Important to note.
When runing the prediction directly it is 0.1% more accurate than running it as a deployable microservice. As is run from the link above.
The way that this original repository was organized was to provide a easy to deploy service
that utilizes best practices at the cost of 0.1% accuracy (negligible in logistic regression tasks), which was later refactored so users could run the project
directly on Streamlit without needing to set it up specifically, as Streamlit does not allow Dockerized environments and microservices.
The loss of precision occurs in the main repo due to JSON serialization when a POST request is made to the service, which does not occur in the Streamlit app
as everything is dirict and in one file.
Even though the difference is negligible it was worth to point out so there is no confusion why the same settings in two projectsgive slightly differing results.
The dataset is from Kaggle called Employee Turnover, which was cleaned and visualized.
Quote from the description page.
This database is from a large US company (no name given for privacy reasons). The management department is worried about the relatively high turnover. They want to find ways to reduce the number of employees leaving the company and to better understand the situation, which employees are more likely to leave, and why.
The HR department has assembled data on almost 10,000 employees who left the company between 2016-2020. They used information from exit interviews, performance reviews, and employee records.
| No | Feature | Description |
|---|---|---|
| 1 | department |
the department the employee belongs to. |
| 2 | promoted |
1 if the employee was promoted in the previous 24 months, 0 otherwise. |
| 3 | review |
the composite score the employee received in their last evaluation. |
| 4 | projects |
how many projects the employee is involved in. |
| 5 | salary |
for confidentiality reasons, salary comes in three tiers: low, medium, high. |
| 6 | tenure |
how many years the employee has been at the company. |
| 7 | satisfaction |
The customer’s occupation. |
| 8 | bonus |
1 if the employee received a bonus in the previous 24 months, 0 otherwise. |
| 9 | avg_hrs_month |
the average hours the employee worked in a month. |
| 10 | left |
"yes" if the employee ended up leaving, "no" otherwise. |
The data was first loaded into a Jupyter notebook 1. Data preparation and data cleaning for data processing and cleanup. The most important step of this stage was turning the target variable into a binary format from a string.
Next step was running the notebook 2. EDA, feature importance analysis. In this notebooks certain visualizations were made to get a feel for the data to be worked with as well as feature importance analysis in form of viewing the correlations of features with each other as well as seing if any particular feature stood out.
Finally a notebook 3. Model selection process is ran to test the dummy models before they are converted to a script in form of a train.py.
The script train.py incorporates the tested model and creates a model from vectorized data using Linear Regression from scikit-learn which is then tested for accuracy using the AUC (area under the curve) method. The model is then pickled.
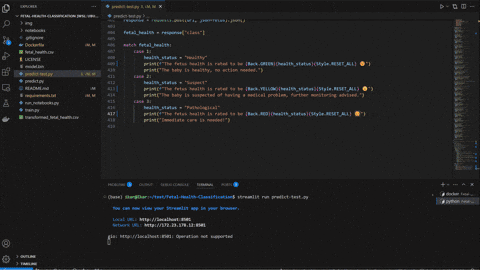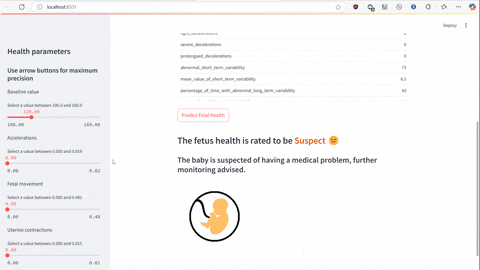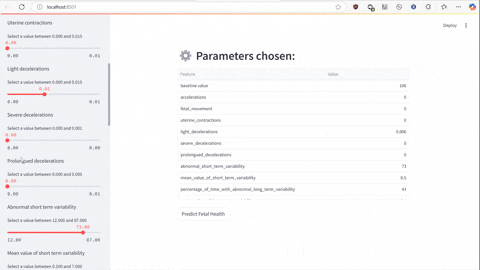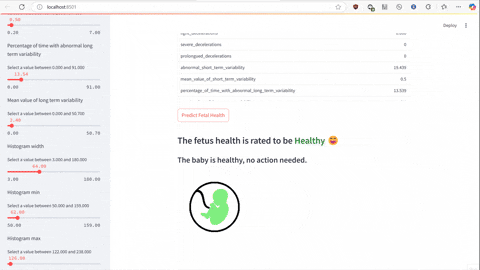
The script predict.py uses Flask and gunicorn to serve the model on local host network to which predict-test.py sends a POST request using JSON serialized data to make the prediction to determine will the employee with specified characteristics churn or not.
Important!
This project was developed on WSL (Windows subsystem for Linux).
It is recommended if on Windows to install it using a guide or running it on UNIX/Linux environment.
You will also need Docker.
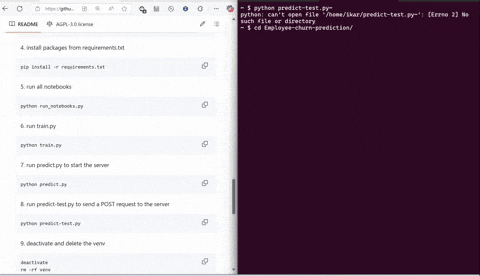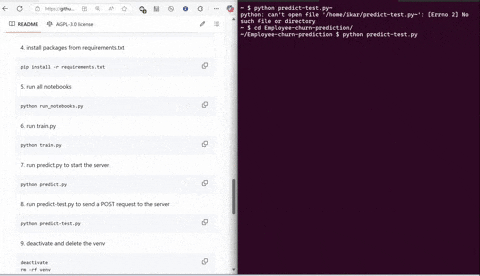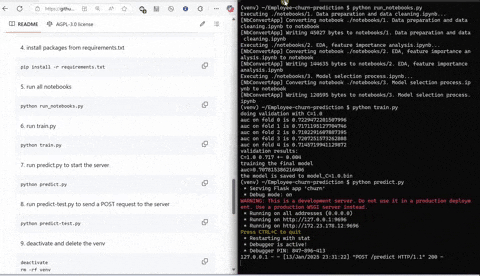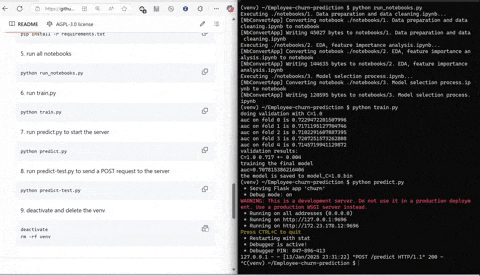
- cd into your desired folder and download the project
git clone https://github.com/MortalWombat-repo/Employee-churn-prediction.git
- cd into the folder
cd Employee-churn-prediction
- build docker container
docker build -t employee_churn .
- run the container with the exposed port (very important, don't forget the p flag)
docker run -p 9696:9696 employee_churn
- open a new terminal tab and send a post request
python predict-test.py
-
when done return to the window with the server and CTRL/Command + C to stop the server
-
exit the directory and delete the project
cd ..
rm -rf Employee-churn-prediction