XGBoost是陈天奇等人开发的一个开源机器学习项目,高效地实现了GBDT算法并进行了算法和工程上的许多改进,被广泛应用在Kaggle竞赛及其他许多机器学习竞赛中并取得了不错的成绩。
说到XGBoost,不得不提GBDT(Gradient Boosting Decision Tree)。因为XGBoost本质上还是一个GBDT,但是力争把速度和效率发挥到极致,所以叫X (Extreme) GBoosted。两者都是boosting方法。
先来举个例子,我们要预测一家人对电子游戏的喜好程度,考虑到年轻和年老相比,年轻更可能喜欢电子游戏,以及男性和女性相比,男性更喜欢电子游戏,故先根据年龄大小区分小孩和大人,然后再通过性别区分开是男是女,逐一给各人在电子游戏喜好程度上打分,如下图所示。

就这样,训练出了2棵树tree1和tree2,类似之前gbdt的原理,两棵树的结论累加起来便是最终的结论,所以小孩的预测分数就是两棵树中小孩所落到的结点的分数相加:2 + 0.9 = 2.9。爷爷的预测分数同理:-1 + (-0.9)= -1.9。具体如下图所示:

恩,你可能要拍案而起了,惊呼,这不是跟之前介绍的GBDT乃异曲同工么?
事实上,如果不考虑工程实现、解决问题上的一些差异,XGBoost与GBDT比较大的不同仅仅在于目标函数的定义。
对于Boosting算法我们知道,是将多个弱分类器的结果结合起来作为最终的结果来进行输出。$f_t(x_i)$为第 t 棵树的输出结果,$\hat{y}_i^{(t)}$是模型当前的输出结果,$y_i$ 是实际的结果。
那么:
$\hat{y}i^{(t)} = \sum\limits{t=1}^t f_{t}(x_i)$
XGBoost的目标函数如下图所示:
$Obj^{(t)} = \sum\limits_{i = 1}^nl(y_i,\hat{y}i) + \sum\limits{i =1}^t\Omega(f_t)$
-
训练损失
$\sum\limits_{i = 1}^nl(y_i,\hat{y}_i)$ -
常见损失函数
-
树的复杂度
$\sum\limits_{i =1}^t\Omega(f_i)$
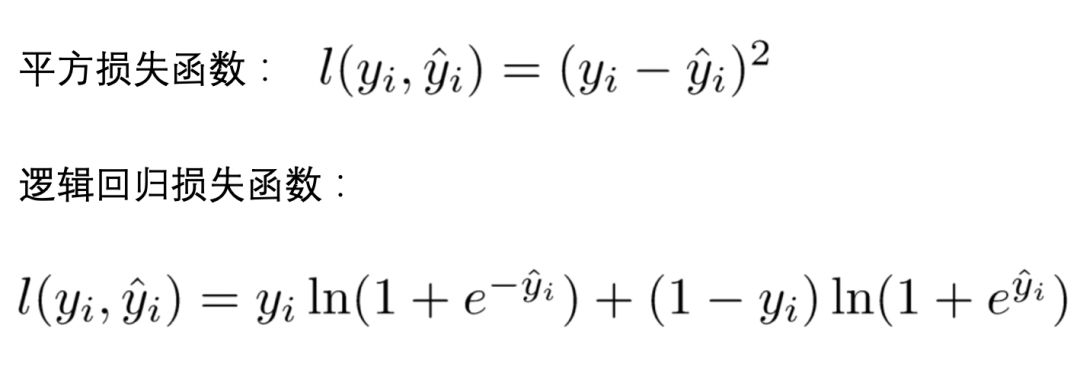
Xgboost包含多棵树,定义每棵树的复杂度:
其中 T 为叶子节点的个数,为叶子节点向量的模 。$\gamma$ 表示节点切分的难度,$\lambda$ 表示L2正则化系数。
$Obj^{(t)} = \sum\limits_{i = 1}^nl(y_i,\hat{y}i^{(t-1)} + f_t(x_i)) + \sum\limits{i =1}^t\Omega(f_i)$
$Obj^{(t)} = \sum\limits_{i=1}^nl(y_i,\hat{y}i^{(t-1)} + f_t{(x_i})) + \Omega(f_t) + \sum\limits{i=1}^{t-1}\Omega(f_i)$
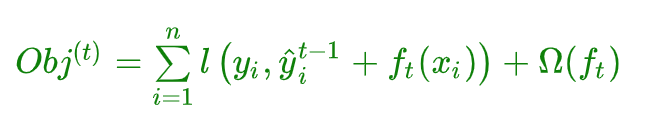
泰勒展开近似目标函数:
令:
则:
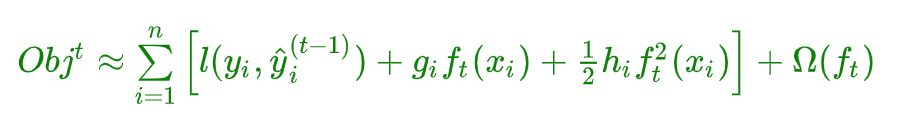
- 方程中的
$l$ 即为损失函数 -
$\Omega(f_t)$ 的是正则项(包括L1正则、L2正则),防止过拟合,鲁棒性加强。 - 对于 f(x),XGBoost利用二阶泰勒展开三项,做一个近似。f(x)表示的是其中一颗回归树。
由于在第
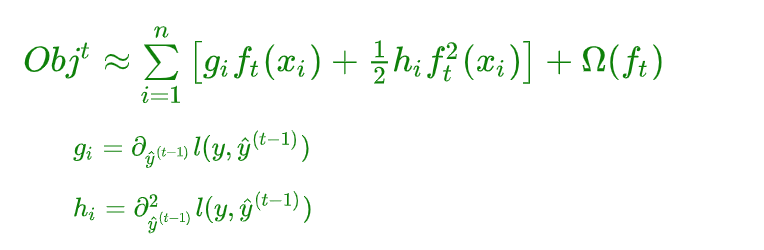
所以我们只需要求出每一步损失函数的一阶导和二阶导的值(由于前一步的
我们重新定义一颗树,包括两个部分:
- 叶子结点的权重向量
$w$ ; - 实例 ---> 叶子结点的映射关系q(本质是树的分支结构);
一棵树的表达形式定义如下:

我们定义一颗树的复杂度
- 叶子结点的数量;
- 叶子结点权重向量的L2范数;
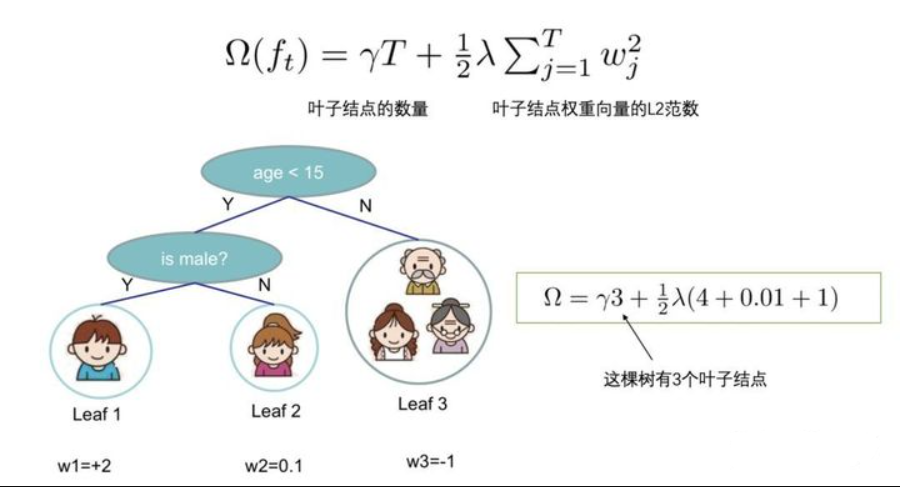
我们将属于第 j 个叶子结点的所有样本 xi , 划入到一个叶子结点样本集中,数学表示如下:
然后,将【3】和【4】中一棵树及其复杂度的定义,带入到【2】中泰勒展开后的目标函数 Obj 中,具体推导如下:
$\begin{aligned}Obj^{(t)} &\approx \sum\limits_{i=1}^n\left[g_if_t(x_i) + \frac{1}{2}h_if^2_t(x_i)\right] + \Omega(f_t)\\ &= \sum\limits_{i=1}^n\left[g_iw_{q(x_i) }+\frac{1}{2}h_iw^2_{q(x_i)}\right] + \gamma T +\frac{1}{2}\lambda\sum\limits_{j = 1}^Tw_j^2\\ &=\sum\limits_{j=1}^T\left[(\sum\limits_{i \in I_j}g_i)w_j + \frac{1}{2}(\sum\limits_{i \in I_j}h_i + \lambda)w_j^2\right] + \gamma T\end{aligned}$
所有的训练样本,按叶子结点进行了分组!
为了进一步简化上式,我们定义:
含义如下:
-
$G_j$ :叶子结点 j 所包含样本的一阶偏导数累加和,是一个常量 -
$H_j$ :叶子结点 j 所包含样本的二阶偏导数累加和,是一个常量
将
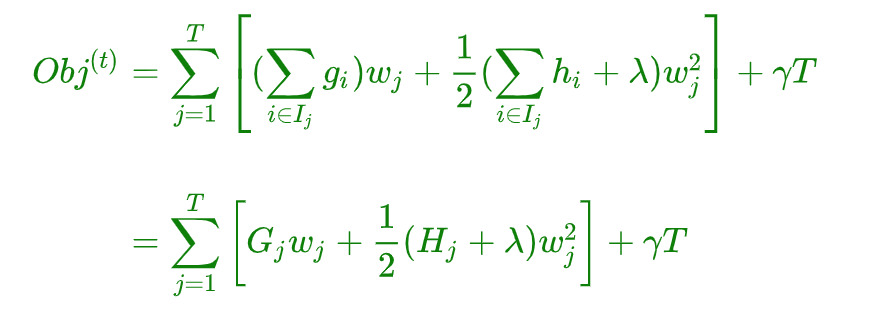
回忆一下高中数学知识。假设有一个一元二次函数,形式如下:
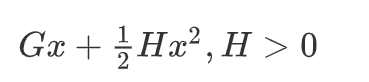
我们可以套用一元二次函数的最值公式轻易地求出最值点:
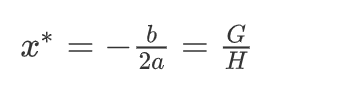
那么回到XGBoost的最终目标函数上
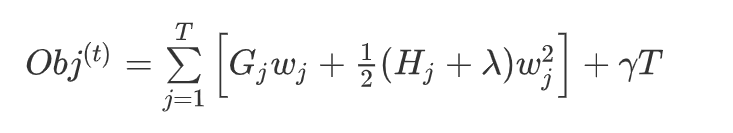
我们先简单分析一下上面的式子:
- 对于每个叶子结点 ,可以将其从目标函数中拆解出来:
在【3.5、叶子结点归组】中我们提到,$G_j$ 和
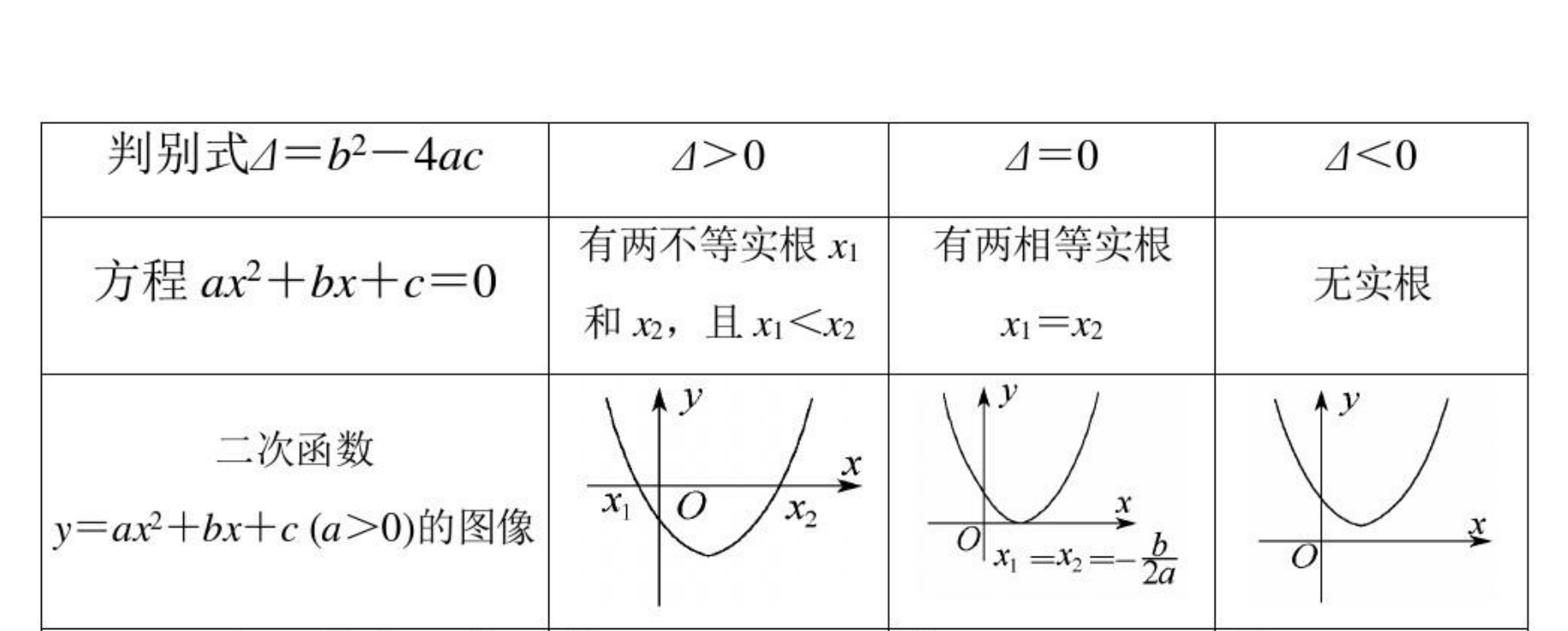
- 两个不同实根:$x_{1,2} = \frac{-b\ \ \pm\ \ \sqrt{\Delta}}{2a} = \frac{-b \ \ \pm \ \ \sqrt{b^2 - 4ac}}{2a}$
- 两个相等实根:$x_{1,2} = -\frac{b}{2a}$
再次分析一下目标函数
那么,假设目前树的结构已经固定,套用一元二次函数的最值公式,将目标函数对
所以目标函数可以化简为:
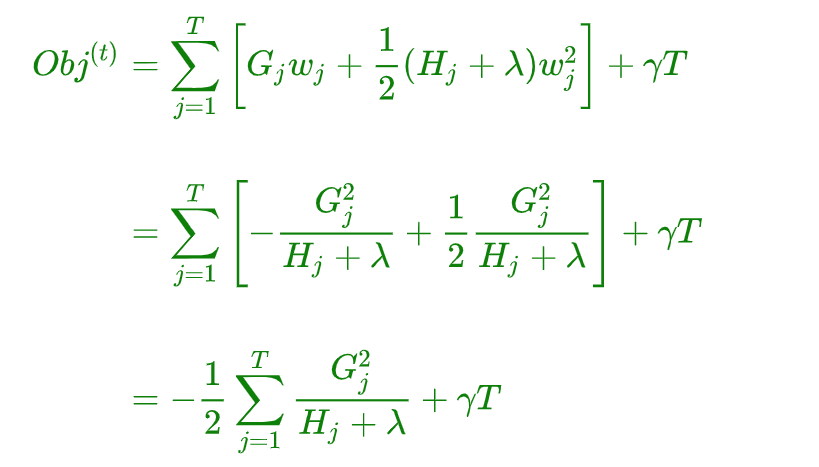
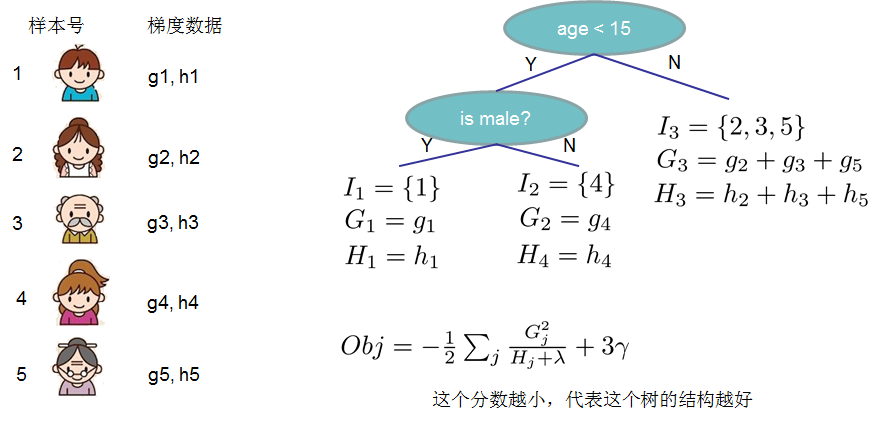
上图给出目标函数计算的例子,求每个节点每个样本的一阶导数
3.7、XGBoost与GBDT差异
import numpy as np
import xgboost as xgb
from xgboost import XGBClassifier
from sklearn import datasets
from sklearn import tree
from sklearn.model_selection import train_test_split
X,y = datasets.load_wine(return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
model = XGBClassifier(learning_rate =0.1,# 学习率,控制每次迭代更新权重时的步长,默认0.3。值越小,训练越慢。
use_label_encoder=False,
n_estimators=10,# 总共迭代的次数,即决策树的个数
max_depth=5, # 深度
min_child_weight=1,# 默认值为1,。值越大,越容易欠拟合;值越小,越容易过拟合
gamma=0,# 惩罚项系数,指定节点分裂所需的最小损失函数下降值。
subsample=0.8,# 训练每棵树时,使用的数据占全部训练集的比例。默认值为1,典型值为0.5-1。防止overfitting。
colsample_bytree=0.8,
objective= 'binary:logistic',# 目标函数
eval_metric = ['merror'],# 验证数据集评判标准
nthread=4,)# 并行线程数
eval_set = [(X_test, y_test),(X_train,y_train)]
model.fit(X_train,y_train,eval_set = eval_set,verbose = True)
model.score(X_test,y_test)X,y = datasets.load_wine(return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
param = {'learning_rate':0.1,'use_label_encoder':True,'n_estimators':10000,
'max_depth':5,'min_child_weight':1,'gamma':0,'subsample':0.8,
'colsample_bytree':0.8, 'verbosity':0,'objective':'multi:softprob'}
model = xgb.XGBClassifier(**param)
model.fit(X_train, y_train, early_stopping_rounds=20, eval_metric='merror',
eval_set=[(X_test, y_test)])DMatrix是XGBoost中使用的数据矩阵。DMatrix是XGBoost使用的内部数据结构,它针对内存效率和训练速度进行了优化
import xgboost as xgb
from sklearn.metrics import accuracy_score
from sklearn import datasets
X,y = datasets.load_wine(return_X_y=True)
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2)
# 创建数据
dtrain = xgb.DMatrix(data = X_train,label = y_train)
dtest = xgb.DMatrix(data = X_test,label = y_test)
# 指定参数
param = {'learning_rate':0.1,'use_label_encoder':False,'max_depth':5,
'min_child_weight':1,'gamma':0,'subsample':0.8,'eval_metric':['merror','mlogloss'],
'colsample_bytree':0.1, 'verbosity':0,'objective':'multi:softmax','num_class':3 }
num_round = 20
evals = [(dtrain,'train'),(dtest,'eval')]
bst = xgb.train(param, dtrain,num_round,evals = evals,)
# 进行预测
y_ = bst.predict(dtest)
display(y_,accuracy_score(y_test,y_))根据用户一些信息,进行算法建模,判断用户是否可以按时进行还款!
字段信息如下:
| 字段 | 说明 |
|---|---|
| Disbursed | 是否还款 |
| Existing_EMI | 每月还款金额 |
| Loan_Amount_Applied | 贷款金额 |
| Loan_Tenure_Applied | 贷款期限 |
| Monthly_Income | 月收入 |
| …… | …… |
import pandas as pd
import numpy as np
import xgboost as xgb
from xgboost import XGBClassifier
from sklearn import model_selection, metrics
from sklearn.model_selection import GridSearchCV
import matplotlib.pylab as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12, 4train = pd.read_csv('train_modified.csv')
test = pd.read_csv('test_modified.csv')
# 删除ID字段,对建模没有实际意义
train.drop(labels = 'ID',axis = 1,inplace = True)
test.drop(labels = 'ID',axis = 1,inplace = True)
# 声明训练数据字段和目标值字段
target = 'Disbursed'
cols = [x for x in train.columns if x not in [target]]def modelfit(model, dtrain, dtest, cols,useTrainCV=True, cv_folds=5, early_stopping_rounds=50):
# 训练数据交叉验证
if useTrainCV:
xgb_param = model.get_xgb_params()
xgb_train = xgb.DMatrix(dtrain[cols].values, label=dtrain[target].values)
xgb_test = xgb.DMatrix(dtest[cols].values)
cvresult = xgb.cv(xgb_param, xgb_train, num_boost_round = model.get_params()['n_estimators'],
nfold=cv_folds,early_stopping_rounds = early_stopping_rounds,
verbose_eval=False)
model.set_params(n_estimators=cvresult.shape[0])
# 建模
model.fit(dtrain[cols], dtrain['Disbursed'],eval_metric='auc')
# 对训练集预测
y_ = model.predict(dtrain[cols])
proba_ = model.predict_proba(dtrain[cols])[:,1] # 获取正样本
# 输出模型的一些结果
print('该模型表现:')
print('准确率 (训练集): %.4g' % metrics.accuracy_score(dtrain['Disbursed'],y_))
print('AUC 得分 (训练集): %f' % metrics.roc_auc_score(dtrain['Disbursed'],proba_))
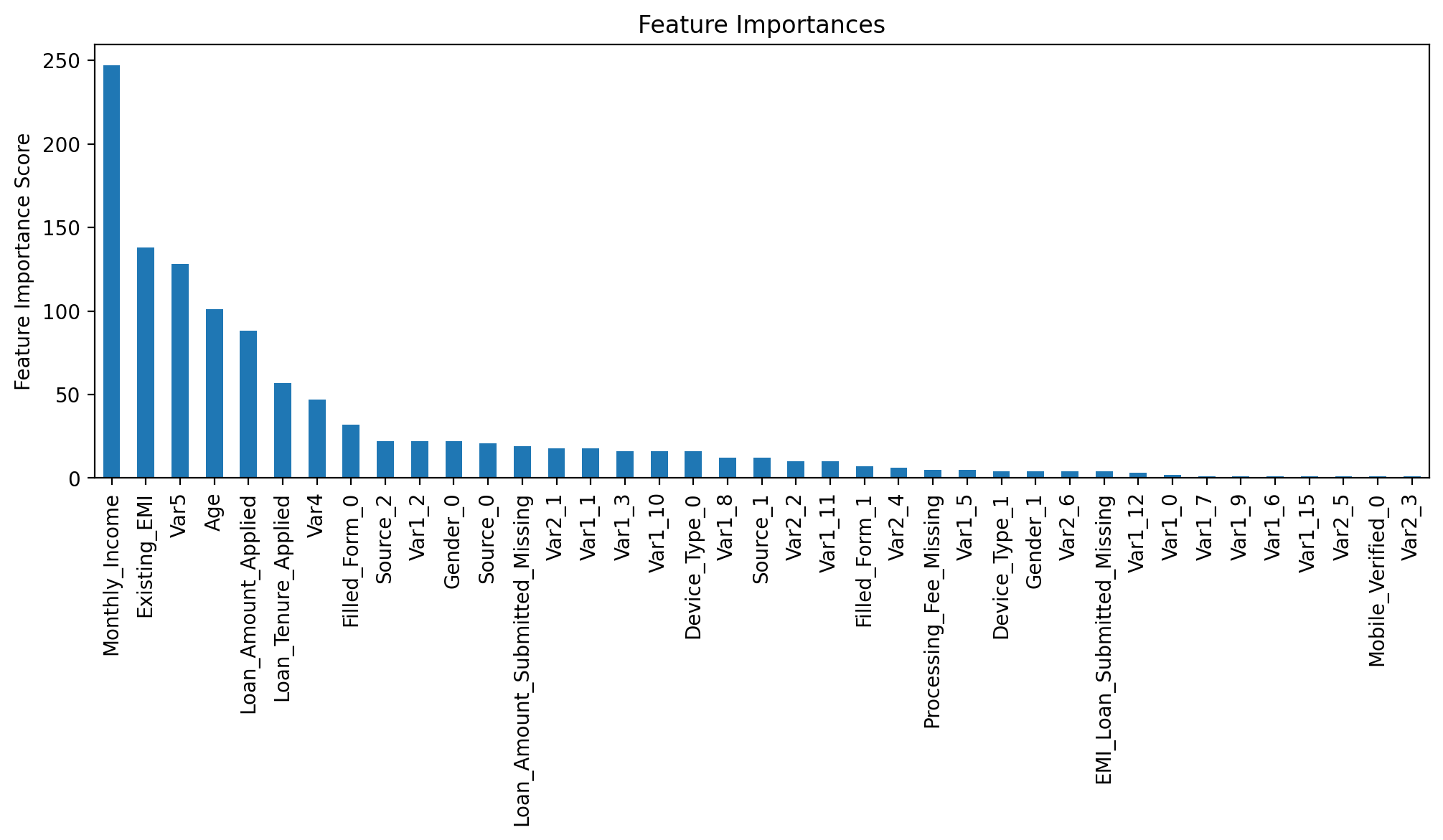
# 特征重要性
feature_imp = pd.Series(model.get_booster().get_fscore()).sort_values(ascending=False)
feature_imp.plot(kind='bar', title='Feature Importances')
plt.ylabel('Feature Importance Score')函数说明:
- 训练数据建模交叉验证
- 根据Xgboost交叉验证更新n_estimators
- 数据建模
- 求训练准确率
- 求训练集AUC二分类ROC-AUC
- 画出特征的重要度
xgb1 = XGBClassifier(learning_rate =0.1,
use_label_encoder=False,
n_estimators=50,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
reg_alpha = 0,
eval_metric=['error','auc'],
verbosity = 0)
modelfit(xgb1, train, test, cols)
'''
该模型表现:
准确率 (训练集): 0.9854
AUC 得分 (训练集): 0.867372
'''
# 对于max_depth和min_child_weight查找最好的参数
param_grid = { 'max_depth':range(3,10,2),'min_child_weight':range(1,6,2)}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,use_label_encoder=False,
min_child_weight=1,gamma=0,subsample=0.8,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,scale_pos_weight=1,seed=27,
verbosity = 0)
gsearch1 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1, cv=5)
gsearch1.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch1.best_params_)
print('最佳得分是:',gsearch1.best_score_)
'''
本次筛选最佳参数: {'max_depth': 5, 'min_child_weight': 3}
最佳得分是: 0.8417229752667561
'''%%time
# 筛选合适的gamma:惩罚项系数,指定节点分裂所需的最小损失函数下降值
param_grid = {'gamma':[i/10.0 for i in range(0,5)]}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,use_label_encoder=False,
min_child_weight=3,gamma=0,subsample=0.8,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,scale_pos_weight=1,seed=27,
verbosity = 0)
gsearch2 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=4, cv=5)
gsearch2.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch2.best_params_)
print('最佳得分是:',gsearch2.best_score_)
'''
本次筛选最佳参数: {'gamma': 0.0}
最佳得分是: 0.8417229752667561
Wall time: 37.9 s
'''%%time
# 对subsample 和 colsample_bytree用grid search寻找最合适的参数
param_grid = {'subsample':[i/10.0 for i in range(6,10)],
'colsample_bytree':[i/10.0 for i in range(6,10)]}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,use_label_encoder=False,
min_child_weight=3,gamma=0,subsample=0.8,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,scale_pos_weight=1,seed=1024,
verbosity = 0)
gsearch3 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1,cv=5)
gsearch3.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch3.best_params_)
print('最佳得分是:',gsearch3.best_score_)
'''
本次筛选最佳参数: {'colsample_bytree': 0.8, 'subsample': 0.8}
最佳得分是: 0.8427440100917339
Wall time: 2min 10s
'''%%time
# 对reg_alpha用grid search寻找最合适的参数
param_grid = {'reg_alpha':[1e-5, 1e-2, 0.1, 1, 100]}
model = XGBClassifier(learning_rate =0.1,n_estimators=100,max_depth=5,use_label_encoder=False,
min_child_weight=3,gamma=0,subsample=0.8,colsample_bytree=0.8,
objective= 'binary:logistic',nthread=4,scale_pos_weight=1,seed=1024,
verbosity = 0)
gsearch4 = GridSearchCV(estimator = model,param_grid = param_grid,
scoring='roc_auc',n_jobs=-1,cv=5)
gsearch4.fit(train[cols],train[target])
print('本次筛选最佳参数:',gsearch4.best_params_)
print('最佳得分是:',gsearch4.best_score_)
'''
本次筛选最佳参数: {'reg_alpha': 1}
最佳得分是: 0.8427616879925267
Wall time: 39.9 s
'''最佳条件是:
max_depth = 5
min_child_weight = 3
gamma = 0
subsample = 0.8
colsample_bytree = 0.8
reg_alpha = 1
xgb2 = XGBClassifier(learning_rate =0.1,
use_label_encoder=False,
n_estimators=100,
max_depth=5,
min_child_weight=3,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha = 1,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
eval_metric=['error','auc'],
verbosity = 0)
modelfit(xgb2, train, test, cols)
'''
该模型表现:
准确率 (训练集): 0.9854
AUC 得分 (训练集): 0.879929
'''调整学习率
xgb3 = XGBClassifier(learning_rate =0.2,
use_label_encoder=False,
n_estimators=100,
max_depth=5,
min_child_weight=3,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha = 1,
objective= 'binary:logistic',
nthread=4,
scale_pos_weight=1,
eval_metric=['error','auc'],
verbosity = 0)
modelfit(xgb3, train, test, cols)
'''
该模型表现:
准确率 (训练集): 0.9855
AUC 得分 (训练集): 0.907529
'''