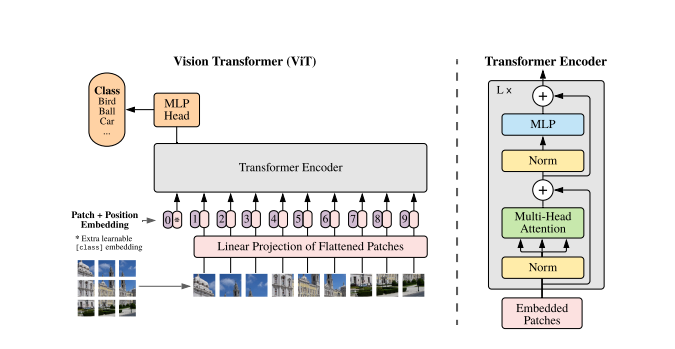
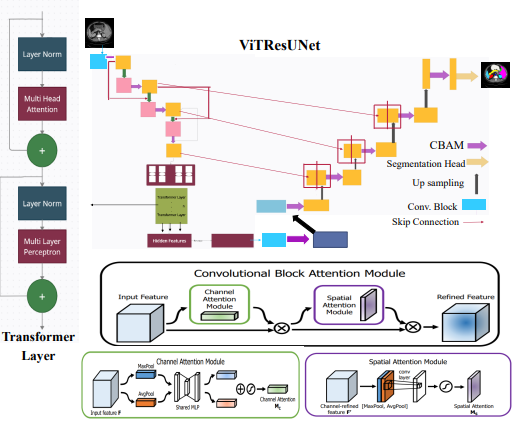
ViTResUNet is a hybrid CNN-Transformer architecture with the backbone of TransUNet. The experiments were conducted on Synapse multi-organ segmentation dataset.
-
Access to the synapse multi-organ dataset:
- Sign up in the official https://www.synapse.org/ and download the dataset. Convert them to numpy format, clip the images within [-125, 275], normalize each 3D image to [0, 1], and extract 2D slices from 3D volume for training cases while keeping the 3D volume in h5 format for testing cases.
- It is possible to request the preprocessed dataset from the original repo authors.
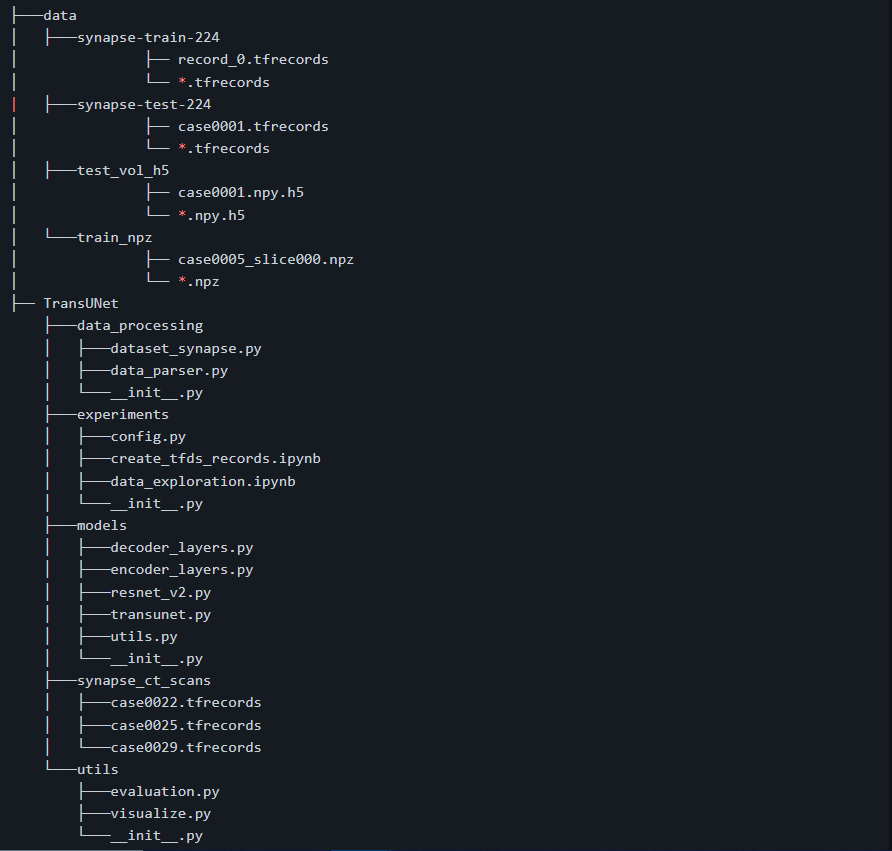
- The architecure is given below for better understanding
Vision Transformer ( You can watch this repo https://github.com/RadeenXALNW/Vision-Transformer-ViT ) for better understanding the intuition