
在全球积极推动可持续发展的大背景下,我国积极推动能源转型战略方针,风光发电所代表的可再生能源产业蓬勃发展,新能源发电市场规模正以创纪录的速度逐年增长。然而与此同时,新能源发电受不可控因素影响大,发电量不稳定、波动性强、难预测等问题也日益凸显,建立针对未来能源供需形势监测和预警机制的必要性日益增加。新能源供给与交易预测建设亟需科学化、智能化变革。目前,在新能源时序数据预测领域主要有以下痛点问题:数据样本量少、质量参差不齐,预测精确度低;传统模型不具备少样本学习能力、二次开发难度大;数据采集范围受限、精确度和覆盖度低等。亟需一个高精度、高效率、智能化的能源场景时序预测系统。
针对上述预测的相关痛点问题,系统创新性地提出了 Predenergy 能源场景时序预测大模型。团队为该模型独创性地设计了时空双模态特征处理模块 STDM、混合能源时序专家模块 MoTSE、基于 PaddleNLP 的 Decoder 特征解码模块和多源数据持续整合方案,从整体架构上提升了对时序数据的特征分析和建模能力。同时,我们通过搜集整理构建通用领域大规模时序数据集 ETSD 完成了对模型的训练,并在应用层面设计实现能源决策智能体 Eneragent 以提升用户使用体验。
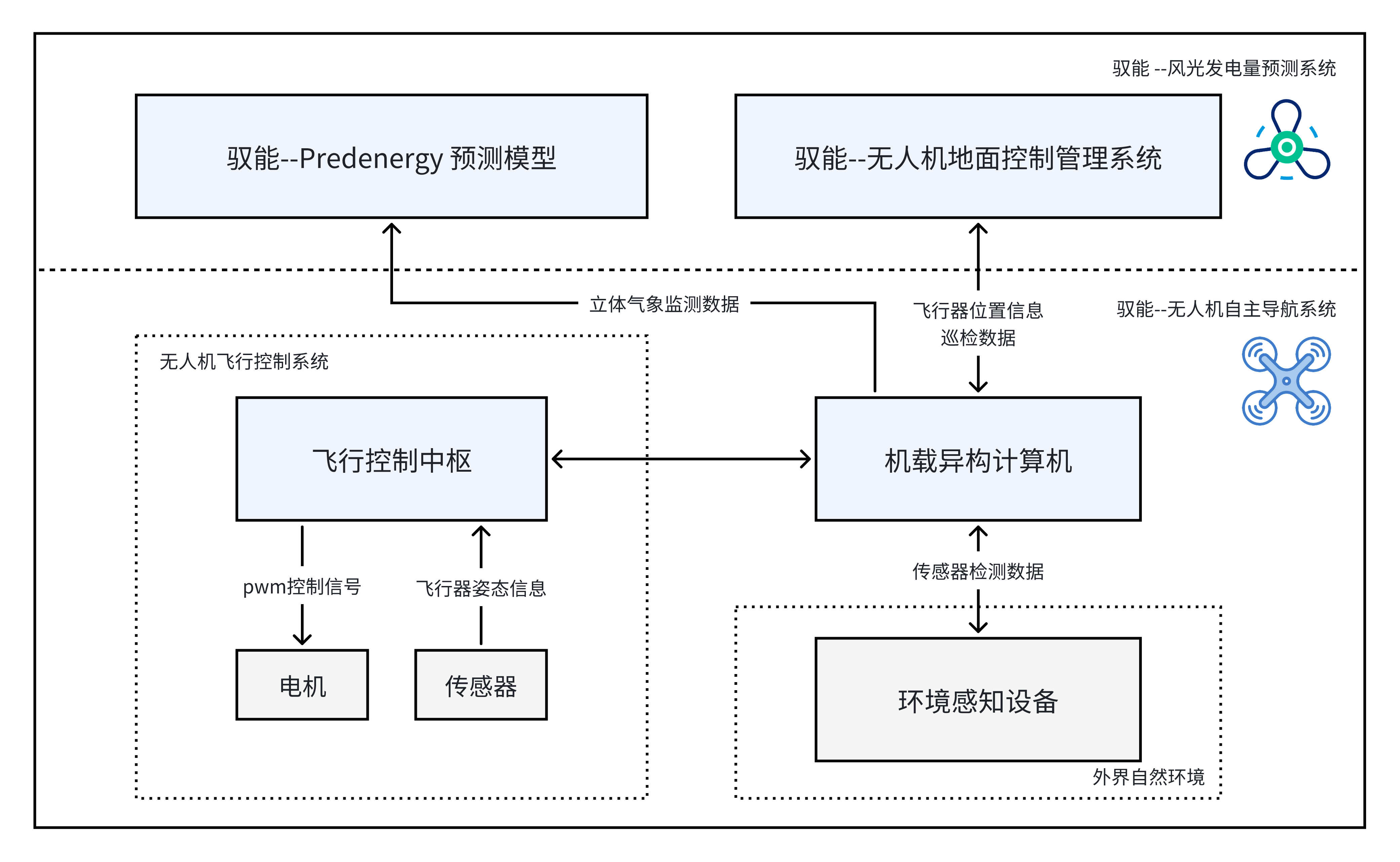
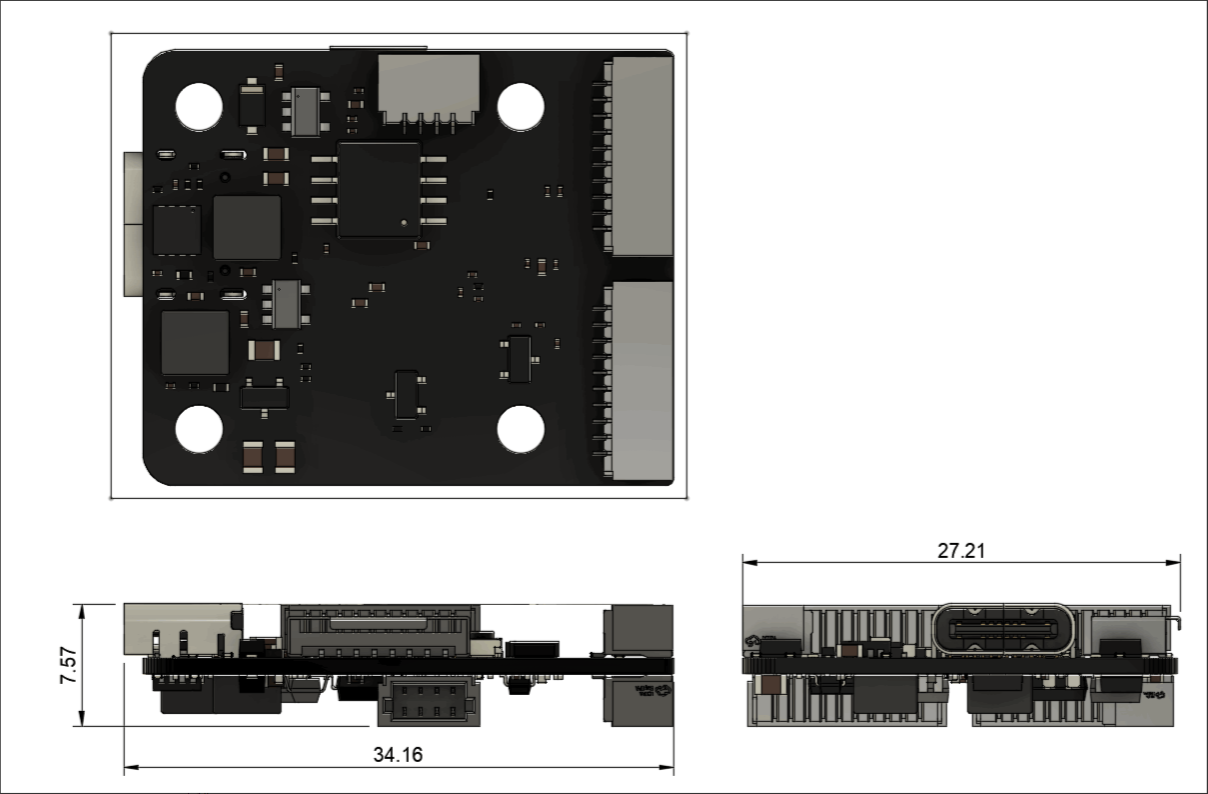
与此同时,团队通过自研无人机平台,以完成对数据的采集和日常巡检工作。具体来说,在无人机的设计上,我们从硬件层面进行了创新性研发,突破传统无人机平台限制,自主研发飞控主板,独立实现一体化数据采集模块。同时我们设计实现了自主运动规划算法和太阳能板隐患识别算法,显著提高了无人机实际落地实用能力。
模型使用体验直达:https://api-5er8s3a6h7r6m3de.aistudio-app.com/app-inference-demo.html
项目网页部署地址:https://api-5er8s3a6h7r6m3de.aistudio-app.com/app-index.html
项目完整介绍文档:https://pcnja0wzx8ci.feishu.cn/wiki/NObnwuIlpiVpTvkGwgJcg8Jfnfb
- 模型源码仓库:https://github.com/RXKbill/Predenergy.git
- 模型设计介绍:https://pcnja0wzx8ci.feishu.cn/wiki/MbDqwjmWHiuiCNkjwaFcTTh3ndc
- 模型实验结果:https://pcnja0wzx8ci.feishu.cn/wiki/G79xweodgiEP5Xk90tecQszYn8d
- 完整数据集:https://aistudio.baidu.com/datasetdetail/351403
- 数据集设计介绍:https://pcnja0wzx8ci.feishu.cn/wiki/L177wns61igiU2kg4jVcyFXln7b
- 数据集实验结果:https://pcnja0wzx8ci.feishu.cn/wiki/Xj5ow54gcieJyAkQFxHc8hPHnbf
- 无人机源码仓库:https://github.com/RXKbill/Yunergy_UAV.git
- 无人机设计介绍:https://pcnja0wzx8ci.feishu.cn/wiki/R8ahwHPefieiNdkZkyUcsk72nLg
- 无人机飞行视频:https://pcnja0wzx8ci.feishu.cn/wiki/Iqe9w7knjiQR8ekYKnvcfyfFnrd
- 前后端源码仓库:https://github.com/RXKbill/Yunergy_Web.git
- 前后端使用指南:https://pcnja0wzx8ci.feishu.cn/wiki/Lhw7w89tgiiCidkIcdTcklB6nbe(该指南不包含推理示例,相关使用方法见下)
模型使用体验直达:https://api-5er8s3a6h7r6m3de.aistudio-app.com/app-inference-demo.html
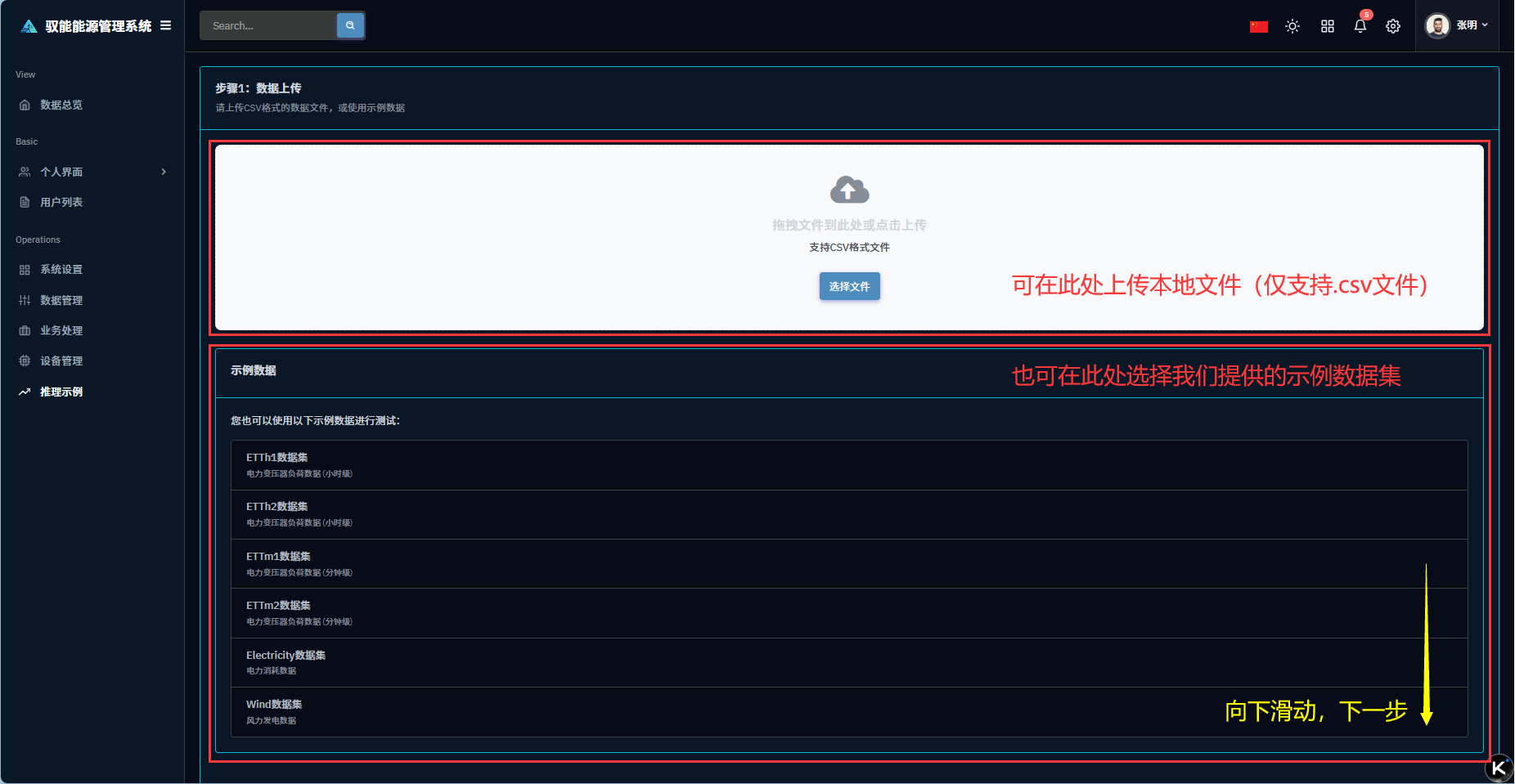
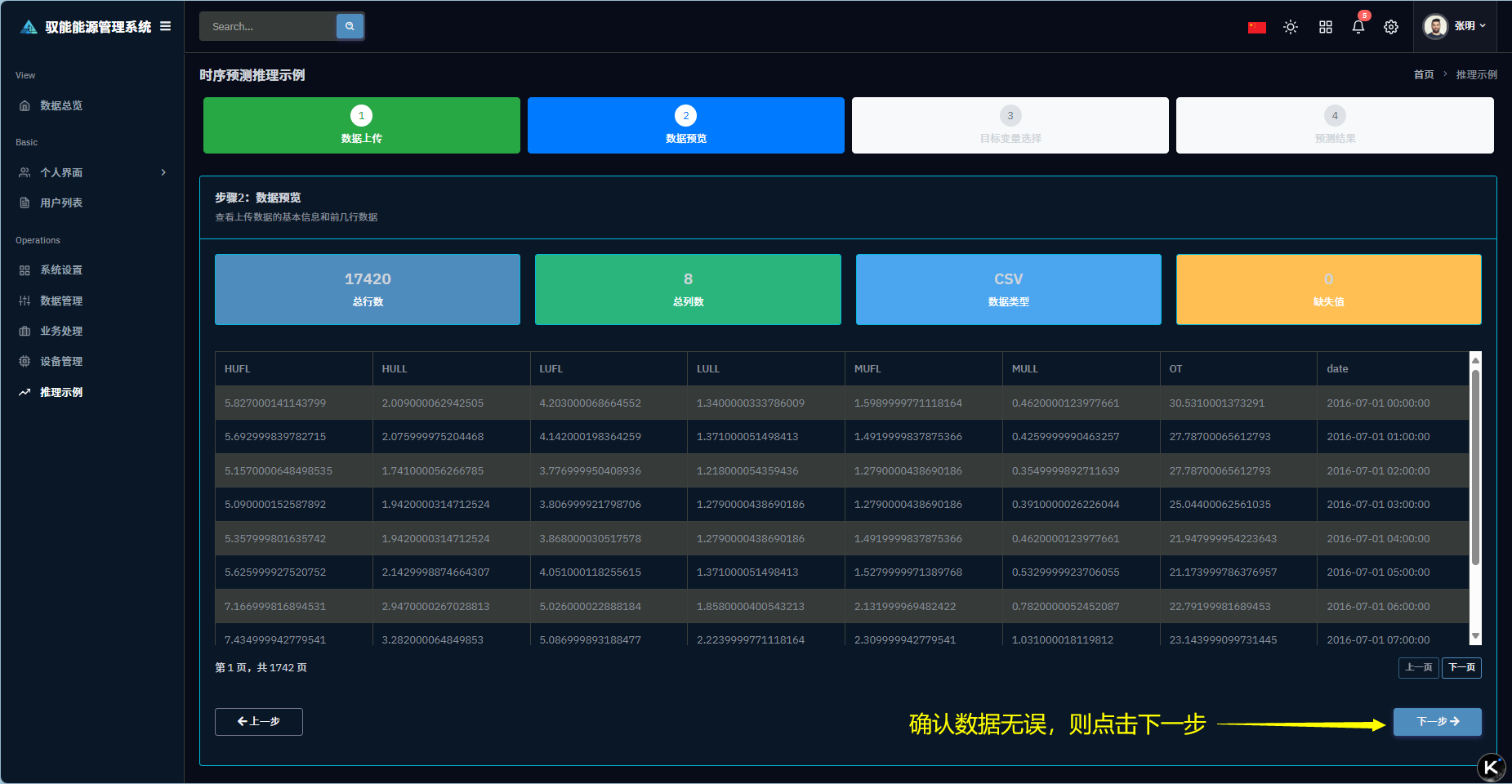
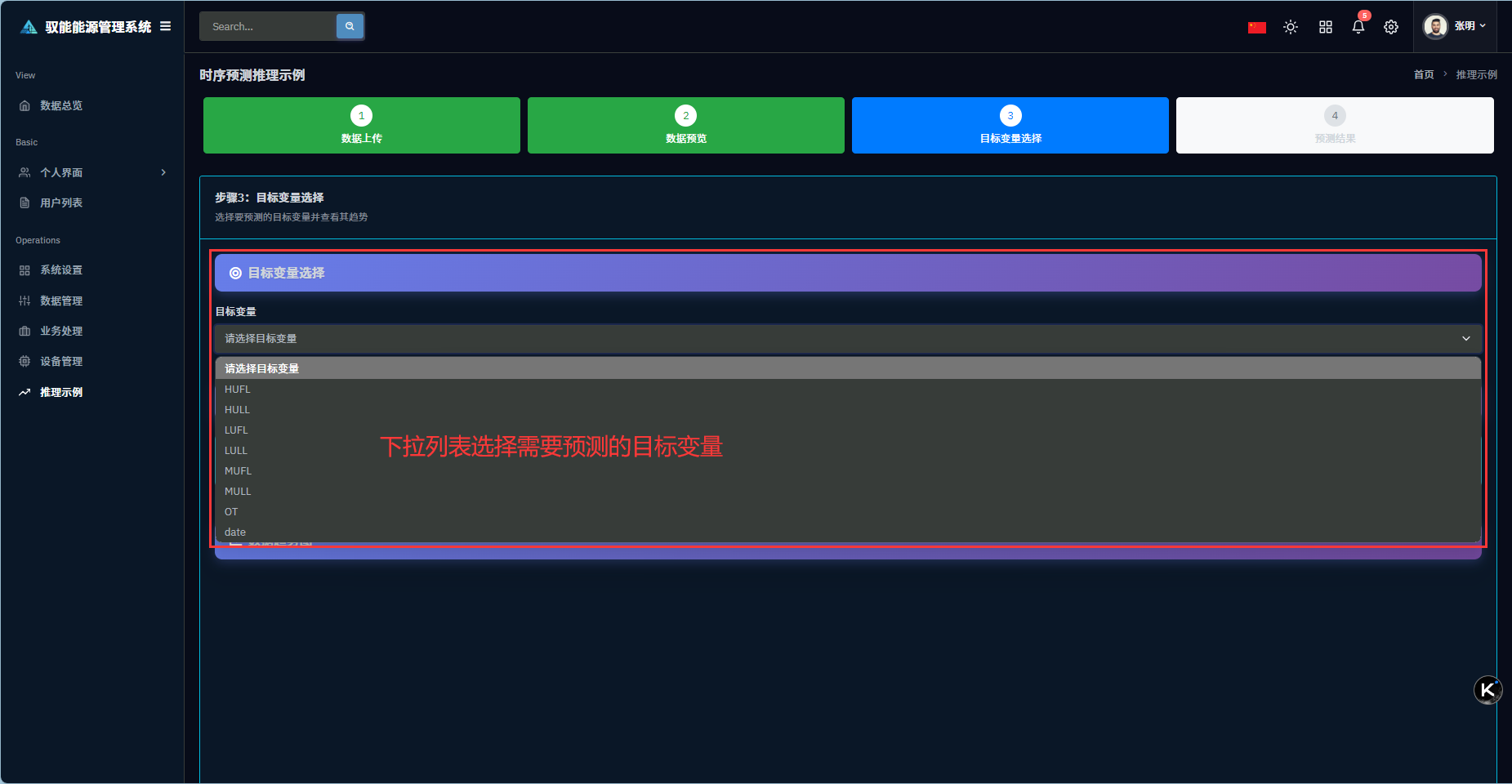
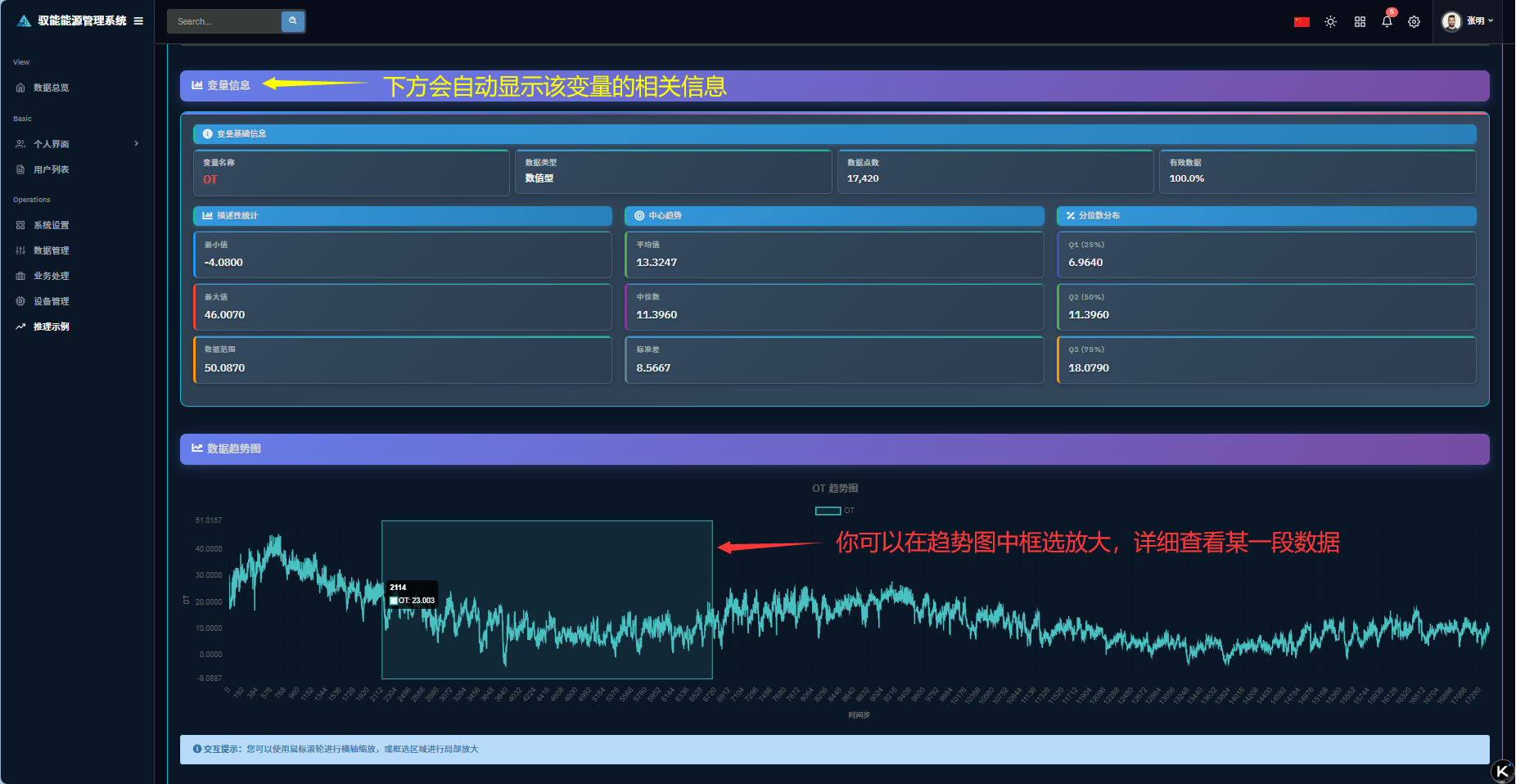
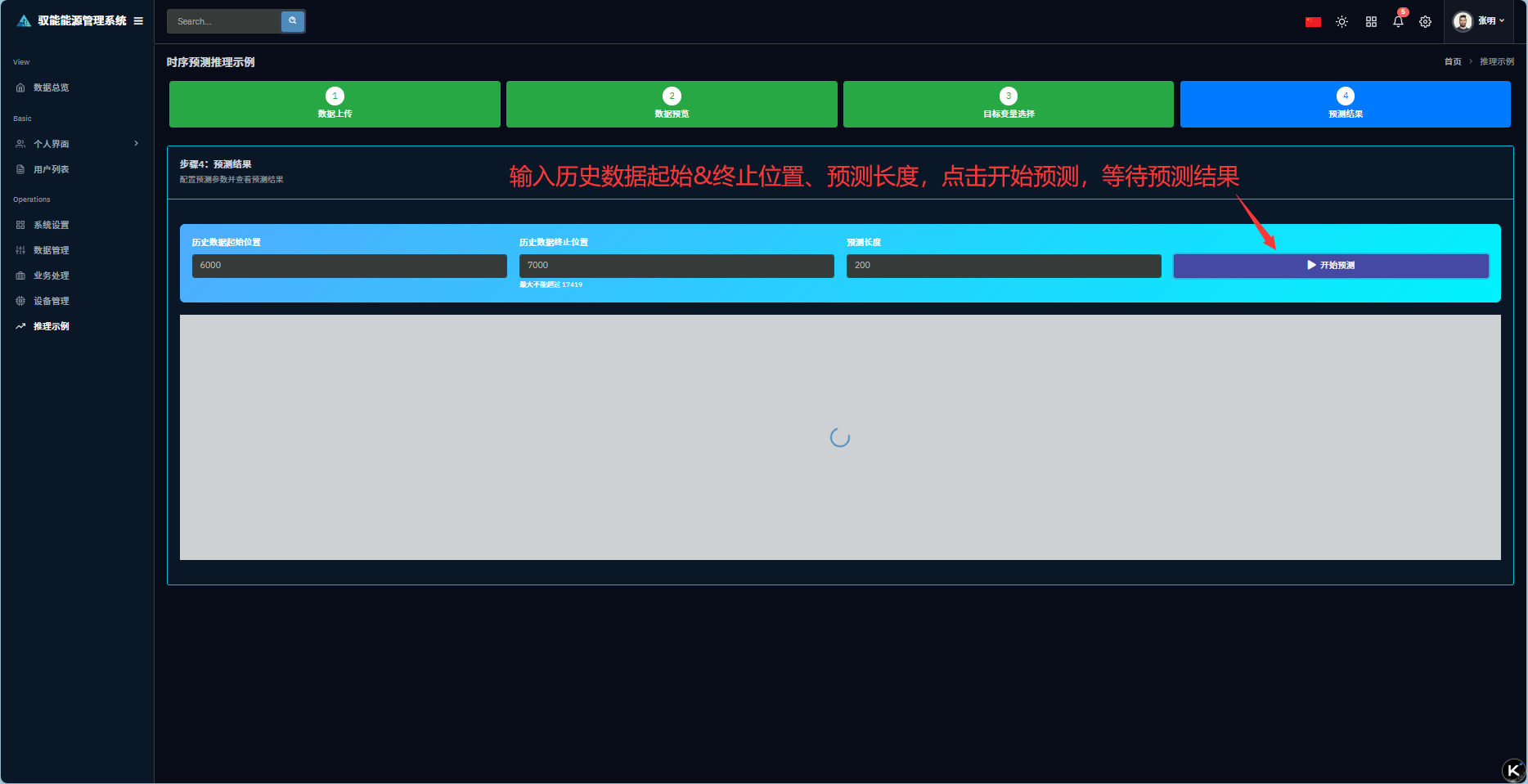
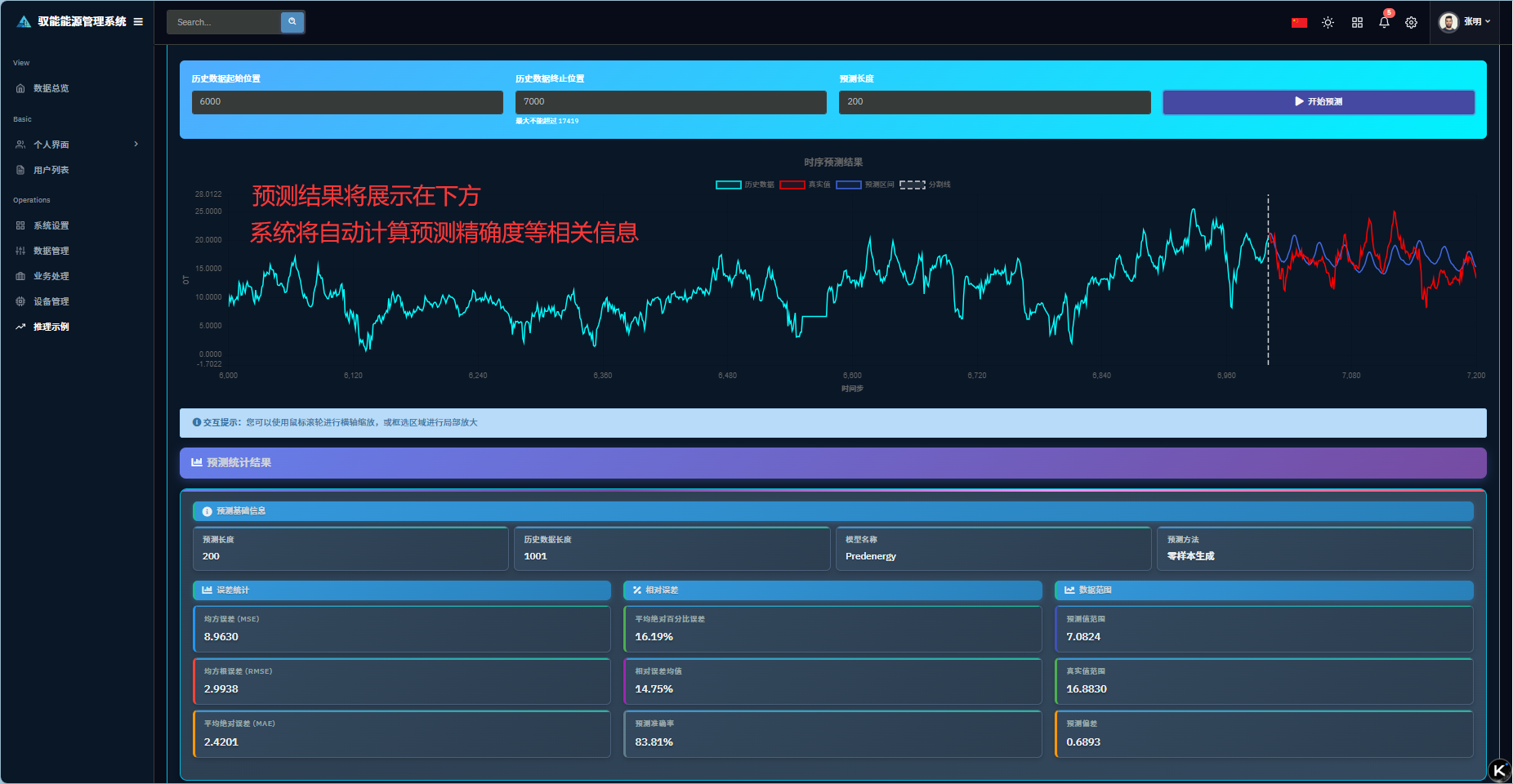
Q1: 第一步遇到问题,示例数据加载失败?
A1: 服务器问题或数据集过大,刷新页面或等待一会儿,多试几次就好了
Q2: 第一步选择到示例数据后网页没有动静,“下一步”依旧是未激活状态?
A2: 服务器问题或数据集过大,推荐多等待一会儿
Q3:页面多次跳到第二步?
A3:操作频繁,有可能连续多次选择到不同变量;服务器反应比较缓慢,在网页没有响应时,please耐心等待
Q4: 第四步点击开始预测,提示没有选择目标变量?
A4:操作频繁导致系统读取变量错误,需回到第三步重新选择变量后,重新进入第四步
/
├─ models/
│ └─ Predenergy/
│ ├─ datasets/ # 数据集与数据加载器(窗口化、通用加载、评估集等)
│ ├─ layers/ # 模型层与注意力模块(STDM、MoTSE、Decoder等)
│ ├─ models/ # Predenergy 主模型、配置与生成逻辑
│ ├─ trainer/ # 训练器与训练参数封装
│ ├─ utils/ # 评估指标、可视化、基准测试、工具函数
│ └─ Predenergy.py # 高级API封装(训练/预测入口)
├─ src/
│ ├─ api_predenergy.py # FastAPI 服务入口
│ └─ webui.py # Gradio Web UI 入口
├─ scripts/ # 训练、推理、评估脚本示例
├─ tests/ # 单元测试与集成测试
├─ configs/ # 配置示例(YAML)
├─ Web/ # 前端静态页面部署
└─ requirements.txt # 依赖列表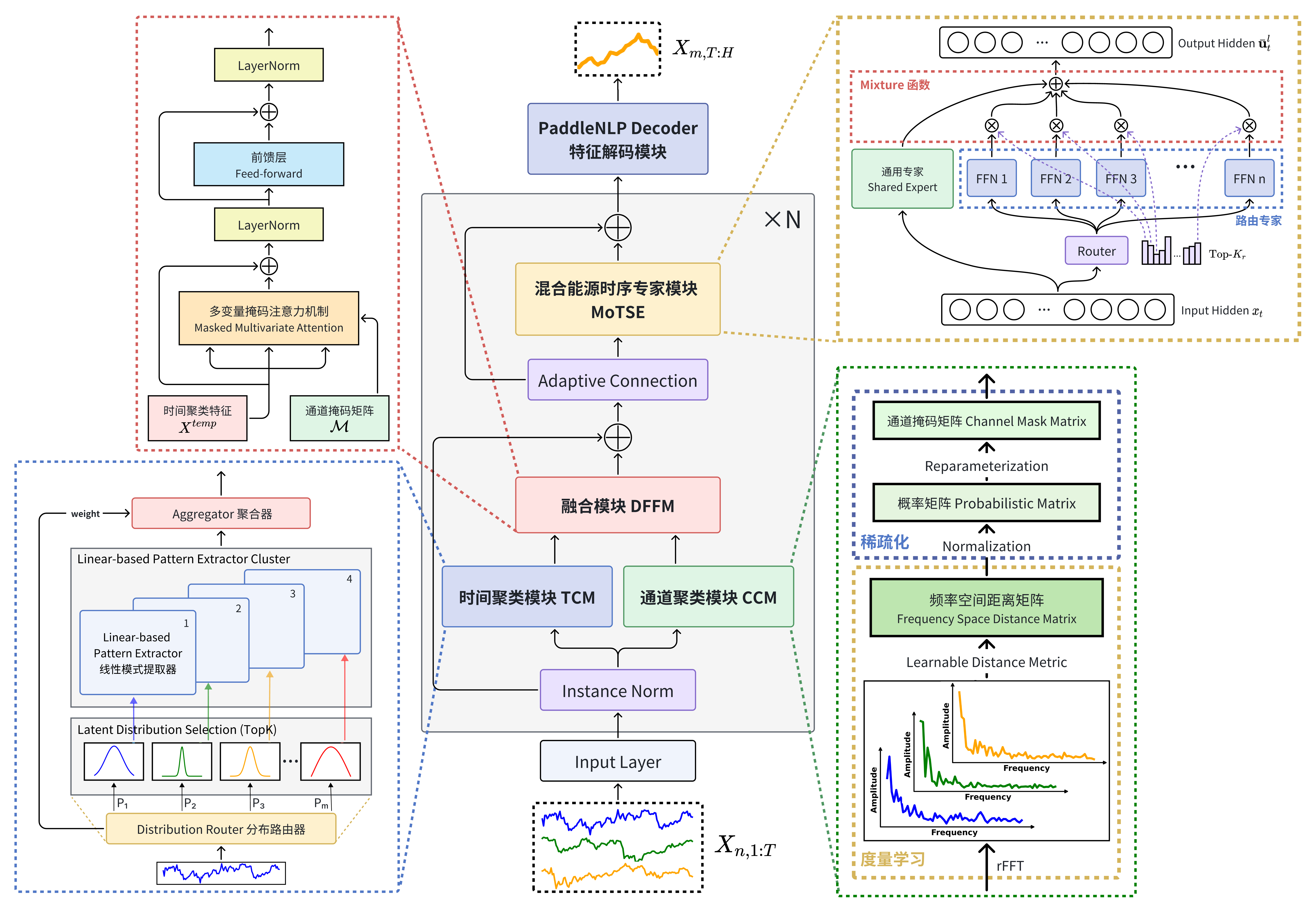
- 模型入口:
models/Predenergy/models/predenergy_model.py - 统一配置:
models/Predenergy/models/unified_config.py - 数据加载:
models/Predenergy/datasets/Predenergy_data_loader.py - 评估与基准:
models/Predenergy/utils/enhanced_metrics.py、models/Predenergy/utils/benchmarking.py - API 服务:
src/api_predenergy.py - Web UI:
src/webui.py - 测试:
tests/test_predenergy_model.py
- Python 3.10+
- PaddlePaddle 3.0.0+
- PaddleNLP 3.0.0+
- CUDA 11.7+
- 建议使用 8GB+ 的 GPU 内存
git clone https://github.com/RXKbill/Predenergy.git
cd Predenergy
%pip install -r requirements.txt
python tests/test_predenergy_model.pydate,value,feature1,feature2
2023-01-01 00:00:00,100.5,1.2,0.8
2023-01-01 01:00:00,98.2,1.1,0.9
2023-01-01 02:00:00,102.1,1.3,0.7
...import pandas as pd
import numpy as np
# 单变量时间序列
data = pd.DataFrame({
'date': pd.date_range('2023-01-01', periods=1000, freq='H'),
'value': np.random.randn(1000)
})
# 多变量时间序列
data = pd.DataFrame({
'date': pd.date_range('2023-01-01', periods=1000, freq='H'),
'feature1': np.random.randn(1000),
'feature2': np.random.randn(1000),
'target': np.random.randn(1000)
})# 形状:[batch_size, sequence_length, features]
data = np.random.randn(1000, 96, 1) # 单变量
data = np.random.randn(1000, 96, 7) # 多变量{
"data": [[1.2, 1.1], [1.3, 1.0], [1.1, 1.2]],
"dates": ["2023-01-01", "2023-01-02", "2023-01-03"],
"horizon": 24,
"config_overrides": {
"seq_len": 96,
"batch_size": 32
}
}
组件 用途 最佳使用场景 PredenergyDataLoader标准数据加载 常规时间序列 PredenergyUniversalDataLoader变长序列加载 不规则数据 PredenergyDataset核心数据集,支持窗口化 自定义处理 BenchmarkEvalDataset评估数据集 模型比较 from models.Predenergy.datasets.Predenergy_data_loader import create_Predenergy_data_loader # 创建数据加载器 data_loader = create_Predenergy_data_loader( data="path/to/data.csv", loader_type='standard', seq_len=96, pred_len=24, batch_size=32, features='M', # 多变量 target='target', # 目标列 freq='h' # 小时数据 ) # 获取数据加载器 train_loader = data_loader.get_train_loader() val_loader = data_loader.get_val_loader() test_loader = data_loader.get_test_loader()
import numpy as np
import pandas as pd
from models.Predenergy.models.unified_config import PredenergyUnifiedConfig
from models.Predenergy.models.predenergy_model import PredenergyForPrediction
# 1. 创建配置
config = PredenergyUnifiedConfig(
seq_len=96, # 输入序列长度
horizon=24, # 预测范围
use_paddlenlp_decoder=True, # 启用高级解码器
num_experts=8, # MoTSE 专家数量
decoder_num_layers=3 # 解码器深度
)
# 2. 初始化模型
model = PredenergyForPrediction(config)
# 3. 准备数据(示例,用随机数替代)
batch_size, seq_len, features = 32, 96, 1
input_data = paddle.randn([batch_size, seq_len, features])
labels = paddle.randn([batch_size, config.horizon, config.c_out])
# 4. 训练步骤
model.train()
outputs = model(input_data, labels=labels)
loss = outputs['loss']
# 5. 推理
model.eval()
with paddle.no_grad():
predictions = model.predict(input_data)
print(f"Predictions shape: {predictions.shape}")评估指标结果包括:
- 基本指标(MSE、MAE、MAPE、R²)
- 高级指标(SMAPE、WAPE、方向准确性)
- 概率指标(CRPS、对数似然)
- 分布指标(KS 检验、Wasserstein 距离)
- 时序指标(自相关性、谱相似性)
# 综合评估
from models.Predenergy.utils.enhanced_metrics import EnhancedForeccastMetrics
evaluation = EnhancedForeccastMetrics.comprehensive_evaluation(
y_true=actual_values,
y_pred=predictions, # 如果可用
sample_weight=None,
freq='H'
)
# 打印详细指标
from models.Predenergy.utils.enhanced_metrics import print_metrics_summary
print_metrics_summary(evaluation, "Predenergy 性能报告")下表根据参数文件 configs/predenergy_config.yaml 对相关参数进行说明
| 类别 | 参数 | 默认值 | 说明 |
|---|---|---|---|
| 核心预测 | seq_len |
96 | 输入序列长度 |
horizon |
24 | 预测步长/范围 | |
label_len |
48 | 解码器标签长度(辅助) | |
input_size |
1 | 输入特征维度(单变量=1,多变量=特征数) | |
c_out |
1 | 输出维度(通常为目标列数) | |
| 模型结构 | d_model |
512 | 隐层表示维度(主干通道数) |
n_heads |
8 | 多头注意力头数 | |
e_layers |
2 | 编码器层数 | |
d_layers |
1 | 解码器层数 | |
d_ff |
2048 | 前馈网络维度 | |
dropout |
0.1 | Dropout 比例 | |
activation |
gelu | 激活函数 | |
| 注意力 | factor |
5 | 注意力稀疏因子/Top-k 相关参数 |
output_attention |
false | 是否输出注意力权重 | |
| 训练 | batch_size |
32 | 批大小 |
learning_rate |
0.001 | 学习率 | |
num_epochs |
100 | 训练轮数上限 | |
patience |
10 | 早停耐心值 | |
loss_function |
huber | 损失函数类型(如 mse/mae/huber) | |
| 数据处理 | features |
S | 特征类型:S=单变量,M=多变量 |
target |
OT | 目标列名 | |
normalize |
2 | 归一化方式(0/1/2…取决于实现) | |
freq |
h | 采样频率(如 h、m、d) | |
embed |
timeF | 时间特征嵌入方式 | |
| 高级选项 | use_layer_norm |
true | 是否使用 LayerNorm |
use_revin |
true | 是否使用 RevIN 归一化 | |
moving_avg |
25 | 移动平均窗口(分解/平滑) | |
| STDM | CI |
true | 通道独立(Channel Independence) |
distil |
true | 是否使用蒸馏/降采样模块 | |
| MoTSE | num_experts |
8 | 专家数(Mixture-of-Experts) |
num_experts_per_tok |
2 | 每个 token 激活的专家数 | |
connection_type |
adaptive | 专家连接方式:linear/attention/concat/adaptive | |
motse_hidden_size |
1024 | MoTSE 隐层维度 | |
motse_num_layers |
6 | MoTSE 层数 | |
motse_num_heads |
16 | MoTSE 注意力头数 | |
motse_intermediate_size |
4096 | MoTSE 前馈中间层维度 | |
router_aux_loss_factor |
0.02 | 路由器辅助损失权重 | |
apply_aux_loss |
true | 是否启用辅助损失 | |
| PaddleNLP Decoder |
use_paddlenlp_decoder |
true | 是否启用 PaddleNLP 解码器 |
decoder_hidden_size |
512 | 解码器隐藏维度 | |
decoder_num_layers |
3 | 解码器层数 | |
decoder_num_heads |
8 | 解码器注意力头数 | |
decoder_dropout |
0.1 | 解码器 Dropout 比例 | |
| 生成 | max_position_embeddings |
2048 | 最大位置编码长度 |
rope_theta |
10000.0 | RoPE 旋转位置编码的 θ 参数 | |
use_cache |
true | 是否使用 KV cache 加速推理 | |
| 设备/性能 | device |
auto | 设备选择:auto/cuda/cpu |
mixed_precision |
true | 是否启用混合精度训练 |


特意选了个呆呆的降落hhh
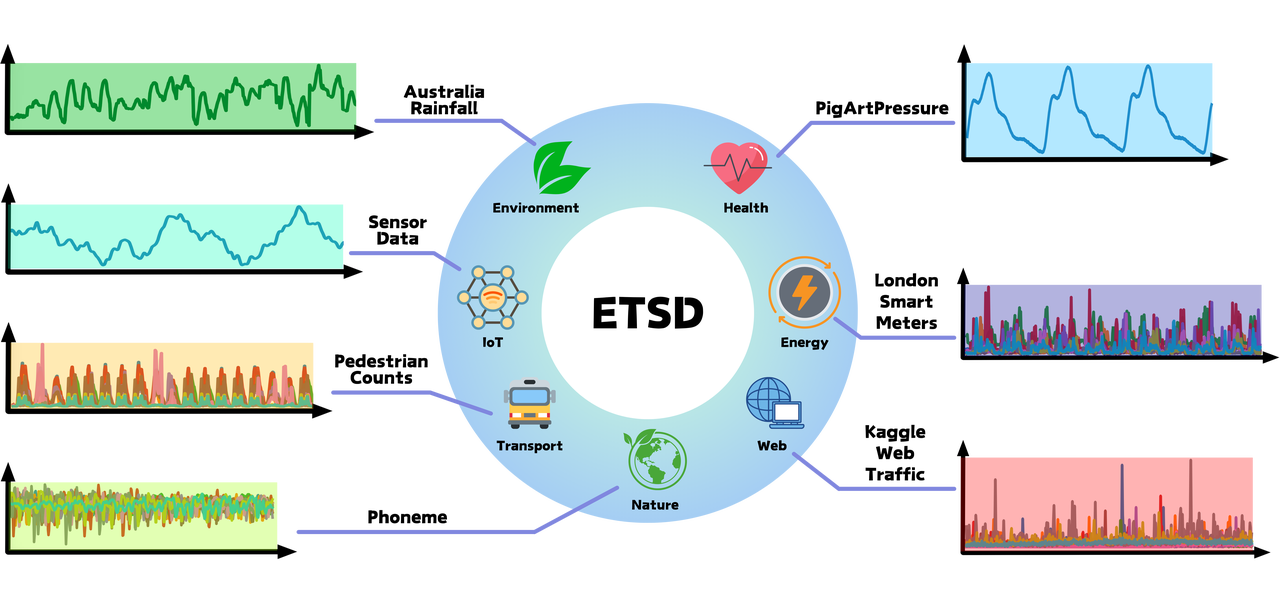
-
TIME POINTS:数据集时间戳数量
-
FILE SIZE:数据集文件大小
-
FREQ.:数据集时间戳采样频率
-
ADF.:数据集平稳性衡量指标,全称增广迪基-福勒检验;其结果值与数据平稳性性成反比关系;具体计算公式如下:其中,
$S_i \in \mathbb{R}^{T_{i}}$ 表示数据集$D$ 中的第$i$ 个序列,$T_i$ 是$S_i$ 的长度,$C$ 是数据集$D$ 中时间序列的数量。
-
FORECAST.:数据可预测性衡量标准,通过从序列的傅里叶分解中减去熵计算;其结果值与数据可预测性成正比关系;具体计算公式如下:其中,
$S_i \in \mathbb{R}^{T_{i}}$ 表示数据集$D$ 中的第$i$ 个序列,$T_i$ 是$S_i$ 的长度,$C$ 是数据集$D$ 中时间序列的数量。
| DOMAIN | DATASET | TIME POINTS | FILE SIZE | FREQ. | ADF. | FORECAST. |
|---|---|---|---|---|---|---|
| ENERGY | ||||||
| LONDON SMART METERS | 166.5M | 636M | HOURLY | -13.158 | 0.173 | |
| WIND FARMS' | 7.40M | 29M | 4 SEC | -29.174 | 0.811 | |
| AUS. ELECTRICITY DEMAND | 1.16M | 5M | 30 MIN | -27.554 | 0.73 | |
| BDG-2 PANTHER | 0.92M | 4M | HOURLY | -6.593 | 0.479 | |
| BDG-2 FoX | 2.32M | 9M | HOURLY | -9.191 | 0.469 | |
| BDG-2 RAT | 4.73M | 19M | HOURLY | -6.868 | 0.456 | |
| BDG-2 BEAR | 1.48M | 6M | HOURLY | -11.742 | 0.471 | |
| LOW CARBON LONDON | 9.54M | 37M | HOURLY | -12.366 | 0.134 | |
| SMART | 0.10M | 1M | HOURLY | -10.755 | 0.143 | |
| IDEAL | 1.26M | 5M | HOURLY | -11.223 | 0.106 | |
| SCEAUX | 0.03M | 1M | HOURLY | -14.172 | 0.143 | |
| BOREALIS | 0.08M | 1M | HOURLY | -6.612 | 0.16 | |
| BUILDINGS900K | 15852.22M | 60102M | HOURLY | -8.412 | 0.357 | |
| Energy Policy Data | 11.34M | 5M | MONTHLY | -12.691 | 0.575 | |
| Smart Grid Data | 3.29M | 14M | 10 MIN | -13.624 | 0.534 | |
| COVID19 ENERGY | 0.03M | 1M | HOURLY | -13.768 | 0.698 | |
| GEF12 | 1.58M | 6M | HOURLY | -9.576 | 0.566 | |
| GEF14 | 0.02M | 1M | HOURLY | -9.372 | 0.628 | |
| GEF17 | 0.28M | 1M | HOURLY | -5.976 | 0.599 | |
| PDB | 0.04M | 1M | HOURLY | -6.453 | 0.622 | |
| SPANISH | 0.07M | 1M | HOURLY | -13.217 | 0.77 | |
| ELF | 0.02M | 1M | HOURLY | -13.607 | 0.77 | |
| Wind Turbine Data | 8.32M | 24M | 10 SEC | -11.325 | 0.632 | |
| Wind Power | 7.40M | 29M | 4 SEC | -28.671 | 0.782 | |
| Solar Power | 7.40M | 29M | 4 SEC | -25.346 | 0.835 | |
| KDD CUP 2022 | 4.73M | 181M | HOURLY | -17.017 | 0.225 | |
| Installed Capacity | 0.28M | 1M | MONTHLY | -6.521 | 0.436 | |
| RESIDENTIAL LOAD POWER | 437.98M | 1671M | MINUTELY | -37.979 | 0.264 | |
| RESIDENTIAL PV POWER | 373.37M | 1435M | MINUTELY | -31.389 | 0.421 | |
| DRONE | 268.43M | 1563M | 10 SEC | -22.791 | 0.236 | |
| ENVIRON- MENT |
||||||
| AUSTRALIARAINFALL | 11.54M | 45M | HOURLY | -150.1 | 0.458 | |
| BEIJINGPM25QUALITY | 3.66M | 14M | HOURLY | -31.415 | 0.404 | |
| BENZENECONCENTRATION | 16.34M | 63M | HOURLY | -65.187 | 0.526 | |
| CHINA AIR QUALITY | 34.29M | 132M | HOURLY | -12.602 | 0.529 | |
| BEIJING AIR QUALITY | 4.62M | 18M | HOURLY | -15.758 | 0.332 | |
| HEALTH | ||||||
| MOTORIMAGERY | 72.58M | 279M | 0.001 SEC | -3.132 | 0.449 | |
| SELFREGULATIONSCP1 | 3.02M | 12M | 0.004 SEC | -3.191 | 0.504 | |
| SELFREGULATIONSCP2 | 3.06M | 12M | 0.004 SEC | -2.715 | 0.481 | |
| ATRIALFIBRILLATION | 0.04M | 1M | 0.008 SEC | -7.061 | 0.167 | |
| PIGARTPRESSURE | 0.62M | 3M | - | -7.649 | 0.739 | |
| PIGCVP* | 0.62M | 3M | - | -4.855 | 0.577 | |
| IEEEPPG | 15.48M | 61M | 0.008 SEC | -7.725 | 0.38 | |
| BIDMC32HR* | 63.59M | 244M | - | -14.135 | 0.523 | |
| TDBRAIN* | 72.30M | 283M | 0.002 SEC | -3.167 | 0.967 | |
| CDC FLUVIEW ILINET | 0.28M | 2M | WEEKLY | -4.381 | 0.307 | |
| CDC FLUVIEW WHO NREVSS | 0.14M | 1M | WEEKLY | -7.928 | 0.233 | |
| PROJECT TYCHO | 1.35M | 5M | WEEKLY | -8.167 | 0.111 | |
| IOT | SENSORDATA" | 165.4M | 631M | 0.02 SEC | -15.892 | 0.917 |
| NATURE | ||||||
| PHONEME" | 2.16M | 9M | - | -8.506 | 0.243 | |
| EIGENWORMS | 27.95M | 107M | - | -12.201 | 0.393 | |
| ERA5 | 96458.81M | 368610M | HOURLY | -7.97 | 0.581 | |
| CMIP6 | 104593.00M | 399069M | 6H | -7.96 | 0.573 | |
| TEMPERATURE RAIN | 23.25M | 93M | DAILY | -10.952 | 0.133 | |
| STARLIGHTCURVES | 9.46M | 37M | - | -1.891 | 0.555 | |
| SAUGEEN RIVER FLOW | 0.02M | 1M | DAILY | -19.305 | 0.3 | |
| KDD CUP 2018* | 2.94M | 12M | HOURLY | -10.107 | 0.362 | |
| US BIRTHS* | 0.00M | 1M | DAILY | -3.352 | 0.675 | |
| SUNSPOT | 0.07M | 1M | DAILY | -7.866 | 0.287 | |
| WORMS | 0.23M | 1M | 0.033 SEC | -3.851 | 0.395 | |
| SUBSEASONAL | 56.79M | 217M | DAILY | -12.391 | 0.414 | |
| SUBSEASONAL PRECIPITATION | 9.76M | 38M | DAILY | -13.567 | 0.276 | |
| TRANS- PORT |
||||||
| PEDESTRIAN COUNTS* | 3.13M | 12M | HOURLY | -23.462 | 0.297 | |
| PEMS 03 | 9.38M | 36M | 5MIN | -19.051 | 0.411 | |
| PEMS 04 | 15.65M | 60M | 5 MIN | -15.192 | 0.494 | |
| PEMS 07 | 24.92M | 96M | 5 MIN | -20.603 | 0.466 | |
| PEMS 08 | 9.11M | 35M | 5 MIN | -14.918 | 0.551 | |
| PEMS BAY | 16.94M | 65M | 5 MIN | -12.77 | 0.704 | |
| LOS-LOOP | 7.09M | 28M | 5 MIN | -16.014 | 0.657 | |
| LOOP SEATTLE | 33.95M | 130M | 5 MIN | -32.209 | 0.535 | |
| SZ-TAXI | 0.46M | 2M | 15 MIN | -5.9 | 0.217 | |
| BEIJING SUBWAY | 0.87M | 22M | 30 MIN | -8.571 | 0.219 | |
| SHMETROY | 5.07M | 20M | 15 MIN | -17.014 | 0.222 | |
| HZMETRO | 0.38M | 2M | 15 MIN | -11.254 | 0.232 | |
| Q-TRAFFIC | 264.39M | 1011M | 15 MIN | -15.761 | 0.49 | |
| TAXI | 55.00M | 212M | 30 MIN | -8.302 | 0.146 | |
| UBER TLC DAILY | 0.05M | 1M | DAILY | -1.778 | 0.285 | |
| UBER TLC HOURLY | 1.13M | 5M | HOURLY | -9.022 | 0.124 | |
| LARGEST | 4452.20M | 16988M | 5 MIN | -38.02 | 0.436 | |
| WEB | ||||||
| WEB TRAFFIC* | 116.49M | 462M | DAILY | -8.272 | 0.299 | |
| WIKI-ROLLING | 40.62M | 157M | DAILY | -5.524 | 0.242 | |
| CLOUDOPS | ||||||
| ALIBABA CLUSTER TRACE | 190.39M | 2909M | 5 MIN | -5.303 | 0.668 | |
| AZURE VM TRACES 2017 | 885.52M | 10140M | 5 MIN | -11.482 | 0.29 | |
| BORG CLUSTER DATA 2011 | 1073.89M | 14362M | 5 MIN | -8.975 | 0.505 | |
| SALES | ||||||
| M5 | 58.33M | 224M | DAILY | -6.985 | 0.247 | |
| FAVORITA SALES | 139.18M | 535M | DAILY | -6.441 | 0.097 | |
| FAVORITA TRANSACTIONS | 0.08M | 1M | DAILY | -5.481 | 0.362 | |
| RESTAURANT | 0.29M | 2M | DAILY | -4.65 | 0.126 | |
| HIERARCHICAL SALES | 0.21M | 1M | DAILY | -8.704 | 0.078 | |
| FINANCE | ||||||
| GODADDY | 0.26M | 2M | MONTHLY | -1.539 | 0.784 | |
| BITCOIN | 0.07M | 1M | DAILY | -2.493 | 0.398 | |
| MISC. | ||||||
| M1 YEARLY | 0.00M | 1M | YEARLY | -0.791 | 0.473 | |
| M1 QUARTERLY | 0.01M | 1M | QUARTERLY | -0.175 | 0.572 | |
| M1 MONTHLY | 0.04M | 1M | MONTHLY | -1.299 | 0.588 | |
| M3 YEARLY | 0.02M | 1M | YEARLY | -0.85 | 0.524 | |
| M3 QUARTERLY | 0.04M | 1M | QUARTERLY | -0.897 | 0.624 | |
| M3 MONTHLY | 0.1M | 1M | MONTHLY | -1.954 | 0.635 | |
| M3 OTHER | 0.01M | 1M | - | -0.568 | 0.801 | |
| M4 YEARLY | 0.84M | 4M | YEARLY | -0.036 | 0.533 | |
| M4 QUARTERLY | 2.214M | 10M | QUARTERLY | -0.745 | 0.696 | |
| M4 MONTHLY | 10.38M | 41M | MONTHLY | -1.358 | 0.665 | |
| M4 WEEKLY | 0.37M | 2M | WEEKLY | -0.533 | 0.644 | |
| M4 DAILY | 9.96M | 39M | DAILY | -1.332 | 0.841 | |
| M4 HOURLY | 0.35M | 2M | HOURLY | -2.073 | 0.532 |
[1] Qiu X, Hu J, Zhou L, et al. Tfb: Towards comprehensive and fair benchmarking of time series forecasting methods[J]. arXiv preprint arXiv:2403.20150, 2024.
[2] Chen P, Zhang Y, Cheng Y, et al. Pathformer: Multi-scale transformers with adaptive pathways for time series forecasting[J]. arXiv preprint arXiv:2402.05956, 2024.
[3] Liu Y, Hu T, Zhang H, et al. itransformer: Inverted transformers are effective for time series forecasting[J]. arXiv preprint arXiv:2310.06625, 2023.
GitHub - thuml/Time-Series-Library: A Library for Advanced Deep Time Series Models.
[4] Nie Y, Nguyen N H, Sinthong P, et al. A time series is worth 64 words: Long-term forecasting with transformers[J]. arXiv preprint arXiv:2211.14730, 2022.
GitHub - PatchTST/PatchTST: An official implementation of PatchTST
[5] Zhang Y, Yan J. Crossformer: Transformer utilizing cross-dimension dependency for multivariate time series forecasting[C]//The eleventh international conference on learning representations. 2023.
[6] Zeng A, Chen M, Zhang L, et al. Are transformers effective for time series forecasting?[C]//Proceedings of the AAAI conference on artificial intelligence. 2023, 37(9): 11121-11128.
GitHub - cure-lab/LTSF-Linear: Official implementation of the paper "Are Transformers..."
[7] Wu H, Hu T, Liu Y, et al. Timesnet: Temporal 2d-variation modeling for general time series analysis[J]. arXiv preprint arXiv:2210.02186, 2022.
[8] Wu R, Keogh E J. Current time series anomaly detection benchmarks are flawed and are creating the illusion of progress[J]. IEEE transactions on knowledge and data engineering, 2021, 35(3): 2421-2429.
[9] Xu J, Wu H, Wang J, et al. Anomaly transformer: Time series anomaly detection with association discrepancy[J]. arXiv preprint arXiv:2110.02642, 2021.
[10] Liu Y, Zhang H, Li C, et al. Timer: Generative pre-trained transformers are large time series models[J]. arXiv preprint arXiv:2402.02368, 2024.
[11] Qiu X, Wu X, Lin Y, et al. Duet: Dual clustering enhanced multivariate time series forecasting[C]//Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 1. 2025: 1185-1196.
GitHub - decisionintelligence/DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting
[12] Shi X, Wang S, Nie Y, et al. Time-moe: Billion-scale time series foundation models with mixture of experts[J]. arXiv preprint arXiv:2409.16040, 2024.
GitHub - Time-MoE/Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts