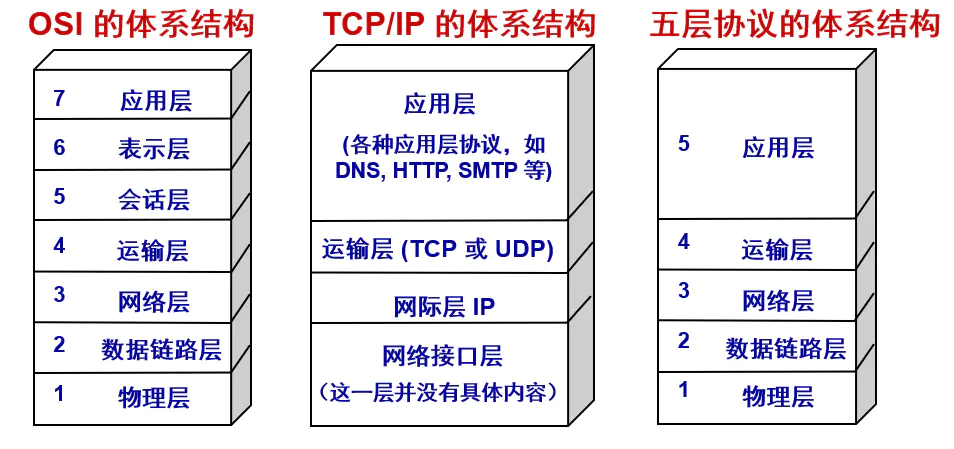
如果学习大学计算机课程的话,会接触到网络体系结构,也就是下图所示的
HTTP 协议的概念如下:
超文本传输协议(英语:HyperText Transfer Protocol,缩写:HTTP)是一种用于分布式、协作式和超媒体信息系统的应用层协议。HTTP是万维网的数据通信的基础。
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法。通过HTTP或者HTTPS协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI;URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何locate这个资源)来标识。URL/URI俗称网页地址,简称网址,是因特网上标准的资源的地址(Address),如同在网络上的门牌。)
HTTP是一个客户端(用户)和服务端(网站)之间请求和应答的标准,通常使用TCP协议。通过使用网页浏览器、网络爬虫或者其它的工具,客户端发起一个HTTP请求到服务器上指定端口(默认端口为80)。我们称这个客户端为用户代理程序(user agent,UA),你可以通过改变UA来伪装成不同的浏览器。
应答的服务器上存储着一些资源,比如HTML文件和图像。我们称这个应答服务器为源服务器(origin server)。而在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。
尽管TCP/IP协议是互联网上最流行的应用,但是在HTTP协议中并没有规定它必须使用或它支持的层。事实上HTTP可以在任何互联网协议或其他网络上实现。HTTP假定其下层协议提供可靠的传输。因此,任何能够提供这种保证的协议都可以被其使用,所以其在TCP/IP协议族使用TCP作为其传输层。
通常,由HTTP客户端发起一个请求,建立一个到服务器指定端口(默认是80端口)的TCP连接。HTTP服务器则在那个端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态,比如"HTTP/1.1 200 OK",以及返回的内容,如请求的文件、错误消息、或者其它信息。
HTTP 方法
这是 HTTP 协议中非常重要的一环,HTTP/1.1 一共定义了 8 种方法,我们这里只介绍常用的 5 种,其余的大家可以自行搜索了解。
GET
向指定的资源发出显式的请求。只应该在读取信息时使用 GET 方法,而不应将其滥用于做出其他操作的请求中,例如需要传输大量内容或更改数据操作。在浏览器内输入 URL 直接发出的请求默认就为 GET。若要在 GET 内加入请求参数,可在 URL 中附带请求参数。另外,接受 GET 请求的网址可能会被网络爬虫等随意访问。
HEAD
与 GET 方法一样,是向服务器发出指定资源的请求。只不过服务器将不传回资源的 body 部分。该请求可以获取网页中的元数据。它的好处是节省带宽。
POST
向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求本文中。这个请求可能会建立新的资源或修改现有资源,或二者皆有。每次提交,表单的数据被浏览器编码到 HTTP 请求的请求体(body)里。
PUT
向指定资源位置上传其最新内容。
DELETE
请求服务器删除 Request-URI 所标识的资源。
方法名称是 区分大小写 的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码 405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码 501(Not Implemented)。HTTP 服务器至少应该实现 GET 和 HEAD 方法,其他方法都是可选的。
另外的,我们的请求方法都有着更多不同的性质,诸如安全性、幂等性等,这些建议大家多多了解。
HTTP 状态码
我们有时候会遇到页面显示类似 404、503 等,这些都是常见的 HTTP 状态码。状态码的第一个数字代表当前响应的类型:
1xx 消息——请求已被服务器接收,继续处理
2xx 成功——请求已成功被服务器接收、理解、并接受
3xx 重定向——需要后续操作才能完成这一请求
4xx 请求错误——请求含有词法错误或者无法被执行
5xx 服务器错误——服务器在处理某个正确请求时发生错误
更多常见的 HTTP 状态码如下:
200 OK
请求已成功,请求所希望的响应头或数据体将随此响应返回。实际的响应将取决于所使用的请求方法。在GET请求中,响应将包含与请求的资源相对应的实体。在POST请求中,响应将包含描述或操作结果的实体。
301 Moved Permanently
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
302 Found
要求客户端执行临时重定向(原始描述短语为“Moved Temporarily”)。
400 Bad Request
由于明显的客户端错误,服务器不能或不会处理该请求。
403 Forbidden
服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。
404 Not Found
请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求。没有信息能够告诉用户这个状况到底是暂时的还是永久的。
405 Method Not Allowed
请求行中指定的请求方法不能被用于请求相应的资源。
406 Not Acceptable
请求的资源的内容特性无法满足请求头中的条件,因而无法生成响应实体,该请求不可接受。除非这是一个HEAD请求,否则该响应就应当返回一个包含可以让用户或者浏览器从中选择最合适的实体特性以及地址栏表的实体。
408 Request Timeout
请求超时。根据HTTP规范,客户端没有在服务器预备等待的时间内完成一个请求的发送,客户端可以随时再次提交这一请求而无需进行任何更改。
429 Too Many Requests
用户在给定的时间内发送了太多的请求。旨在用于网络限速。
500 Internal Server Error
通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息。
501 Not Implemented
服务器不支持当前请求所需要的某个功能。当服务器无法识别请求的方法,并且无法支持其对任何资源的请求。(例如,网络服务API的新功能)
502 Bad Gateway
作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应。
503 Service Unavailable
由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复。如果能够预计延迟时间,那么响应中可以包含一个Retry-After头用以标明这个延迟时间。如果没有给出这个Retry-After信息,那么客户端应当以处理500响应的方式处理它。
504 Gateway Timeout
作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。某些代理服务器在DNS查询超时时会返回400或者500错误。
虽然 RFC 2616 中已经推荐了描述状态的短语,例如 "200 OK","404 Not Found",但是 WEB 开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息
HTTP 请求
请求信息格式中需要包含:
请求行(例如 GET /images/logo.gif HTTP/1.1,表示从 /images 目录下请求 logo.gif)
请求头(例如 Accept-Language: en)
空行
其他消息体
来一个例子:
客户端请求:
GET / HTTP/1.1 (第一行指定方法、资源路径、协议版本)
Host: www.google.com (第二行是在1.1版里必须指定的一个参数,用于确定主机名称)
(……其他请求头,如Application:json)
(末尾有一个空行)
服务器应答:
HTTP/1.1 200 OK
Content-Length: 3059
Server: GWS/2.0
Date: Sat, 11 Jan 2077 02:44:04 GMT
Content-Type: text/html
Cache-control: private
Connection: keep-alive
(紧跟着一个空行,并且由HTML格式的文本组成了Google的主页)
网址是什么
统一资源定位符(URL)的标准格式如下: [协议类型]://服务器地址:端口号/资源层级文件路径文件名?查询#片段 ID 统一资源定位符的完整格式如下: [协议类型]://访问资源需要的凭证信息@服务器地址:端口号/资源层级 UNIX 文件路径文件名?查询#片段 ID 其中 [访问凭证信息]、[端口号]、[查询]、[片段 ID] 都属于选填项。
这些名词解释是这样的:
-
传送协议,如 http 或 https
-
层级 URL 标记符号(为 “//”,固定不变)
-
访问资源需要的凭证信息(可省略)
-
服务器(通常为域名,有时为 IP 地址)
-
端口号(以数字方式表示,若为预设值可省略)
-
路径(以 “/” 区别路径中的每一个目录名称)
-
查询(GET 模式的表单参数,以 “?” 字元为起点,每个参数以 “&” 隔开,再以 “=” 分开参数名称与资料,通常以 UTF-8 的 URL 编码,避开文字编码冲突的问题)
-
片段 ID(以 “#” 为起点,标记了网页上的哪一部分)
DNS 负责域名解析为 IP,具体方式可以自行了解。
如何设计和进行交互
一个重要的概念是 API: 应用程序接口(英语:application programming interface),缩写为 API,是一种计算接口,它定义多个软件之间的交互,以及可以进行的调用(call)或请求(request)的种类,如何进行调用或发出请求,应使用的数据格式,应遵循的惯例等。它还可以提供扩展机制,以便用户可以通过各种方式对现有功能进行不同程度的扩展。一个 API 可以是完全定制的,针对某个组件的,也可以是基于行业标准设计的以确保互操作性。通过隐藏无关信息,API 实现了模块化编程,从而允许用户实现独立地使用接口。
应用程序接口有诸多不同设计。用于快速执行的接口通常包括 函数名、常量、变量与其他数据结构。在向他人提供一个 API 时,你需要显式地提供以上信息。下面是 cppreference 上的一个 API:

我们用到的 API 架构是 RESTful API, 后续会逐步教学,现在可以作了解
RESTful API,Web 服务必须遵守以下六个 REST 架构约束:
客户端 - 服务端(Client-Server):RESTful 专注于客户端和服务端的分离,服务端独立可更好服务于前端、安卓、IOS 等客户端设备。
无状态(Stateless):服务端不保存客户端状态,客户端保存状态信息每次请求携带状态信息。
可缓存性(Cacheability):服务端需回复是否可以缓存以让客户端甄别是否缓存提高效率。
统一接口(Uniform Interface):通过一定原则设计接口降低耦合,简化系统架构,这是 RESTful 设计的基本出发点。
分层系统(Layered System):客户端无法直接知道连接的到终端还是中间设备,分层允许你灵活地部署服务端项目。
按需编码(Code-On-Demand,可选):按需编码允许我们灵活地发送一些可执行代码给客户端,例如 JavaScript 代码。 我们在设计 API 时 URL 的 path 是需要认真考虑的,而 RESTful 对 path 的设计做了一些规范,
通常一个RESTful API的path组成如下:
/{version}/{resources}/{resource_id}
version:API版本号,有些版本号放置在头信息中也可以,通过控制版本号有利于应用迭代。
resources:资源,RESTful API推荐用小写英文单词的复数形式。
resource_id:资源的id,访问或操作该资源。
当然,有时候可能资源级别较大,其下还可细分很多子资源也可以灵活设计URL的path,例如:
/{version}/{resources}/{resource_id}/{subresources}/{subresource_id}
此外,有时可能增删改查无法满足业务要求,可以在URL末尾加上action,例如
/{version}/{resources}/{resource_id}/action
其中action就是对资源的操作。
从大体样式了解 URL 路径组成之后,对于 RESTful API 的 URL 具体设计的规范如下:
1. 不用大写字母,所有单词使用英文且小写。
2. 连字符用中杠 "-" 而不用下杠 "_"。
3. 正确使用 "/" 表示层级关系, URL 的层级不要过深,并且越靠前的层级应该相对越稳定。
4. 结尾不要包含正斜杠分隔符 "/"。
5. URL 中不出现动词,用请求方式表示动作。
6. 资源表示用复数不要用单数。
7. 不要使用文件扩展名。
![]() 举个例子,比如我们要抽取一道题目,可以这样设计 URL:
举个例子,比如我们要抽取一道题目,可以这样设计 URL:
http://api.example.com/v1/draw
Note
本章作者:syl
难度:⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐(手动表情:流汗黄豆
涉及语言:C/C++,Go
本章中有很多重要的概念,大家需要多琢磨琢磨,因为这一块很重要,而且概念性很强。
就像我们上课一样排好了课表,写好程序后程序运行也是有流程的,对应的课表就是你写在代码里的顺序流程。比如在 C++ 中:
// C++
int add(int a, int b){
return a + b;
}
int substract(int a, int b){
return a - b;
}
int main(){
add(1, 2);
substract(4, 3);
}我们这里先执行了 add, 后执行 subtract,每一个函数都需要时间来执行,当然可以观测函数运行的时间,不同语言中关键字不同罢了,在 C++ 中可以这样做:
// C++
int main(){
//时间戳是unix从1970年记录到现在的
auto t0 = std::chrono::steady_clock::now(); //记录一个流程开始时间戳
for(int i=0; i<10000000; i++); // 10,000,000次自增操作
auto t1 = std::chrono::steady_clock::now(); //记录一个流程结束时间戳
auto dt = t1 - t0; //减掉就是中间流程的时间了
int64_t ms = std::chrono::duration_cast<std::chrono::milliseconds>(dt).count; //转换成int类型的数据
std::cout<<"time elapsed "<<ms<<"ms"<<std::endl; //比如我执行完输出了13ms
return 0;
}我们可以控制一个流程的执行时间,C++ 可以使用 sleep_for(或者 sleep_until)关键字(不同语言可能关键字不同),将流程睡眠一会。
// C++
std::this_thread::sleep_for(std::chrono::milliseconds(400)); //睡眠400ms
auto t = std::chrono::steady_clock::now() + std::chrono::milliseconds(400);
std::this_thread::sleep_until(t); //睡眠到从现在起过400ms的时间点念个经先~
进程(Process/有些地方也称 Routines):
是操作系统中的一个基本概念,它包含着一个运行程序所需要的资源,或者说是程序运行的最小单元。一个正在运行的应用程序在操作系统中被视为一个进程,进程可以包括一个或多个线程。
线程是操作系统分配处理器时间的基本单元,在进程中可以有多个线程同时执行代码。进程之间是相对独立的,一个进程无法访问另一个进程的数据(除非利用分布式计算方式),一个进程运行的失败也不会影响其他进程的运行,系统就是利用进程把工作划分为多个独立的区域的。进程可以理解为一个程序的基本边界。是应用程序的一个运行例程,是应用程序的一次动态执行过程。
线程(Thread):
是进程中的基本执行单元,是操作系统分配 CPU 时间的基本单位,一个进程可以包含若干个线程,在进程入口执行的第一个线程被视为这个进程的主线程。线程主要是由 CPU 寄存器、调用栈和线程本地存储器(Thread Local Storage,TLS)组成的。CPU 寄存器主要记录当前所执行线程的状态,调用栈主要用于维护线程所调用到的内存与数据,TLS 主要用于存放线程的状态信息。
进程和线程的区别
进程和线程的主要差别在于它们是不同的操作系统资源管理方式。进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响,而线程只是一个进程中的不同执行路径。
从属关系:进程 > 线程。一个进程可以拥有多个线程。 每个线程共享同样的内存空间,开销比较小。 每个进程拥有独立的内存空间,因此开销更大。 对于高性能并行计算,更好的是多线程。
线程有自己的堆栈和局部变量(进阶篇 1 阐述了这些概念),但线程之间没有单独的地址空间,一个线程死掉就等于整个进程死掉,所以多进程的程序要比多线程的程序健壮,但在进程切换时,耗费资源较大,效率要差一些。但对于一些要求同时进行并且又要共享某些变量的并发操作(我们一会会详细阐述这个概念),只能用线程,不能用进程。
- 简而言之,一个程序至少有一个进程,一个进程至少有一个线程。
- 线程的划分尺度小于进程,使得多线程程序的并发性高。
- 另外,进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
- 线程在执行过程中与进程还是有区别的。每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口。但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
- 从逻辑角度来看,多线程的意义在于一个应用程序中,有多个执行部分可以同时执行。但操作系统并没有将多个线程看做多个独立的应用,来实现进程的调度和管理以及资源分配。这就是进程和线程的重要区别。
总之就是,我们平常搞项目的,除非是搞大型项目,比如你自己写个桌面环境,才会用到多个完全分离但是互相依赖的部分,而且每一部分都也是十分庞大,这时候需要使用进程。其他的情况下,如果只是需要在主流程进行过程中突然处理一个大型计算,或者大量交互,就是使用的多线程以及下面的协程。
多线程能做什么:无阻塞多任务!!!
我们希望一边下载/观看东西一边随便输入点内容来评论,常规操作可能是这样的(使用 C/C++ 演示):
// C++
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
void download(std::string file){
for(int i = 0; i < 100000; i++){
std::cout << "downloading!" << file << "(" << i * 10 << "%)..." << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Complete: " << file << '\n';
}
void interact(){
std::string name;
std::cin >> name;
std::cout << "Welcome: " << name << '\n';
}
int main(){
download("王俊杰的黑历史.mp4");
interact();
return 0;
}执行效果如下,我们可以在 download 的同时随意输入东西,但是输出却不会执行,因为 main 被阻塞了,只有 download 结束才会执行 interact,输入完之后并不能立刻得到反馈:

// C/C++
#include <iostream>
#include <string>
#include <thread>
#include <chrono>
void download(const std::string& file) {
for (int i = 0; i < 10; i++) {
std::cout << "downloading! " << file << " (" << i * 10 << "%)..." << "\n";
std::this_thread::sleep_for(std::chrono::milliseconds(400));
}
std::cout << "Complete: " << file << '\n';
}
void interact() {
std::string name;
std::cin >> name;
std::cout << "Hi, " << name << '\n';
}
int main() {
std::thread download_file([&]{
download("王俊杰的黑历史.zip");
});
interact();
//join是为了等待这个download线程结束,再退出main
download_file.join();
return 0;
}现在就非常 nice 了,可以一边下载/观看王俊杰的黑历史一边发表评论了~~(bushi~~

我们知道线程执行完就会销毁,有时候需要自己管理什么时候销毁,请大家自行查阅分离线程、线程池的概念。当然你要是用的是有GC的语言,也希望了解一下。
背景:在传统的 J2EE 系统中都是基于每个请求占用一个线程去完成完整的业务逻辑(包括事务)。所以系统的吞吐能力取决于每个线程的操作耗时。如果遇到很耗时的 I/O(input 和 output)行为,则整个系统的吞吐立刻下降,因为这个时候线程一直处于阻塞状态,如果线程很多的时候,会存在很多线程处于空闲状态(等待该线程执行完才能执行),造成了资源应用不彻底.
而协程的目的就是当出现长时间的 I/O 操作时,通过让出目前的协程调度,执行下一个任务的方式,来消除 ContextSwitch 上的开销。
协程(coroutines),由字面意思就知道是和进程(Process/Routines)或者函数调用(Subroutines)对应的东西。协程其实是分割进程,但是分割的同时保留了之前处理过的信息,所以可以用来组件之间的协作工作。协程的初始处就是第一个的入口点。通过 yield 返回一部分结果值以及执行到这个时刻的协程的状态,作为下次进入这个协程的入口点。形象的演示,比如这张图(来自 b 站 up 百草园),容易看出函数调用和协程的关系。
其实协程就是把本来异步的事,或者说不同的事情,给同步了,就类似于你把好几种彩线拧到了一起,但是呢,彼此已经混合了,不是最开始那种独立顺序了。然后你还能自己控制这混起来的部分罢了。

举个例子,就像你看一道数学题,有思路的时候去写,卡住了然后回去看题,有思路了继续写,这样循环下去。如果不出意外的话,你应该就是在卡住的地方去看了题,看的就是上次没看明白的地方,然后返回上次卡住的地方继续写。
// 伪代码演示:
var q := new queue //新建队列
coroutine produce //生产者
loop
while q is not full //队列不满时就添加新物品进去
create some new items
add the items to q
yield to consume //中断生产者,开始消费者的行为
coroutine consume //消费者
loop
while q is not empty //队列不空时拿到物品开始消耗
remove some items from q
use the items
yield to produce //中断消费者,开始生产者的行为
call produce //开工了
队列用来存放产品的空间有限,同时制约生产者和消费者:为了提高效率,生产者协程要在一次执行中尽量向队列多增加产品,然后再放弃控制使得消费者协程开始运行;同样消费者协程也要在一次执行中尽量从队列多取出产品,从而倒出更多的存放产品空间,然后再放弃控制使得生产者协程开始运行。尽管这个例子常用来介绍 多线程,实际上简单明了的使用协程的 yield 即可实现这种协作关系。
- 线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率。
- 线程的默认 Stack 大小是 1M,而协程更轻量,接近 1K。因此可以在相同的内存中开启更多的协程。
- 协程之间由于在同一个线程上,因此可以避免竞争关系而使用锁。通常使用一个叫通道的东西用来通信,根据通信共享协程之间的信息,共享数据等。相反的,线程就需要通过共享数据来彼此实现通信。
- 被阻塞情况下如果仍然需要执行多个任务,就不适合线程了,应该使用协程。
当出现 IO 阻塞的时候,由协程的调度器进行调度,通过将数据流立刻 yield 掉(主动让出),并且记录当前栈上的数据,阻塞完后立刻再通过线程恢复栈,并把阻塞的结果放到这个线程上去跑,这样看上去好像跟写同步代码没有任何差别,这整个流程可以称为 coroutine,而跑在由 coroutine 负责调度的线程称为 Fiber。比如 Golang 里的 go 关键字其实就是负责开启一个 Fiber,让 func 逻辑跑在上面。
由于协程的暂停完全由程序控制,发生在用户态上;而线程的阻塞状态是由操作系统内核来进行切换,发生在内核态上。 因此,协程的开销远远小于线程的开销,也就没有了 ContextSwitch 上的开销。
回到刚才的场景,能否使用协程来做呢
这里使用 Go 语言举例子,毕竟 C++ 开协程是一项高级技术,有点难度,举例子的话没有那么清晰。
// Go
package main
import (
"fmt"
"time"
)
func download(file string) {
for i := 0; i < 10; i++ {
fmt.Println("Downloading", file, "(", i*10, "%)")
time.Sleep(1 * time.Second)
}
fmt.Println("Downloaded", file)
}
func interact() {
var name string
fmt.Println("What's your name?")
fmt.Scanln(&name)
fmt.Println("Hello", name)
}
func main() {
//go开协程很方便,go 函数名(变量) 就可以了
go download("王俊杰的黑历史.mp4")
interact()
//这里阻塞一下main,等download执行完
select {}
}继续迫害王俊杰结果如下:

阻塞和非阻塞是进程在访问数据的时候,数据是否准备就绪的一种处理方式。当数据没有准备的时候,阻塞需要等待调用结果返回之前,进程会被挂起,函数只有在得到结果之后才会返回。非阻塞和阻塞的概念相对,指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回。
同步指的是在发出一个功能调用时,在没有得到结果之前,该调用就不返回。也就是必须一件一件事做, 等前一件做完了才能做下一件事。异步的概念和同步相对,当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
举个例子来说,对于我们经常使用 B/S 架构来说,同步和异步指的是从客户端发起访问数据的请求,阻塞和非阻塞指的是服务端进程访问数据,进程是否需要等待。这两者存在本质的区别,它们的修饰对象是不同的。
阻塞和非阻塞是指进程访问的数据如果尚未就绪,进程是否需要等待,简单说这相当于函数内部的实现区别,也就是未就绪时是直接返回还是等待就绪。
同步和异步是指访问数据的机制,同步一般指主动请求并等待 I/O 操作完毕的方式,当数据就绪后在读写的时候必须阻塞,异步则指主动请求数据后便可以继续处理其它任务,随后等待 I/O,操作完毕的通知,这可以使进程在数据读写时也不阻塞。
妈妈让我去厨房烧一锅水,准备下饺子。
阻塞:水只要没烧开,我就干瞪眼看着这个锅,沧海桑田,日新月异,我自岿然不动,厨房就是我的家,烧水是我的宿命;
非阻塞:我先去我屋子里打把王者,但是每过一分钟,我都要去厨房瞅一眼,生怕时间长了,水烧干了就坏了,这样导致我游戏也心思打,果不然,又掉段了;
同步:不管是每分钟过来看一眼锅,还是寸步不离的一直看着锅,只要我不去看,我就不知道水烧好没有,浪费时间啊,一寸光阴一寸金;
异步:我在淘宝买了一个电水壶,只要水开了,它就发出响声,嗨呀,可以安心打王者喽,打完可以吃饺子喽;
总结:
阻塞/非阻塞:我在等你干活的时候我在干啥?
阻塞:啥也不干,死等;
非阻塞:可以干别的,但也要时不时问问你的进度;
同步/异步:你干完了,怎么让我知道呢?
同步:我只要不问,你就不告诉我;
异步:你干完了,直接喊我过来就行;
- 使用多线程,开始多个任务
- 使用协程 (这两个直接看上面的代码例子就行了)
- 多线程 + promise + future 实现线程间传递结果
- 函数式编程范式上的异步概念:回调函数(我们之前将函数指针时候提到过这个概念),演示如下:
其实就是将需求拆成了不同的函数来实现,在函数式编程范式上这称之为反应式编程。注意一般情况下回调不止一个,可以视运行到回调的时候就是切换到了那个函数去执行,然后在切回原函数。以此类推。
// 回调函数异步 C++实现
#include<iostream>
#include<functional>
// if callback not only, you can use std::vector<return_type(param_type)> callback_list
// or, use ... syntax in template
void download(std::string file, std::function<void(std::string)> callback){
//forward code ...
std::cout << "Downloading file: " << file << std::endl;
/*here, you can regard as stopping [download] function, then jumping to callback function.*/
callback("Downloaded file: " + file);
//well, return to [download] function, then continue run
//else code ...
}
int main(){
download("tutorial.txt", [](std::string result){
std::cout << result << std::endl;
});
return 0;
}// 回调函数异步 Go实现
package main
import (
"fmt"
"time"
)
func download(file string, callback func()) {
for i := 0; i < 10; i++ {
fmt.Println("Downloading", file, "(", i*10, "%)")
time.Sleep(1 * time.Second)
}
fmt.Println("Downloaded", file)
callback()
}
func main() {
download("王俊杰的黑历史.mp4", func() {
fmt.Println("Download complete callback")
})
}以网络 IO 为例,其本质是 Socket 的读取,Socket 在 Linux 系统被抽象为流,IO 可以理解为对流的操作。Linux 标准文件访问方式如下:

当发起一个 read 操作的时候,会经历 2 个阶段:
- 等待数据准备;
- 将数据从内核拷贝到进程中;
对于 socket 流也会经历两个阶段:
- 将磁盘或者其他设备到达以后的信息,拷贝到内核的缓存区中;
- 将内核的缓存区的数据复制到应用进程缓存中;
网络应用需要处理的无非就是两大类问题,网络 IO,数据计算。相对于后者,网络 IO 的延迟,给应用带来的性能瓶颈大于后者,接下来我们介绍下 IO 模型。
同步阻塞 IO 模型是最常用的一个模型,也是最简单的模型。在 Linux 中,默认情况下所有的 socket 都是 blocking。阻塞就是进程休息, CPU 处理其它进程去了。
用户空间的应用程序执行一个系统调用(recvform),这会导致应用程序阻塞,直到数据准备好,并且将数据从内核复制到用户进程,最后进程再处理数据,在等待数据到处理数据的两个阶段,整个进程都被阻塞。不能处理别的网络 IO。
同步非阻塞就是采用轮询的方式,定时去查看数据是否准备完成。在这种模型中,进程是以非阻塞的形式打开的。IO 操作不会立即完成,如果该缓冲区没有数据的话,就会直接返回一个 EWOULDBLOCK 错误,不会让应用一直等待中。
非阻塞 IO 也会进行 recvform 系统调用,检查数据是否准备好,与阻塞 IO 不一样,非阻塞将大的整片时间的阻塞分成 N 多的小的阻塞, 所以进程不断地有机会被 CPU 访问。
同步非阻塞方式需要不断主动轮询,轮询占据了很大一部分过程,轮询会消耗大量的 CPU 时间,当并发情况下服务器很可能一瞬间会收到几十上百万的请求,这种情况下同步非阻塞 IO 需要创建几十上百万的线程去读取数据,同时又因为应用线程是不知道什么时候会有数据读取,为了保证消息能及时读取到,那么这些线程自己必须不断的向内核发送 recvfrom 请求来读取数据。这么多的线程不断调用 recvfrom 请求数据,明细是对线程资源的浪费。
于是有人就想到了由一个线程循环查询多个任务的完成状态(fd 文件描述符),只要有任何一个任务完成,就去处理它。这样就可以只需要一个或几个线程就可以完成数据状态询问的操作,当有数据准备就绪之后再分配对应的线程去读取数据,这么做就可以节省出大量的线程资源出来,这个就是 IO 多路复用。
IO 多路复用解决了一个线程或者多个线程可以监控多个文件描述符的问题,但是 select 是采用轮询的方式来监控多个文件描述符的,通过不断的轮询文件描述符的可读状态来知道是否有可读的数据,这样无脑的轮询就显得有点浪费,因为大部分情况下的轮询都是无效的,于是乎有人就想,能不能不要总是去轮询数据是否准备就绪,能不能发出请求后,等数据准备好了在通知我,所以这样就出现了信号驱动 IO。
信号驱动 IO 不是用循环请求询问的方式去监控数据就绪状态,而是在调用 sigaction 时候建立一个 SIGIO 的信号联系,当内核数据准备好之后再通过 SIGIO 信号,通知线程数据准备好后的可读状态,当线程收到可读状态的信号后,此时再向内核发起 recvfrom 读取数据的请求。因为信号驱动 IO 的模型下,应用线程在发出信号监控后即可返回,不会阻塞,所以这样的方式下,一个应用线程也可以同时监控多个文件描述符。
不管是 IO 多路复用还是信号驱动,我们要读取数据的时候,总是要发起两阶段的请求,第一次发送 select 请求,询问数据状态是否准备好,第二次发送 recevform 请求读取数据。这个时候我们会有一个疑问,为什么在读数据之前总要有个数据就绪的状态,可不可以应用进程只需要向内核发送一个 read 请求,告诉内核要读取数据后,就立即返回。当内核数据准备就绪,内核会主动把数据从内核复制到用户空间,等所有操作都完成之后,内核会发起一个通知告诉应用,所以这样就出现了异步非阻塞 IO 模型。
异步非阻塞 IO 模型应用进程发起 aio_read 操作之后,立刻就可以开始去做其它的事。后续的操作有内核接管,当内核收到一个 asynchronous read 之后,它会立刻返回,不会对用户进程产生任何 block。然后,内核会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成以后,内核会给用户进程发送一个 signal 或执行一个基于线程的回调函数来完成这次 IO 处理过程。
并发(Concurrency),在操作系统中,是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行。就想前面提到的操作系统的时间片分时调度。打游戏和听音乐两件事情在同一个时间段内都是在同一台电脑上完成了从开始到结束的动作。那么,就可以说听音乐和打游戏是并发的。
并行(Parallelism),当系统有一个以上 CPU 时,当一个 CPU 执行一个进程时,另一个 CPU 可以执行另一个进程,两个进程互不抢占 CPU 资源,可以同时进行,这种方式我们称之为并行(Parallelism)。这里面有一个很重要的点,那就是系统要有多个 CPU 才会出现并行。在有多个 CPU 的情况下,才会出现真正意义上的『同时进行』。换言之,对于GPU这种原生就是多核结构的,并行才是最好的选择。

并发,指的是多个事情,在同一时间段内同时发生了。 并行,指的是多个事情,在同一时间点上同时发生了。
并发的多个任务之间是互相抢占资源的。 并行的多个任务之间是不互相抢占资源的、
只有在多 CPU 的情况中,才会发生并行。否则,看似同时发生的事情,其实都是并发执行的。

一般情况下:
协程 -> 并发,协程适合用于阻塞、多任务场景,例如网络交互里面,而且不会消耗太多系统资源,也不会互相抢占进程。并发适合放到系统层面。
多线程 -> 并行,多线程适合于多核 CPU/GPU、非阻塞、多任务场景。例如模型渲染、服务器架构。并行往往能够最大限度利用 CPU/GPU 资源(互相不冲突前提下),适合游戏引擎和服务器这种超级高性能的场景。(比如虚幻引擎就是 C++ 的重量级产物)。并行就适合高性能场景。
当然使用 promise + future 技术结合多线程,也可以实现并发。但是本质上线程之间还是在抢 CPU, 而协程是在分割进程资源的。所以使用什么技术需要看业务场景。也不要说什么协程轻所以就一定比线程好,这其实是一种偏见。
我们后续一般并发编程场景较多,这一块也是 Go 语言的优势。有条件和感兴趣的读者可以自行了解这一块的内容。
Note
本章作者:wjj + cgy
难度:⭐⭐
涉及语言:shell
在介绍 git 之前,我们不妨先从 代码托管平台 开始说起。世界上最大最热门的代码托管平台,当然要数 Github,你可以从上面下载项目源代码、一些课程资料等等等等。国内也有类似的平台比如 Gitee (码云,全是广告),Gitcode('自主研发'的 sb 玩意) 等。
![]() 你可以为自己注册
你可以为自己注册 Github 账号,并通过平台的学生认证,然后你就可以免费使用一些付费软件或者网站了,比如 jetbrains 系列,overleaf。
想要在这些平台上下载资源,我们就需要使用到 git 工具。事实上,git 是一个版本控制工具,概括起来,就是实现开发者本地仓库与远程仓库之间的文件互传等操作。你可以在 这个网址 来下载 git,然后按照下面推荐的流程进行安装(仅以 windows 为例)



关于 git 的使用教学,我们在这里只举几个简单的例子,深入的学习可以参考 推荐文档 来进行学习,当然,网上相关的教程也是很多的。
当你想要创建一个新项目的时候,在 powershell 中按照如下流程:
#shell
cd <你的项目文件夹目录>
git init
git config user.name <你的用户名>
git config user.email <你的邮箱>
git remote add <你的仓库url>.git
// 然后你对你的项目进行了更新,想要提交到仓库
git add ./
git commit -m "<你的提交信息>"
git push <remote name> <分支>当你想要下载某个仓库的时候
#shell
git clone <仓库url>.git![]() 文档看得太累了怎么办,还是打会儿 游戏 吧,一个挺有意思的 git 学习小游戏。
文档看得太累了怎么办,还是打会儿 游戏 吧,一个挺有意思的 git 学习小游戏。
apifox 是一个国内开发的免费的接口调试工具,非常适合个人和团体使用。前后端都可以使用它来检查接口是否能正常运行,处理返回值。在项目中开发过程中,合适的接口调试工具会让开发轻松很多,类似的工具还有 postman,swagger 等等。你可以在 apifox 的官网 来获取
apifox 提供了一个示例项目用于学习,同时你也可以参阅 官方文档 获取帮助,他们甚至提供了视频
Navicat 是一个可以图形化操作 MySQL 的工具,在命令行操作数据库毕竟是一件比较费眼睛的事情,图形化的界面会方便很多。我们在后端的开发和部署时会频繁地用到它。此外 Navicat 支持操作多种数据库,比如 MongoDB,SQL Server,Redis 等等。这样强大的工具是需要付费的,所以我们也推荐一些其他的工具,如 DbServer,它提供了免费的社区版。
你可以在 官网 来下载 Navicat。
在操纵 MySQL 的时候,首先你需要和你的 MySQL 建立连接,如图所示:请忽略掉我已经建立的连接

然后你可以在一个连接中建立数据库,如图所示。对于一个独立的项目来说,建立独立的数据库显然是很有必要的

如果你要使用 MySQL 来进行一些操作,在上方菜单中点击查询,然后新建查询,就可以了,如图所示

具体的使用方法,可以参考 官方文档 获取帮助。
GNU/Linux 是对一系列基于 Linux 内核和 GNU 组件的发行版的统称,一般称作 Linux 即可。现今大多数服务器都运行着免费、稳定的 Linux 操作系统,而且对于开发者而言,Linux 下的工具链往往更为完整,开发环境的配置与 Windows 相比也简单太多。Linux 操作多数基于命令,即你在终端中输入命令,操作系统便能精准地明白你的意思,然后执行你交代的任务。这里只简要介绍一些入门的操作,更深入的了解可参考中科大 Linux 101。有些命令不知道是用来干嘛的的不要紧,后续接触的多了就能理解了。 这个部分简单介绍常用指令,更多的使用和配置在本文档末尾的linux部分。
【win用户简单上手:Windows 可以考虑 WSL】
搜索栏中搜索“启用或关闭 Windows 功能”,打开“适用于 Linux 的 Windows 子系统"和"Hyper-V",重启后在 powershell 中运行命令
wsl --install # 安装 wsl 的命令,默认会安装 Ubuntu,对新手友好如果连接不上服务器可在 Microsoft Store 中搜索 Ubuntu 安装。
安装好后可在 Powershell 中运行命令 wsl 或开始菜单中打开应用 Ubuntu,即进入 Linux 命令行(wsl 默认不包含图形界面)。
【常用操作】
- 路径与导航
pwd # print working directory,会打印出你当前所处位置
ls # 列出当前位置的文件
cd .. # change directory 改变当前所处位置
mkdir proj # 新建目录(文件夹)- 文件与查看
touch README.md # 新建一个名为 README.md 的文件,若存在则只 touch 它一下(修改时间更新内容不变)
cp -r src dst # cp 表示 copy, -r 表示递归(也会复制子目录),复制 src 目录到 dst 目录
mv object destination # move 移动文件/目录
rm -r danger # remove,-r 同上表示递归,小心使用,回车前看清路径,删除后很难恢复
cat file | less # cat 会输出文件所有内容,less 接收这些内容并允许用户翻页查看- 压缩与解压
# c-compress x-extract
tar -czvf archive.tar.gz dir/ # 将目录压缩为 tar.gz(常用)
tar -xzvf archive.tar.gz # 解压 tar.gz 到当前目录
tar -xzvf archive.tar.gz -C target/ # 解压到指定目录
tar -cjvf archive.tar.bz2 dir/ # 使用 bzip2 压缩
tar -xjvf archive.tar.bz2 # 解压 tar.bz2
tar -cJvf archive.tar.xz dir/ # 使用 xz 压缩
tar -xJvf archive.tar.xz # 解压 tar.xz
zip -r archive.zip dir/ # 压缩为 zip(跨平台常见)
unzip archive.zip -d target/ # 解压到指定目录
gzip -k file # 单个文件 → file.gz(-k 保留原文件)
gunzip file.gz # 解压 .gz- 搜索与定位
grep -Rni "TODO" . # 代码里找关键字
find . -name "*.go" # 按名字找文件- 权限与 sudo
ls -l # 列出的同时显示权限(rwx read write execute)
chmod +x run.sh # change mode,x 表示 execute,给 run.sh 添加可执行权限
sudo <命令> # 临时以管理员身份执行某命令- 包管理(Ubuntu/Debian)
sudo apt search docker # 查找某一软件包
sudo apt install docker.io # 安装指定软件包
sudo apt remove docker.io # 删除指定软件包
sudo apt upgrade # 更新所有软件包- 进程与网络
ps aux | grep myapp # 找进程,grep 接收 ps 的输出结果并筛选出含 "myapp" 的信息
kill 12345 # 结束(杀死)进程
curl https://example.com # 获取一个网站的信息,类似于你用浏览器访问该网站的过程- 编辑器怎么选
- nano:命令
nano <filename>即可开始编辑,底部有命令提示 - vim:学习曲线陡峭,基本使用:命令
vi <filename>或vim <filename>打开文件,打开时会处于 NORMAL 模式,i进入 INSERT 模式来编辑;Esc退出 INSERT 模式,回到 NORMAL 模式,:wq保存退出 - VS Code:有人称其为宇宙第一编辑器,功能强大且易用,有友好的图形化界面
- nano:命令
Note
本章作者:wjj + syl
难度:⭐⭐⭐
涉及语言:shell
html,css,js 三件套,使用它们可以设计网页界面、交互逻辑,以及向后端发数据。html 和 css 都有着简单的语法,容易上手进行开发。
html 也很容易嵌入到其他的一些标记语言中,比如你正在看的这篇文档,是使用 markdown 编写的,就支持内嵌的 html 语句。
css,中文名叫层叠样式表,可以修改 html 中元素的样式,提高代码的可读性和可维护性。
快速开始编写一个网页页面很简单,在 vscode 中安装好相关插件之后,在空的 .html 文件中输入 !,然后代码提示的第一个就会为你自动生成一个 html 模板。
具体的三件套教程可参考 菜鸟教程 和 w3school,里面有很详细的讲解和示例。

vue.js Vue.js 是一套用于构建用户界面的渐进式框架。它与其他大型框架不同,被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,易于上手,且便于与第三方库或既有项目整合。当与现代化的工具链以及各种支持类库结合使用时,Vue 也完全能够为复杂的单页应用提供驱动。
Vue.js 还有一个十分强大的组件库,element plus,它是基于 vue 开发的一套 UI 组件库,提供丰富的网页开发组件,可用快速开发网站,降低前端开发成本。
如果你对前端开发有浓厚的兴趣,我们也推荐你更加广泛地学习,这里我们列举一些例子:
后端将使用 go 语言进行开发,它是由谷歌推出的新兴的开发语言,在 2024 年 8 月的语言流行度排名中,位列第 9。go 语言是一种强类型语言,其运行速度接近 C 语言,同时又具有简单的语法,易于上手。其最大特点莫过于提供了一种简洁且高效的方式来处理并发事务,这使得它非常适合用来开发一些有高并发场景的服务,比如 Web 后端。

![]() 推荐阅读:Go 语言中不可不知的语法糖 这篇文章提到了很多
推荐阅读:Go 语言中不可不知的语法糖 这篇文章提到了很多 go 语言可以用来简化开发的用法,在对 go 基础有一定的了解之后,可以阅读下这篇文章。
更具体地,我们将使用基于 go 语言的 gin 框架来进行后端开发,应该有人的面试题就是这个吧(去年的梗,不用管它),使用 gorm 来操作数据库。gin 框架的优点包括高性能、支持中间件、路由管理方便、数据验证方便等等。而 gorm 的语法接近 MySQL,易于掌握。在这些技术的加持下,我们就可以进行一些后端的开发了。
另外的,我们社团也有一个gin框架基础上的,更适合挑战宝宝体质的框架,tz-gin, 感兴趣可以先去试试
![]() 在这些技术的学习中,
在这些技术的学习中,go 语言基础毫无疑问是最重要的,我们会在后续的课程中详细讲解。我们希望你能拥有扎实的语言基础,这样在使用框架的时候会更加得心应手。我们更推荐你在使用框架的过程中,能逐渐地了解这个框架的架构,学习到更本质的东西,而不是仅停留在调包的水平。

如果你对后端开发的兴趣浓厚,那么也可以考虑进一步学习,我们在这里给出一些例子,仅供参考
(以下内容适合后端兴趣浓厚,想要长期学习和开发的读者,不建议速通这些内容,但一定要坚持学习)
1.更多的数学知识:不要以为上课学了个高数和线代就可以高枕无忧了,时代在变化,这些最浅层的数学内容不能让你有着解决所有问题的能力,所以建议了解以及学习 阶的估计、基础数论、抽象代数 等内容,多学数学百利而无一害,不要停止这方面的持续精进,特别是在计算机方面,你会发现你几百行代码解决不了的问题可能就只需要做一个简单的流形的变换就解决了。
2.语言特性:迭代器,静态期和运行期特性,上下文(context),可变参数,反射,泛型,管理垃圾回收等。
3.算法基础:包括基本的排序、搜索、数据结构、优化等内容。了解常用容器的底层结构(如 map 底层是红黑树),判断、鉴权 api 时考虑前缀树等。
4.调试工具:我们可能不会详细讲述如何进行调试,但是自己需要了解,这点很重要。比如 go test 如何使用,如何查看内存占用,段错误(Segmentation Fault)是什么意思以及如何修复等。
5.常用框架:学会如何阅读框架源码,更进一步最好做到自己看框架底层。
6.学习复杂逻辑问题的解决:往后会遇见要求高性能的并行开发,如何共享内存、如何进行线程间的通信等,以及多线程中数据安全以及雷神之锤等问题场景。
7.数据库更多内容:mysql 索引(存储节点是 B+ 树结构),以及为什么少用 limit 做分页(考虑性能的话建议手动使用 where)等业务开发中的细节内容。学习缓存怎么设置,使用 Redis,Redis 为什么高效(存储节点是红黑树结构)。
8.更多计算机通用知识:强烈建议参照 linux 操作系统进行学习,包括内存结构(静态区、堆、栈等),存储中分页等细节内容,cpu 底层细节优化(如有时候大循环展开成 4 个循环反而高效的原因是因为 cpu 会自己进行数据的大小比较,循环展开有效的先将数据分块排序这些底层内容),并行开发时 cpu 和 gpu 的负载和表现,io 复用等底层内容。深入网络模块、协议、websocket,有条件的了解下 epoll。
Rest 是一种软件架构风格,并不是一种标准,相应的 Restful API 是一种接口设计风格,规范。前后端在开发过程中都会遇到路由管理的问题,遵循一些规范能让后端的接口设计更加合理,便于前端使用,也能让前端对资源的管理更加直观。
这种规范下的 URL 的 path 是需要认真考虑的,通常其组成如下
/{version}/{resources}/{resource_id}并且遵循下面的约定
-
不用大写字母,所有单词使用英文且小写。
-
连字符用中杠 "-" 而不用下杠 "_"。
-
正确使用 "/" 表示层级关系,URL 的层级不要过深,并且越靠前的层级应该相对越稳定。
-
结尾不要包含正斜杠分隔符 "/"。
-
URL 中不出现动词,用请求方式表示动作。
-
资源表示用复数不要用单数。
-
不要使用文件扩展名。
对于动词(请求方式)的使用,遵循下面的约定:
-
GET:从服务器查询
-
POST:在服务器创建新的资源
-
PUT:更新服务器资源
-
DELETE:从服务器删除资源
![]() 关于
关于 Restful API 的文章推荐:
当你使用 git 向仓库进行提交的时候,你可以附带提交信息,如下:
#shell
git commit -m "<提交信息>"在提交信息部分,你应当遵守 这样 的规范
Note
本章作者:wjj + syl
难度:⭐⭐⭐⭐⭐
涉及语言:shell, Go, javascript
并不是所有语言的源代码都可以直接运行,通常我们会把语言分为高级语言、低级语言、机器语言。机器语言由二进制代码组成,计算机可以直接使用,但是让开发者使用这种语言显然是不可能的。我们目前接触到的语言几乎都是高级语言,它们更接近人类的语言,并且能让开发者将精力集中在程序开发上,而不必在程序运行底层的一些细节上纠结。汇编语言是一种低级语言,它比高级语言要更加接近计算机硬件。
高级语言源代码并不能直接运行,而是要转化成某种机器看得懂的代码。对于在操作系统上运行的代码,应该转化为汇编代码,而对于在虚拟机上运行的代码,则应该转化为一些中间代码,比如字节码。编译就是进行这个过程。
比如我们后端使用的 Go 语言,就需要编译成机器码才能运行。Go 语言的工具包里提供了编译的工具,可以使用命令 go bulid 来对代码进行编译,也可以在编译的时候添加参数,即 [build flags] 位置上可以填写的参数:
#shell
go build [build flags] [packages]大家可以自行查阅可以添加的编译相关参数,如 -gcflags=-S 会输出汇编等。
当然了,在开发过程中,我们也可以使用 go run <文件名> 来编译运行了,它会生成一个临时的可执行文件。
想要从源代码生成可执行文件并不是一件容易的事。对于在操作系统运行的程序,比如 C 语言的程序,要经历预处理、编译、汇编、链接四个过程。

预处理:在这个阶段,预处理器将源代码中的预处理指令(如 #include、#define 等)替换为实际的内容。预处理器会根据指令展开头文件,处理宏定义,并删除注释等。
编译:编译器将预处理后的源代码转换为汇编代码。它会对每个源文件进行词法分析、语法分析和语义分析,生成相应的中间代码,并进行优化。
汇编:汇编器将编译生成的中间代码转换为机器可读的汇编代码,也就是机器码的文本表示。这个阶段将源代码转换为机器语言的汇编指令,但还没有生成可执行文件。
链接:链接器将汇编生成的目标文件以及可能的库文件链接在一起,生成最终的可执行文件。它会解析各个目标文件之间的符号引用和符号定义关系,将它们合并成一个完整的程序。
对于在虚拟机运行的程序,大致按照下面的流程。这里的前端和后端,当然不再是狭义的网络开发中的前端和后端了。编译过程中,还会对代码进行一些优化,比如乘法一般会被优化成位移,来提高程序的性能。


你可能暂时不太理解每个细节,没有关系,先通过上面图片的大标题,感受一下编译的过程。下面我们将会对 Go 以及 javascript 的编译流程进行简单讲述,当然不要求读者完全掌握。
这是 Go 官方介绍自己的编译器的网址,https://go.dev/src/cmd/compile/README,感兴趣可以看一看。我们下面具体讲一下 Go 编译器是如何工作的。先看几个 前置知识。
抽象语法树(Abstract Syntax Tree、AST),是源代码语法的结构的一种抽象表示,它用树状的方式表示编程语言的语法结构 1。抽象语法树中的每一个节点都表示源代码中的一个元素,每一棵子树都表示一个语法元素,以表达式 2 * 3 + 7 为例,编译器的语法分析阶段会生成如下图所示的抽象语法树(看起来很像中缀树...)。下面是一个简单表达式的抽象语法树。

作为编译器常用的数据结构,抽象语法树抹去了源代码中不重要的一些字符 - 空格、分号或者括号等等。编译器在执行完语法分析之后会输出一个抽象语法树,这个抽象语法树会辅助编译器进行语义分析,我们可以用它来确定语法正确的程序是否存在一些类型不匹配的问题。
静态单赋值(Static Single Assignment、SSA)是中间代码的特性,如果中间代码具有静态单赋值的特性,那么每个变量就只会被赋值一次。在实践中,我们通常会用下标实现静态单赋值,这里以下面的 Go 代码举个例子:
x := 1
x := 2
y := x经过简单的分析,我们就能够发现上述的代码第一行的赋值语句 x := 1 不会起到任何作用。下面是具有 SSA 特性的中间代码,我们可以清晰地发现变量 y_1 和 x_1 是没有任何关系的,所以在机器码生成时就可以省去 x := 1 的赋值,通过减少需要执行的指令优化这段代码。
x_1 := 1
x_2 := 2
y_1 := x_2因为 SSA 的主要作用是对代码进行优化,所以它是编译器后端的一部分;当然代码编译领域除了 SSA 还有很多中间代码的优化方法,编译器生成代码的优化也是一个古老并且复杂的领域(俗称编程界的黑魔法),这里就不会展开介绍了。
最后要介绍的一个前置知识就是指令集了,很多开发者在都会遇到在本地开发环境编译和运行正常的代码,在生产环境却无法正常工作,这种问题背后会有多种原因,而不同机器使用的不同指令集可能是原因之一。
我们大多数开发者都会使用 x86_64 的 linux 作为工作上主要使用的设备,在命令行中输入 uname -m 就能获得当前机器的硬件信息:
$ uname -m
x86_64x86 是目前比较常见的指令集,除了 x86 之外,还有 arm 等指令集,不同的处理器使用了不同的架构和机器语言,所以很多编程语言为了在不同的机器上运行需要将源代码根据架构翻译成不同的机器代码。
复杂指令集计算机(CISC)和精简指令集计算机(RISC)是两种遵循不同设计理念的指令集,从名字我们就可以推测出这两种指令集的区别:
- 复杂指令集:通过增加指令的类型减少需要执行的指令数;
- 精简指令集:使用更少的指令类型完成目标的计算任务;
早期的 CPU 为了减少机器语言指令的数量一般使用复杂指令集完成计算任务,这两者并没有绝对的优劣,它们只是在一些设计上的选择不同以达到不同的目的。
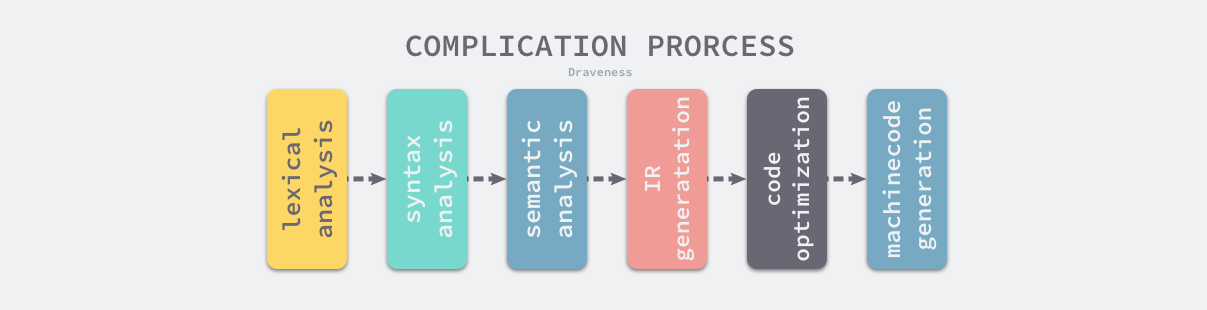
Go 语言编译器的源代码在 src/cmd/compile 目录中,目录下的文件共同组成了 Go 语言的编译器,学过编译原理的人可能听说过编译器的前端和后端,编译器的前端一般承担着词法分析、语法分析、类型检查和中间代码生成几部分工作,而编译器后端主要负责目标代码的生成和优化,也就是将中间代码翻译成目标机器能够运行的二进制机器码。 编译原理的核心过程如下所示。
Go 的编译器在逻辑上可以被分成四个阶段:词法与语法分析、类型检查和 AST 转换、通用 SSA 生成和最后的机器码生成。
所有的编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器(lexer)。
而语法分析的输入是词法分析器输出的 Token 序列,语法分析器会按照顺序解析 Token 序列,该过程会将词法分析生成的 Token 按照编程语言定义好的文法(Grammar)自下而上或者自上而下的规约,每一个 Go 的源代码文件最终会被归纳成一个 SourceFile 结构:
SourceFile = PackageClause ";" { ImportDecl ";" } { TopLevelDecl ";" } .词法分析会返回一个不包含空格、换行等字符的 Token 序列,例如:package, json, import, (, io, ), …,而语法分析会把 Token 序列转换成有意义的结构体,即语法树:
"json.go": SourceFile {
PackageName: "json",
ImportDecl: []Import{
"io",
},
TopLevelDecl: ...
}Token 到上述抽象语法树(AST)的转换过程会用到语法解析器,每一个 AST 都对应着一个单独的 Go 语言文件,这个抽象语法树中包括当前文件属于的包名、定义的常量、结构体和函数等。
Go 语言的语法解析器使用的是 LALR(1) 的文法,对解析器文法感兴趣的读者可以在推荐阅读中找到编译器文法的相关资料。

值得注意的是,语法解析的过程中发生的任何语法错误都会被语法解析器发现并将消息打印到标准输出上,整个编译过程也会随着错误的出现而被中止。
当拿到一组文件的抽象语法树之后,Go 语言的编译器会对语法树中定义和使用的类型进行检查,类型检查会按照以下的顺序分别验证和处理不同类型的节点:
- 常量、类型和函数名及类型;
- 变量的赋值和初始化;
- 函数和闭包的主体;
- 哈希键值对的类型;
- 导入函数体;
- 外部的声明;
通过对整棵抽象语法树的遍历,我们在每个节点上都会对当前子树的类型进行验证,以保证节点不存在类型错误,所有的类型错误和不匹配都会在这一个阶段被暴露出来,其中包括:结构体对接口的实现。
类型检查阶段不止会对节点的类型进行验证,还会展开和改写一些内建的函数,例如 make 关键字在这个阶段会根据子树的结构被替换成 runtime.makeslice 或者 runtime.makechan 等函数。下图为类型检查阶段对 make 进行改写。
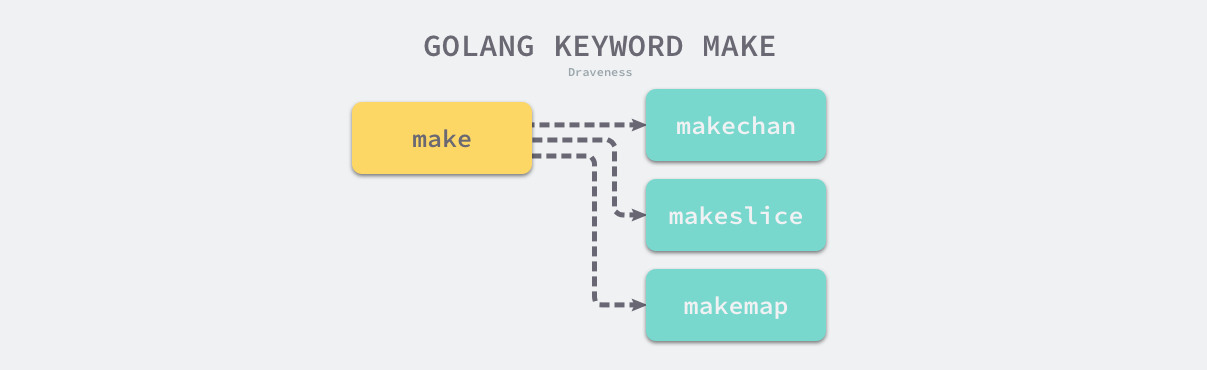
类型检查这一过程在整个编译流程中还是非常重要的,Go 语言的很多关键字都依赖类型检查期间的展开和改写。
当我们将源文件转换成了抽象语法树、对整棵树的语法进行解析并进行类型检查之后,就可以认为当前文件中的代码不存在语法错误和类型错误的问题了,Go 语言的编译器就会将输入的抽象语法树转换成中间代码。
在类型检查之后,编译器会通过 cmd/compile/internal/gc.compileFunctions 编译整个 Go 语言项目中的全部函数,这些函数会在一个编译队列中等待几个 Goroutine 的消费,并发执行的 Goroutine 会将所有函数对应的抽象语法树转换成中间代码。下图为并发编译过程

由于 Go 语言编译器的中间代码使用了 SSA 的特性,所以在这一阶段我们能够分析出代码中的无用变量和片段并对代码进行优化
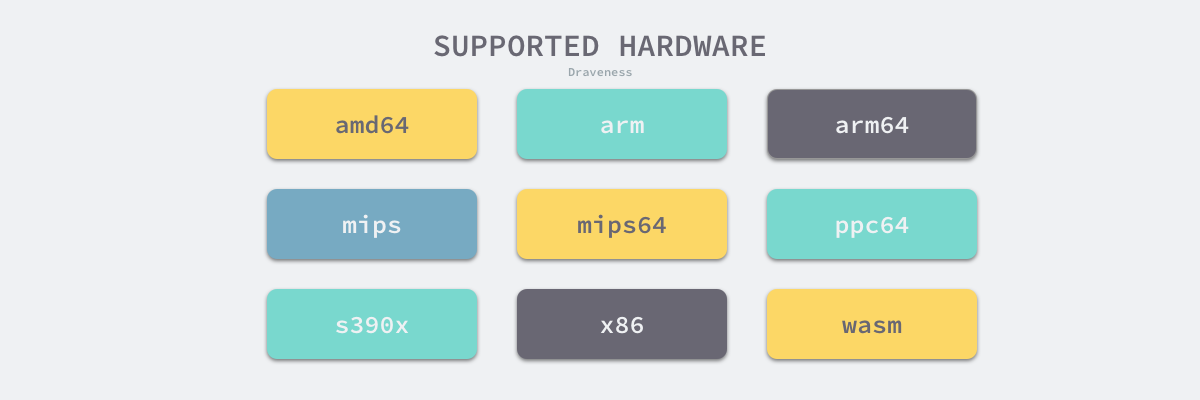
Go 语言源代码的 src/cmd/compile/internal 目录中包含了很多机器码生成相关的包,不同类型的 CPU 分别使用了不同的包生成机器码,其中包括 amd64、arm、arm64、mips、mips64、ppc64、s390x、x86 和 wasm,其中比较有趣的就是 WebAssembly(Wasm)了。
作为一种在栈虚拟机上使用的二进制指令格式,它的设计的主要目标就是在 Web 浏览器上提供一种具有高可移植性的目标语言。Go 语言的编译器既然能够生成 Wasm 格式的指令,那么就能够运行在常见的主流浏览器中。
$ GOARCH=wasm GOOS=js go build -o lib.wasm main.go我们可以使用上述的命令将 Go 的源代码编译成能够在浏览器上运行 WebAssembly 文件,当然除了这种新兴的二进制指令格式之外,Go 语言经过编译还可以运行在几乎全部的主流机器上,不过它的兼容性在除 Linux 和 Darwin 之外的机器上可能还有一些问题,例如:Go Plugin 至今仍然不支持 Windows。下图为 Go 语言支持的架构。
Go 语言的编译器入口在 src/cmd/compile/internal/gc/main.go 文件中,其中 600 多行的 cmd/compile/internal/gc.Main 就是 Go 语言编译器的主程序,该函数会先获取命令行传入的参数并更新编译选项和配置,随后会调用 cmd/compile/internal/gc.parseFiles 对输入的文件进行词法与语法分析得到对应的抽象语法树:
func Main(archInit func(*Arch)) {
...
lines := parseFiles(flag.Args())得到抽象语法树后会分九个阶段对抽象语法树进行更新和编译,就像我们在上面介绍的,抽象语法树会经历类型检查、SSA 中间代码生成以及机器码生成三个阶段:
- 检查常量、类型和函数的类型;
- 处理变量的赋值;
- 对函数的主体进行类型检查;
- 决定如何捕获变量;
- 检查内联函数的类型;
- 进行逃逸分析;
- 将闭包的主体转换成引用的捕获变量;
- 编译顶层函数;
- 检查外部依赖的声明;
对整个编译过程有一个顶层的认识之后,我们重新回到词法和语法分析后的具体流程,在这里编译器会对生成语法树中的节点执行类型检查,除了常量、类型和函数这些顶层声明之外,它还会检查变量的赋值语句、函数主体等结构:
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op != ODCL && op != OAS && op != OAS2 && (op != ODCLTYPE || !n.Left.Name.Param.Alias) {
xtop[i] = typecheck(n, ctxStmt)
}
}
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if op := n.Op; op == ODCL || op == OAS || op == OAS2 || op == ODCLTYPE && n.Left.Name.Param.Alias {
xtop[i] = typecheck(n, ctxStmt)
}
}
...类型检查会遍历传入节点的全部子节点,这个过程会展开和重写 make 等关键字,在类型检查会改变语法树中的一些节点,不会生成新的变量或者语法树,这个过程的结束也意味着源代码中已经不存在语法和类型错误,中间代码和机器码都可以根据抽象语法树正常生成。
initssaconfig()
peekitabs()
for i := 0; i < len(xtop); i++ {
n := xtop[i]
if n.Op == ODCLFUNC {
funccompile(n)
}
}
compileFunctions()
for i, n := range externdcl {
if n.Op == ONAME {
externdcl[i] = typecheck(externdcl[i], ctxExpr)
}
}
checkMapKeys()
}在主程序运行的最后,编译器会将顶层的函数编译成中间代码并根据目标的 CPU 架构生成机器码,不过在这一阶段也有可能会再次对外部依赖进行类型检查以验证其正确性。
虽然我们常说 js 是动态类型语言,但是其实 js 也是一门编译语言。与传统编译不同的地方在于,js 并非提前编译,编译结果也不能在分布式系统上移植。这一部分内容相较于 Go 编译较少,而且大部分内容是相似的,这里就使用流程图简单概括了。
js 的编译主要工具有:
-
引擎 从头到尾负责整个 JavaScript 程序的编译和执行过程。
-
编译器 引擎的好朋友之一,负责语法分析及代码生成等一系列脏活累活
-
作用域 引擎的另一个好朋友,负责收集并维护由所有声明的变量组成的一系列的查询,并实施一套非常严格的规则,确定当前所执行的代码对这些变量的访问权限。
在不考虑优化的前提下,编译流程可见下图:(其中 AST等内容可见上文)

这其中我们着重关注词法作用域的规则,包括 var/let 的区别,提升,闭包等概念。

Note
本章作者:cgy + Grok 4
难度:⭐⭐⭐
涉及语言:Go
Debug(下面都称作调试,因为中英文切起来很麻烦)的目的是找出代码中的错误、性能瓶颈或意外行为,程序员写程序几乎不可能一遍就写得完全正确,因此掌握调试技能是很重要的。常见的调试场景包括代码逻辑错误、内存泄露问题和并发问题。
由于笔者仅熟悉后端,本篇目前(2025年8月)仅涉及后端(Go 语言)的程序调试。
[!NOTE] 一点题外话(并非题外)
在项目正式投入使用前一定要先充分地测试,及早发现问题,避免生产环境崩溃,否则到时候时间紧任务重(因为用户随时都需要用)修 bug 会压力山大。
Go 调试工具概述 Go 提供了丰富的内置工具和第三方支持:
- 简单方法:打印语句、日志输出,适合快速验证。
- 调试器:Delve(dlv),Go 的专用调试器,支持断点、变量检查等。
- IDE 支持:VS Code、GoLand 等集成 Delve,提供图形化调试界面。
- *高级工具:如
go tool pprof(内存分析)、-race标志(数据竞争检测)。
调试时,建议从简单方法入手,逐步掌握高级工具,标“*”的部分仅做了解。记住:好的调试习惯包括编写单元测试(使用 go test),这能预防许多问题。
1. fmt.Println
最原始但有效的调试方式是使用打印语句。它不需要额外工具,利用它可以快速打印出相应时刻变量值,也能借助它来判断条件分支走向。Go 的 fmt 包提供了丰富的打印函数。
package main
import "fmt"
func main() {
x := 10
y := 20
fmt.Println("x 的值是:", x) // 简单打印
fmt.Printf("y 的值是: %d\n", y) // 格式化打印
sum := x + y
fmt.Println("计算结果:", sum)
// 打印变量值
if result == 15 {
fmt.Println("计算正确!")
} else {
fmt.Println("计算错误!")
}
// 判断条件分支走向
}2. (简单调试中的)高级技巧
- 使用 log 包:比 fmt 更结构化,它默认会输出到标准错误流(stderr),并自动添加时间戳,方便追溯问题。而且支持不同日志级别,方便区分问题严重级别。一般大项目都需要保存日志,以便事后定位问题。
package main
import (
"log"
"os" // 引入操作系统能力,用于读取日志文件
)
func main() {
// 你可以将日志输出到文件
logFile, err := os.OpenFile("app.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
log.Fatalln("打开日志文件失败:", err)
}
log.SetOutput(logFile)
userID := 1
log.Printf("开始处理用户 %d 的请求", userID)
// 干活中,处理用户请求
log.Printf("用户 %d 的请求处理完毕", userID) // 一般打印输出
log.Fatalf("警告:自毁程序已启动...") // 发生致命错误
}- JSON 打印:对于复杂结构体,使用
json.Marshal转换为 JSON 格式打印,便于阅读。
import "encoding/json"
data := struct{ Name string }{Name: "syl"}
jsonData, _ := json.Marshal(data)
fmt.Println(string(jsonData)) // 输出: {"Name":"syl"}注意:打印调试适合小规模问题,过度使用会使代码混乱,你也不想从一堆 println 中间找出真正在干活的代码吧,因此调试完成后记得移除或注释掉打印语句,或者改用接下来要介绍的方法。
集成开发环境(IDE)提供了图形化调试支持,让你能“暂停”代码( 砸瓦鲁多!),逐步执行、检查变量。推荐使用 JetBrains 的 GoLand 或 VS Code,它们都集成 Delve 调试器。
参考材料:CS61B 的 Debugging lab lab2 和 lab3 会引导你快速上手 IntelliJ IDEA 的调试方法,非常推荐,看看图文讲解即可,感兴趣的话推荐系统学 CS61B,数据结构好课。P.S. IntelliJ 是 JetBrains 的 Java IDE,和 GoLand 的使用方法基本是一样的。
设置 IDE 调试
建议直接使用 GoLand 进行尝试,VS Code 的配置比较繁琐。这部分建议上手操作,仅阅读文档很难掌握。
- VS Code 配置:
- 安装 Go 扩展(vscode-go)。
- 在 launch.json 中添加调试配置:
{ "version": "0.2.0", "configurations": [ { "name": "Launch", "type": "go", "request": "launch", "mode": "auto", "program": "${fileDirname}" } ] }
- GoLand 配置:开箱即用,直接点击上方虫子形状的“Debug”按钮。(如果不清楚“构建/调试配置”怎么弄就直接添加一个
Go 构建,然后确定就行了)
核心功能
- 断点(Breakpoints):鼠标移动到代码左侧行号上,此时行号会变成一个红点,点击后即设置断点,这行代码背景色会变红,程序运行到这里会暂停。(不打断点的调试就和运行没啥区别了)
- 条件断点:右键代码行号处的红点,可设置断点条件,比如有一段代码是多次循环,而你需要在
i = 1145时暂停程序,条件中就可以写i = 1145。 - 步进执行:
当前变量值是高亮的那一行代码尚未执行时刻的。
- 步过(Step Over):执行当前行,不进入函数。
- 步入(Step Into):进入函数内部。
- 步出(Step Out):跳出当前函数。
- 变量检查:暂停时,在调试面板中可查看变量值、栈帧和 goroutine 状态。
- 表达式求值:在调试面板上方输入表达式,如
x + y,实时计算,支持函数调用。

内存泄露是指程序未正确释放内存,只从操作系统那里拿而没有还回去,导致内存占用不断增加的现象。如果内存泄露持续发生,内存都要被吃干抹净了,现代操作系统就会触发保护机制,开杀,杀掉一些进程来释放内存,从而恢复正常运转。而在极端的情况下,操作系统都可能被它干崩溃,然后强制重启。
虽然 Go 有垃圾回收(GC),但仍可能发生泄露,如未关闭的 goroutine 或缓存增长,因此掌握如何调试内存泄露也是有好处的。
使用 Go 的内置 pprof 工具
- 启用 pprof:在代码中导入
net/http/pprof并启动 HTTP 服务。import ( _ "net/http/pprof" "net/http" ) go func() { http.ListenAndServe("localhost:6060", nil) }()
- 采集数据:运行程序,访问
http://localhost:6060/debug/pprof/heap?debug=1获取堆快照。 - 分析:使用
go tool pprof。- 命令:在终端中执行
go tool pprof http://localhost:6060/debug/pprof/heap - 在 pprof 交互模式下,输入
top查看内存占用前几项,list funcName查看具体函数。 - 多次查看内存占用情况,关注
inuse_space这一项,如果某个函数占用的内存持续增长,表明很可能发生了内存泄露。
- 命令:在终端中执行
数据竞争(Data Race)是并发编程的常见问题,指多个 goroutine 同时读写共享变量,导致不可预测行为。Go 提供了内置检测器。
启用检测
编译或运行时添加 -race 标志:
- 构建:
go build -race - 测试:
go test -race - 运行:
go run -race main.go 这一工具依赖 gcc,Windows 建议安装 msys2,类 UNIX 默认都会解决()。
如果无特殊的输出,说明未检测到竞争,否则Go 会打印详细栈踪迹:
WARNING: DATA RACE
Read at 0x000001234567 by goroutine 7:
main.readVar()
/path/to/file.go:10 +0x3a
Previous write at 0x000001234567 by goroutine 6:
main.writeVar()
/path/to/file.go:15 +0x4b
修复策略
这一部分涉及并发编程的知识,感兴趣的话建议系统学习。
- 使用互斥锁(Mutex):保护共享变量。
- 通道(Channels):用通道代替共享内存,实现安全通信。
- 原子操作:使用
sync/atomic包,如atomic.AddInt32。 - 避免竞争:设计时最小化共享状态,使用不可变数据。
注意:-race 会增加 2-20 倍的开销,仅用于开发/测试。生产环境用其他监控工具。
Note
本章作者:syl + 杰青书记
难度:自适应
涉及语言:?
这一部分特别给linux发行版用户使用,本人是Arch linux,就用这个举例了
- 1.boot process
- 2.system/user config
- 3.package/tools
为什么要知道启动流程:对于个人pc而言,一般启动就算会出问题也就是在systemd或者桌面session启动那一部分出事,但是要是你在用服务器的话,一个黑漆漆的界面可就说不好了,所以,了解一下启动流程还是很必要的,最起码你能快速定位问题然后去搜索解法
先来一张图

- 这里就是linux系统启动步骤,首先是bios和grub引导启动(当然你也可能是其他引导方式),这两个步骤通常硬件设备没什么问题就不会出事,也不需要细究这些。另外多说一句,据说如果是windows+linux双系统的话,windows更新可能会破坏grub引导,因为MicroSoft喜欢往引导里面乱塞东西,比如什么恢复什么的。
ls
BOOT/ Microsoft/之后的部分是kernal init的启动,这里systemd是最主流的方式,但是还有其他的,比如void linux就使用的是runit。 如果你经常使用一些系统级配置的话,对systemd应该不陌生。到这个地方出现问题的话,可以考虑使用linux recovery模式去恢复一下,因为到现在还没法走到tty等部分,所以出事了也是一片黑屏,只有去恢复模式了。一般来说问题主要就是一些软件配置出错,或者依赖爆炸了这种。
启动了init这一步后,会执行一些自启动脚本,比如bashrc,profile等,这里就是用户自定义的部分了,比如我的profile:
-> cat .profile
export GO111MODULE=on
export GOPROXY=https://goproxy.cn
export GTK_IM_MODULE=fcitx5
export QT_IM_MODULE=fcitx5
export XMODIFIERS="@im=fcitx5"
export SDL_IM_MODULE=fcitx5
export GLFW_IM_MODULE=fcitx5
# fcitx5 &
# Added by Toolbox App
export PATH="$PATH:/home/asice-cloud/.local/share/JetBrains/Toolbox/scripts"
. "$HOME/.cargo/env"- 我的内容挺简单的,主要是系统也没有配很复杂,这也是Arch的好处之一,如果有ubuntu用户可以看看自己的bashrc等,可以看到某无良公司自己乱塞了多少破烂东西进去。Ubuntu随便配置一下基本开发环境就动辄150G,我这Arch环境配了还下了好多游戏也就100G才。
这些自启动脚本通常也就包含一些代理,环境变量,以及一些应用
最后是user login后,这里将会启动session, 所谓session,之前的后端里面有所涉及,总体概念大差不差。是的和你想象的一样,前端后端只是个相对概念而已,你看到的用户桌面也可以视为前端,后面支撑着的是后端。同理你现在写编程语言,能看到的都是前端,而进入编译阶段后台的运行才是真正的后端。
回到正题,现在流行的桌面后台服务器有wayland和X11, wayland是更安全和先进的。至于桌面而言,有多种选择,常见的gnome和kde,如果你和我一样喜欢折腾,可以考虑hyprland或者cwm/river等,这些都是很开放的(我不是说gnome不好,平常打游戏我也是用gnome)。总而言之桌面自己选择就好。
有些人应该在桌面启动的过程中也遇到过问题,比如会出现“a unexpect error occured”这种,然后没法进入桌面。一般来说这都是更新的时候把依赖干掉了,解决方案也很简单, ub或者debian就直接进tty或者恢复模式然后 sudo apt --fix-broken, 或者reinstall强制更新一下你的桌面就行。 Arch直接pacman -Syu 你的桌面,强制更新一下就好。
终端选择
不管是个人用户还是服务器,终端都是必不可少的东西。这里也不多比较各种终端优劣,直接推荐如下:
1.zsh/fish 这种属于简单配置,开箱即用,各种功能,诸如补全和预览,语法高亮,历史记录等等都是全的

2. kitty/alacritty : 需要一定的配置,不过配好了相当帅,比如我用的kitty(上图),就有类似于neovide的光标跳转动画。网上有不少配置比我好多了
编辑器
编辑器有两类,终端编辑器(emacs,vim等),非终端编辑器(三大编辑器,subline, chromium, chromium(可以自己猜一下这两个是什么))
如果你是gnome,kde用户,那你选择任何编辑器都可以
但是如果你用的其他桌面,如hyprland这种,那么,诸如vscode就会出现分辨率,线程狂飙等bug,因此,对于其他桌面用户而言,终端反而是最常用的。而如果你是服务器用户,那么终端就是唯一选择了。
回到正题,
有如下比较优秀的终端编辑器: Emacs , vim , neovim, nano ... 更多见https://linuxblog.io/50-linux-text-editors/
这里我不评价各自的好坏,就用途而言,vim适合系统配置,也就随便改改几个点,neovim则是专门用来写代码的vim的改版,可以装插件,改配置,体验很好,理论上你能把neovim配置的像idea或者vscode那样全面(我的neovim配置https://github.com/Asice-Cloud/myvim)
美化你的桌面(gnome&kde)
![]() 默认界面那么丑,不会有人看的下去把(杰青你不要引战好不好)
默认界面那么丑,不会有人看的下去把(杰青你不要引战好不好)
(有对hyprland感兴趣的可以找我,这里就不展开了)
这个东西其实要看你的桌面环境,本人用过kde,Gnome,各个都不同。由于本人对Gnome比较熟悉,就重点放在Gnome上了
在这个网站上直接找现成的主题,配色什么的,操作就非常简单
Gnome插件能够改善他的功能,假如你是刚从windows切换过去的用户,那么你可能更喜欢在屏幕下方的状态栏,任务栏,那么你可以安装一个Dash pin to dock插件

![]() 有人说这是微软孝子行为,我的评价是有点抽象了(欲盖弥彰)
有人说这是微软孝子行为,我的评价是有点抽象了(欲盖弥彰)
窗口的动画,可以用css实现,要看你是什么窗口管理器,然后去相应的文档下面找
设计你自己的桌面应用
很多情况下,插件并不能完美的匹配你的需求,那么你可以设计自己的桌面应用,Gnome的系统窗口大都是基于GTk4 的(评价是不如Qt),你可以利用这个框架自己写一个应用,这和写网页前端其实是差不太多的,比如下图是一个启动器
启动器其实github上有很多,比如rofi,不过rofi在gnome的表现似乎很糟糕,所以这个启动器是仿着rofi做的

我们需要一些工具来让我们更好的了解我们的linux,下面我简单介绍一些
进程分析:htop
安装很简单:sudo apt install htop,或者 sudo pacman -Syu htop

使用也很简单,下面都有提示,跟着用就好了
硬件检测:psensor
安装和htop一样

其实一般系统也会带sensors用于检测,不过是命令行界面,如果你能习惯,那么用那个也可以
系统信息展示:fastfetch,neofetch
其实这个更多的是展示作用,可以展示你的电脑的各个配置 ()

我的这个fastfetch还没有美化过,想要更好看的fastfetch可以去找syl
(这是我的fastfetch)

处理压缩文件:unrar,zip
当然了,在linux上碰到的可能更多是.tar.gz这种,你可以用tar -czvf和tar -xzvf去处理,只是有的时候,你也许也会遇到.rar,那么unrar是不错的工具
linux工具那么多,也不可能在这里罗列全,需要啥的时候,直接上网查资料或者问ai,总有适合你的
**一些有趣的工具和技巧 **
- 更新和技巧: 下载软件的时候,如果是arch,请不要使用
pacman -S package, 而是pacman -Syu package,这样保证下载的工具依赖都是最新的。 如果是apt, 在系统更新之后,最好使用apt reinstall强制更新某些落后的包,至于哪些出问题了,这里有个简单的方法,使用sudo dmesg | grep error, 可以方便的找到报错的组件。或者最后的操作,用apt --fix-broken修复依赖 - 系统工具选择: 系统可以用一些东西进行维护,比如tlp管理你的电源计划,能够减少一部分发热(个人感觉不多),或者找类似rog control center这样的,厂商专门给linux做的配置管理软件。另外建议有需要的话用timeshift去备份几个,防止某一天真出意外了。
- linux的隐藏好处: linux下系统占用比windows小多了,另一方面steam也全面兼容了linux,所以你在linux上基本上可以玩各种东西,比win帧率还高出不少。(评价是windows已经可以淘汰了)
为什么要攀登,因为山就在那里
非常感谢各位能够阅读到这里。时代在发展,计算机知识已经成为了现代社会生存必要技能。希望本文档和后续培训能够对各位起到帮助。本文档由:cupid:孙源隆,:pizza:王俊杰, :kiss:陈冠余共同编写,也感谢对文档提出指导和改进意见的所有人。
:heart:我们从来不要求任何人一定要成为什么计算机大师,也不要求任何人完美完成各种任务,只是想通过这门综合性科学,让有着共同兴趣爱好的大家聚在一起。,你们的计算机之路刚刚开始,正如同人生一样未来充满了可能。我们也希望学习和相处的过程中各位对计算机世界有更多的了解,对世界的神秘和未知产生更多的斗志和想法。如果有可能的话,我们同样希望未来的某一天,当各位回顾过往,能够想起计算机的玄妙,想起自己沉浸在 0 和 1 的世界,也能够想起在挑战网度过的时光。