📖 多言語ドキュメント / Multi-language Documentation:





Warning
This project is currently under active development. Documentation may not reflect the latest changes. If you encounter unexpected behavior, please consider using a previous stable version or report issues on our GitHub repository.
NyaProxy acts like a smart, central manager for accessing various online services (APIs) – think AI tools (like OpenAI, Gemini, Anthropic), image generators, or almost any web service that uses access keys. It helps you use these services more reliably, efficiently, and securely.
Here's how NyaProxy can help:
- Share the Load: Automatically spreads requests across multiple access keys so no single key gets overwhelmed (Load Balancing).
- Stay Online: If one key fails, NyaProxy automatically tries another, keeping your application running smoothly (Failover/Resilience).
- Save Costs: Optimizes how your keys are used, potentially lowering your bills.
- Boost Security: Hides your actual access keys behind the proxy, adding a layer of protection.
- Track Usage: Provides a clear dashboard to see how your keys and services are being used in real-time.
| Feature | Description | Config Reference |
|---|---|---|
| 🔄 Token Rotation | Automatic key cycling across multiple providers | variables.keys |
| ⚖️ Load Balancing | 5 strategies: Round Robin, Random, Least Request, Fastest Response, Weighted | load_balancing_strategy |
| 🚦 Rate Limiting | Granular controls per endpoint/key with smart queuing | rate_limit |
| 🕵️ Request Masking | Dynamic header substitution across multiple identity providers | headers + variables |
| 📊 Real-time Metrics | Interactive dashboard with request analytics and system health | dashboard |
| 🔧 Body Substitution | Dynamic JSON payload transformation using JSONPath | request_body_substitution |
Pick your favorite platform and let's go!

Deploy to Render |

Deploy to Railway |
Note
NyaProxy automatically creates a basic working configuration when it starts. You just need to access the /config endpoint to add your API keys!
Tip
You can use Gemini AI Studio to get a free API key for testing. Gemini's API is OpenAI-compatible and works seamlessly with NyaProxy. Get a Gemini API key here.
- Python 3.10 or higher
- Docker (optional, for containerized deployment)
pip install nya-proxynyaproxy...or provide your own config file:
nyaproxy --config config.yamlVisit http://localhost:8080/config to access the configuration UI.
Important
If you expose this proxy to the internet, make sure to set a strong API key in your configuration to prevent unauthorized access. The first key in your API keys array will be used as the master key for accessing sensitive interfaces like the dashboard and configuration UI, while additional keys can be used for regular API requests only.
If no master API key is specified, no login page will be shown and anyone can access the dashboard and configuration UI. This is convenient for local testing but not recommended for production environments.
Check out http://localhost:8080/dashboard for the snazzy management dashboard with all your API traffic visualizations.
For step-by-step instructions tailored to beginners, check out our detailed deployment guides:
- Docker Deployment Guide - Run with Docker or Docker Compose
- PIP Installation Guide - Direct Python installation
# Clone the repository
git clone https://github.com/Nya-Foundation/nyaproxy.git
cd nyaproxy
# Install dependencies
pip install -e .
# Run NyaProxy
nyaproxydocker run -d \
-p 8080:8080 \
# -v ${PWD}/config.yaml:/app/config.yaml \
# -v ${PWD}/app.log:/app/app.log \
k3scat/nya-proxy:latestConfiguration reference can be found under Configs folder folder
# NyaProxy Configuration File
# This file contains server settings and API endpoint configurations
server:
api_key:
logging:
enabled: true
level: debug
log_file: app.log
proxy:
enabled: false
address: socks5://username:password@proxy.example.com:1080
dashboard:
enabled: true
cors:
# Allow all origins with "*", but specify exact origins when allow_credentials is true for security
allow_origins: ["*"]
allow_credentials: true
allow_methods: ["GET", "POST", "PUT", "DELETE", "OPTIONS"]
allow_headers: ["*"]
# Default configuration applied to all API endpoints unless overridden
default_settings:
key_variable: keys
key_concurrency: true # mark it as true if each key can handle multiple concurrent requests, otherwise the key will be locked until the request completes
randomness: 0.0 # Random delay of (0.0-x)s to introduce variability in request timing and avoid detection due to consistent request patterns due to rate limits
load_balancing_strategy: round_robin
# Path and method filtering
allowed_paths:
enabled: false # Set to true to enable request path filtering
mode: whitelist # if "whitelist", only allow listed paths; if "blacklist", block listed paths
paths:
- "*"
allowed_methods: ["GET", "POST", "PUT", "DELETE", "OPTIONS"] # Allowed HTTP methods for the API
queue:
max_size: 200
max_workers: 10 # Maximum number of concurrent workers for processing requests
expiry_seconds: 300
rate_limit:
enabled: true
endpoint_rate_limit: 10/s # Default endpoint rate limit - can be overridden per API
key_rate_limit: 10/m # Default key rate limit - can be overridden per API
ip_rate_limit: 5000/d # IP-based rate limit to protect against abuse and key redistribution
user_rate_limit: 5000/d # User-based rate limit per proxy API key defined in server section
rate_limit_paths:
- "*"
retry:
enabled: true
mode: key_rotation
attempts: 3
retry_after_seconds: 1
retry_request_methods: [ POST, GET, PUT, DELETE, PATCH, OPTIONS ]
retry_status_codes: [ 429, 500, 502, 503, 504 ]
timeouts:
request_timeout_seconds: 300
apis:
gemini:
# Example for OpenAI-compatible API endpoint
name: Google Gemini API
# Supported endpoints:
# Gemini: https://generativelanguage.googleapis.com/v1beta/openai
# OpenAI: https://api.openai.com/v1
# Anthropic: https://api.anthropic.com/v1
# DeepSeek: https://api.deepseek.com/v1
# Mistral: https://api.mistral.ai/v1
# OpenRouter: https://api.openrouter.ai/v1
# Ollama: http://localhost:11434/v1
endpoint: https://generativelanguage.googleapis.com/v1beta/openai
aliases:
- /gemini
key_variable: keys
headers:
Authorization: 'Bearer ${{keys}}'
variables:
keys:
- your_gemini_key_1
- your_gemini_key_2
- your_gemini_key_3
load_balancing_strategy: least_requests
rate_limit:
enabled: true
# For Gemini-2.5-pro-exp-03-25, rate limits per key are 5 RPM and 25 RPD
# Endpoint rate limit should be n × per-key-RPD, where n is the number of keys
endpoint_rate_limit: 75/d
key_rate_limit: 5/m
# Paths to apply rate limits (regex supported) - defaults to all paths "*"
rate_limit_paths:
- "/chat/*"
- "/images/*"
# Request body substitution settings
request_body_substitution:
enabled: false
# Substitution rules for request body with JMEPath
rules:
# Since Gemini API doesn't support frequency_penalty and presence_penalty, we remove them with these rules
- name: "Remove frequency_penalty"
operation: remove
path: "frequency_penalty"
conditions:
- field: "frequency_penalty"
operator: "exists"
- name: "Remove presence_penalty"
operation: remove
path: "presence_penalty"
conditions:
- field: "presence_penalty"
operator: "exists"
test:
name: Test API
endpoint: http://127.0.0.1:8082
key_variable: keys
randomness: 5
headers:
Authorization: 'Bearer ${{keys}}'
User-Agent: ${{agents}} # flexible headers customization with template variables supported
variables:
keys:
- your_test_key_1
- your_test_key_2
- your_test_key_3
agents:
- test_agent_1
- test_agent_2
- test_agent_3
load_balancing_strategy: least_requests
rate_limit:
enabled: true
endpoint_rate_limit: 20/m
key_rate_limit: 5/m
ip_rate_limit: 5000/d
user_rate_limit: 5000/d
rate_limit_paths:
- "/v1/*"
# feel free to add more APIs here, just follow the same structure as above| Service | Endpoint | Description |
|---|---|---|
| API Proxy | http://localhost:8080/api/<endpoint_name> |
Main proxy endpoint for API requests |
| Dashboard | http://localhost:8080/dashboard |
Real-time metrics and monitoring |
| Config UI | http://localhost:8080/config |
Visual configuration interface |
Note
Replace 8080 and localhost with your configured port and host setting if different
gemini:
name: Google Gemini API
endpoint: https://generativelanguage.googleapis.com/v1beta/openai
aliases:
- /gemini
key_variable: keys
headers:
Authorization: 'Bearer ${{keys}}'
variables:
keys:
- your_gemini_key_1
- your_gemini_key_2
load_balancing_strategy: least_requests
rate_limit:
endpoint_rate_limit: 75/d # Total endpoint limit
key_rate_limit: 5/m # Per-key limit
rate_limit_paths:
- "/chat/*" # Apply limits to specific paths
- "/images/*"novelai:
name: NovelAI API
endpoint: https://image.novelai.net
aliases:
- /novelai
key_variable: tokens
headers:
Authorization: 'Bearer ${{tokens}}'
variables:
tokens:
- your_novelai_token_1
- your_novelai_token_2
load_balancing_strategy: round_robin
rate_limit:
endpoint_rate_limit: 10/s
key_rate_limit: 2/sNyaProxy supports using multiple API keys for authentication:
server:
api_key:
- your_master_key_for_admin_access
- another_api_key_for_proxy_only
- yet_another_api_key_for_proxy_onlyTip
The first key in the list acts as the master key with full access to the dashboard and configuration UI. Additional keys can only be used for API proxy requests. This enables you to share limited access with different teams or services.
Caution
When sharing your NyaProxy instance, never share your master key. Instead, create additional keys for different users or applications.
NyaProxy provides comprehensive rate limiting at multiple levels to protect your APIs and ensure fair usage:
Multi-Level Rate Limiting:
- Endpoint Rate Limit: Controls total requests across all keys for an API endpoint
- Key Rate Limit: Limits requests per individual API key to respect provider restrictions
- IP Rate Limit: Prevents abuse by limiting requests per client IP address
- User Rate Limit: Controls usage per NyaProxy API key for multi-tenant scenarios
Flexible Rate Limit Formats:
- Per second:
1/15s(1 requests per 15 second) - Per minute:
5/m(5 requests per minute) - Per hour:
100/h(100 requests per hour) - Per day:
1000/d(1000 requests per day)
Path-Specific Limiting: Apply rate limits only to specific endpoints using regex patterns:
rate_limit_paths:
- "/chat/*" # Only limit chat endpoints
- "/images/*" # Only limit image generation
- "/v1/models" # Limit specific endpointNyaProxy's powerful templating system allows you to create dynamic headers with variable substitution:
apis:
my_api:
headers:
Authorization: 'Bearer ${{keys}}'
X-Custom-Header: '${{custom_variables}}'
variables:
keys:
- key1
- key2
custom_variables:
- value1
- value2Note
Variables in headers are automatically substituted with values from your variables list, following your configured load balancing strategy.
Use cases include:
- Rotating between different authentication tokens
- Cycling through user agents to avoid detection
- Alternating between different account identifiers
Dynamically transform JSON payloads using JMESPath expressions to add, replace, or remove fields:
request_body_substitution:
enabled: true
rules:
- name: "Default to GPT-4"
operation: set
path: "model"
value: "gpt-4"
conditions:
- field: "model"
operator: "exists"For detailed configuration options and examples, see the Request Body Substitution Guide.
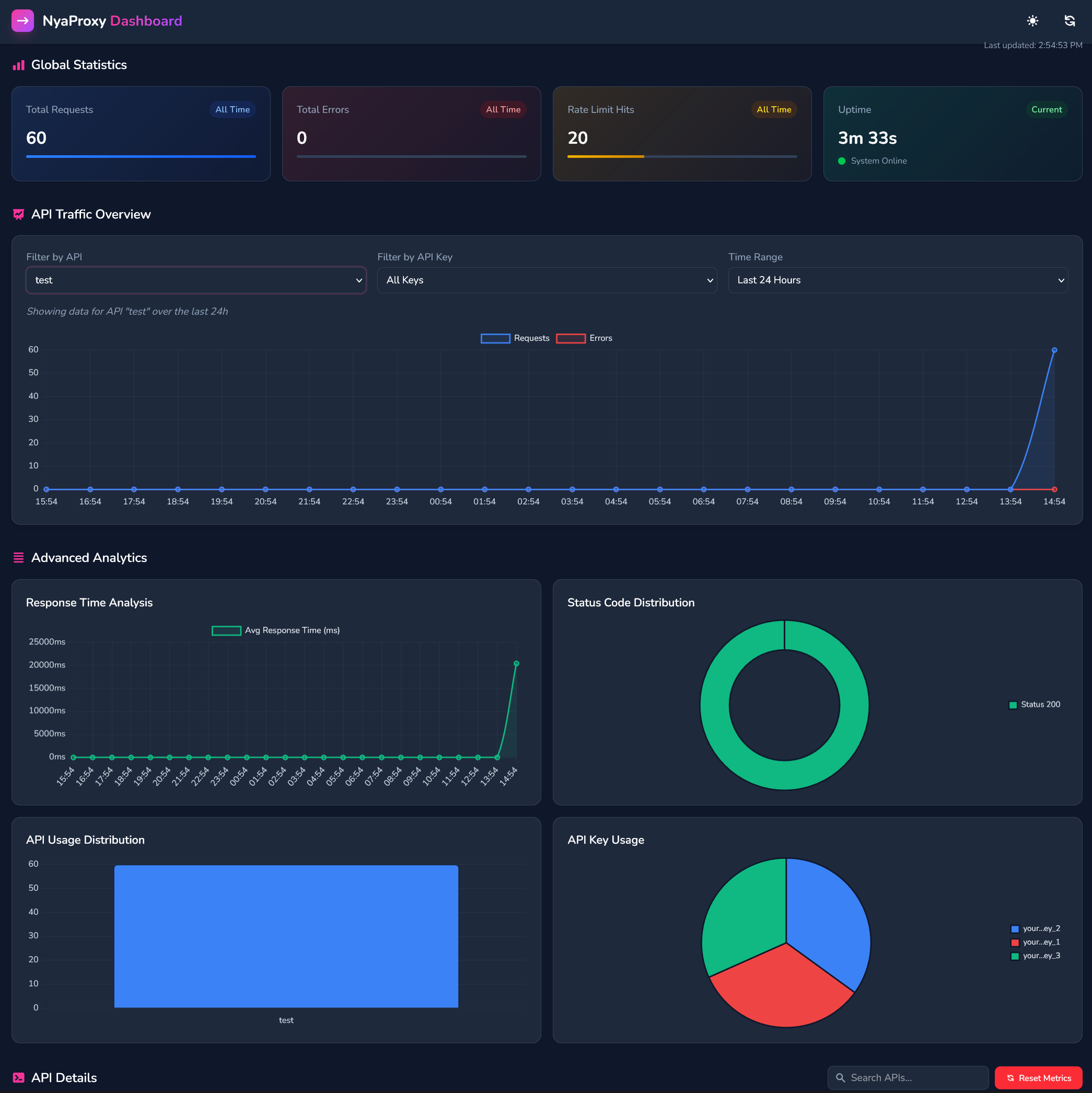
Monitor at http://localhost:8080/dashboard:
- Request volumes and response times
- Rate limit status and queue depth
- Key usage and performance metrics
- Error rates and status codes
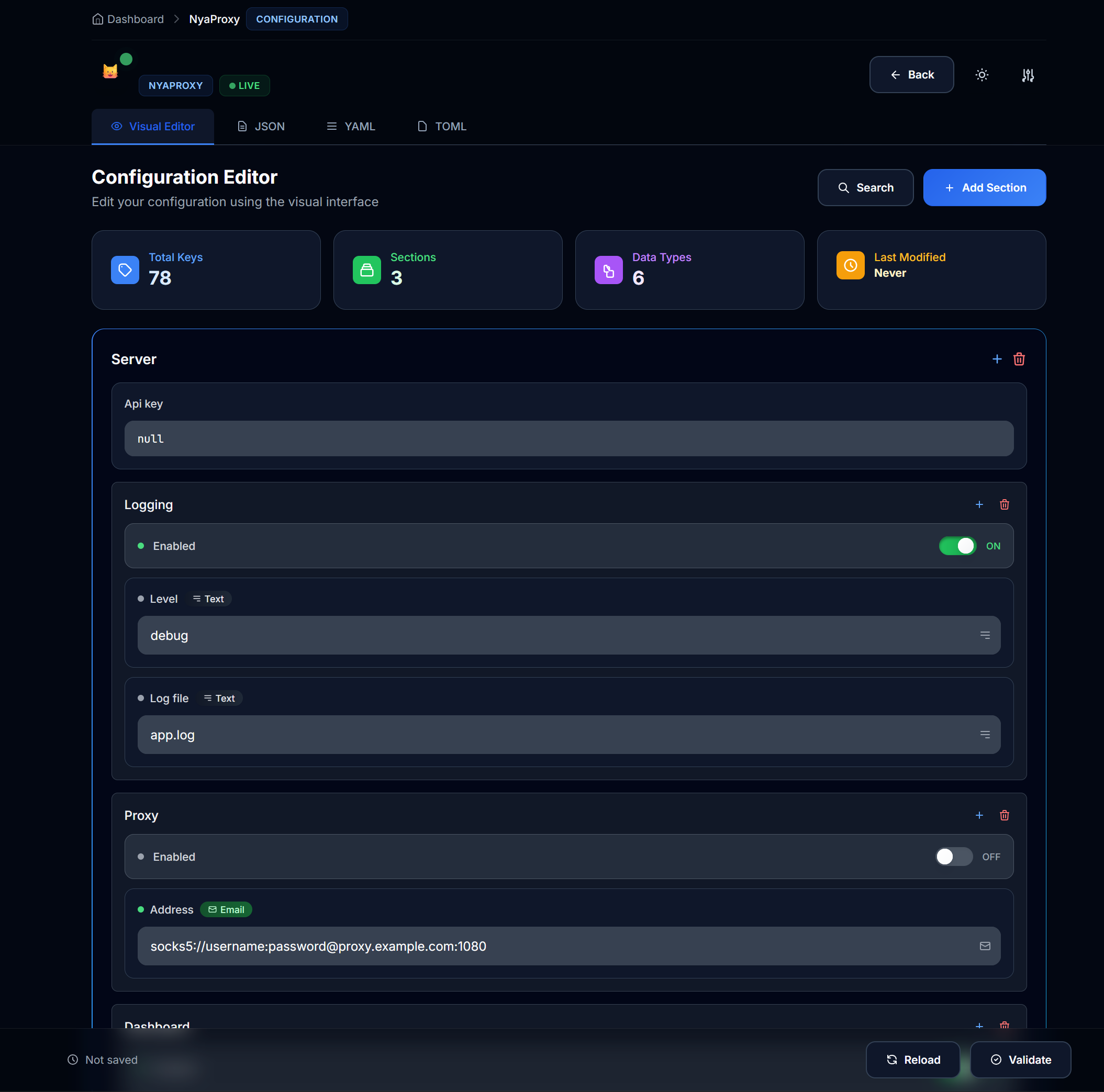
Manage at http://localhost:8080/config:
- Live configuration editing
- Syntax validation
- Variable management
- Rate limit adjustments
- Auto reload on save

Note
Need support? Contact k3scat@gmail.com or join our discord community at Nya Foundation