
Explore the world of Databases! Get started with quick access to all major sections below. ✨
- What is a Database
- Database Essentials
- Database Design
- Relational Schema
- SQL
- Leet Code Questions
- a database is an organized collection of data so that it can be easily accessed.
- To manage these databases , Databases Mangment System (DBMS) are used
- non-relational (DBMS): file , json , xml...
- relational (RDBMS): mysql , sql-server Oracle...
-
the dealing with normal files(DBMS) is so hard compared with databases(RDBMS).
-
row = entity = record
-
column = field = attribute = feature
-
table = Entity set
# Data vs Information
- A data is raw facts
- information is data in context(insigts from this data)
- Data + Meaning = Information
- data is unstructured , info is structered
- data is unanalized m info is analyzed
# Wisdom vs Knowledge
- information with time = knowledge
- knowledge with practice (applied) = wisdom
- null = nothing ( has no value , missing)
- null != 0 or blank space
- it's distinct value in database
- if the attribute is optional is set to null
-
a primary key is a unique identifier for a record(row) , each primary key in each row must be unique (something such as ID column in database is considerd a primary key) , it must not be null , the primary key could be 2 attributes , but it will be slow in searching (so to be more practical consider thinking in 1 attribute to be a primary key) , the VARCHAR datatype couldn't be a primary key (it must be INT) as it will slow down the database seach operations , it will take a large space , each table in the RDB must have a primary key , it's value can't be change
-
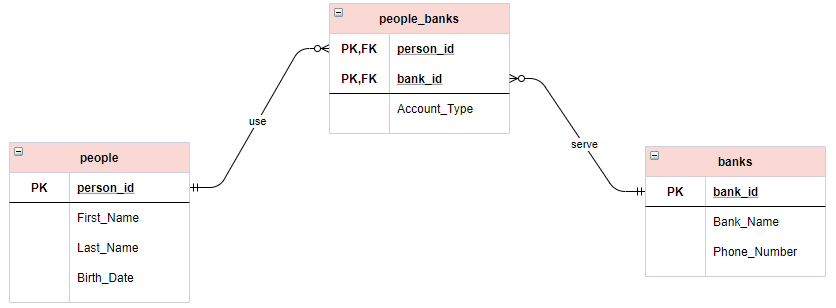
Foreign key ... it's a column or set of columns that refere to a primary key in other table , it establishes a relationship between two tables , allowing data to be shared and linked between them.
-
The foriegn key ensures that referential integrity is maintained by ensuring that any value in the foreign key column must exist in the primary key column of the related table.
-
imagine you have a table with the following attributes , ID , Name , Department Id and another table with the attributes Id , Name , Location .... the first table relates to the second table as the Department id in the first table is referencing to the id in the second table .... imagine a situation when you set a department id that doesn't exist in the second table ... this will cause an exception saying that this
foreign keydoesn't refere to that wrong primary key in the second table , so the data integrity is a concept ensures that thereferential integrityis satisfied (each foreign key must refer to a primary key) , and that the difference between file systems and DBMS.
- Deleting any record with the primary key in the second table the is refered by a foriegn key in the first table , so any record with the foreign key refered to the primary key that have been deleted in the second table .. it will be removed (and that's a big problem)
- Redundancy of data is the presence od duplicayed copies of data within the database.
-it can also cause problems. For example, redundant data takes up additional storage space and can make it more difficult to maintain consistency within the database. If one copy of the data is updated, the other copies may become outdated, leading to inconsistencies and errors.
-
Redundancy can occur through several ways ... the inconsistent(bad) design of database , insertion of multiple copies of data , storing information that can be derived from other data in the database (good redundancy) ...if you want to make a company database with different department and each department has a number of employees you count the number of emps in the run time of application "using SELECT" statment , or you can create a column contains the number of emps in that department, this will be faster , that's why this is considered as good redundancy.
-
To avoid redundancy in DBs , [Normalization] techniques can be used to organize the data in a way that minimizes duplication.
-
Normalization is the process of organizing data in a database in a way that reduces redundancy and improves integrity , This involves breaking down the data into smaller , more atomic pieces and linking them together through relationships , which can reduce the amount of redundant data and make it easier ti manage and update the database , Additionally enforcing [data_constrains] such as unique keys and foreign key relationships , can help prevent redundant data from being insetrted into the database.
-
Data integrity refers to the accurace , consistency and reliability of data over the entire life cycle , from the creation to deletion, it referse to the assurance that data is complete , accurate , and trustworthy.
-
there are several factors that can impact data integrity , including human errors , hardware or software failure , security breaches and transfer errors.
-
to maintain data integreity , it is important to establish appropriate policies and procedures , and to implement appropriate technologies , such as encryption , backups , access controls.
-
Data Corrpution - happens when data imegration(when switching from an old system to an old one)
-
There're different types of data integrity that organizations need to consider:
- Entity Integrity: this ensures that each record / row in the table is unqiye and can be uniquely identified , using the primary keys
- Referential Integrity: This ensures that relationships between tables are maintained and that there're no orphaned records , using the foreign keys.
- Domain Integrity: This ensures that data is within acceptable ranges or values , Ex. a age field should only contain valid numeric values.
- Business integrity : Ensuring that data meets business rules and requirements , a bank might have rules around minimum and macimum account balances.
-
To maintain data Integrity we use [Constrains].
-
rules or conditions that are applied to the data to ensure it's integrity and consistency.
-
Constrains can be applied to individual columns or entire tables, they used to enforce various rules and restrictions on the data
-
by using constraints , you can ensure that your data is accurate , consistent , easy to manage.
-
Types of constraints:
-
Primary-key Constraint: this constraint ensures that a column or a set of columns uniquely identifies each row in a table , this constraint helps to enforce data integrity and ensure that there are no duplicated rows in the table.
-
Foreign-key Constraint: This constraint establishes a relation between tow tables based on a key field , it ensures that data in one table matches data in other table , and it helps to maintain refrential integrity in the database.
-
Unique Constraint: This constraint ensures that a column or a set of columns is unqie across all rows in the table , it helps to enforce data integrity and prevent duplicated rows in the table
[!NOTE] > Unique Constraint Vs Primary-Key constraint? The unqie constraint is just like the primary key constraint except that the unique constraint can accept NULL values , however the Primary-key constraint does not.
-
Not-Null Constraint: This constraint ensures that a column or a set of columns doesnt have a null (empty) values , it helps to ensure that data is compelete and accurate
-
Check Constraint: This is more general constraint that ensures that data in a column or set of columns meets a specified condition.
-
-
SQL is used to communicate with a database.
-
SQL lets you access and manipulcate database.
-
Oracle , Sybase , Ms-sql-server , Access , Ingres , etc...
-
Types of Sql Statments:
- DDL = Data Definition Language (CREATE , DROP , ALTER , TRUNCATE)
- DML = Data Manipulation Language (INSERT , UPDATE , DELETE)
- DCL = Data Control Language (GRANT,REVOKE)
- TCL = Transaction Control Language (COMMIT , ROLLBACK , SAVEPOINT)
- DQL = Data Query Language (SELECT)
-
A Diagram to show the full overview on my system database , it's explains the relationship between entities to be stored in a database, it's like UML diagram or C4 diagram
-
the ERD (ER) Diagram is the structure of the database , It acts as a franework (blueprint) with specialized symbols for the purpose of defining the relationship between the databaase entities.
-
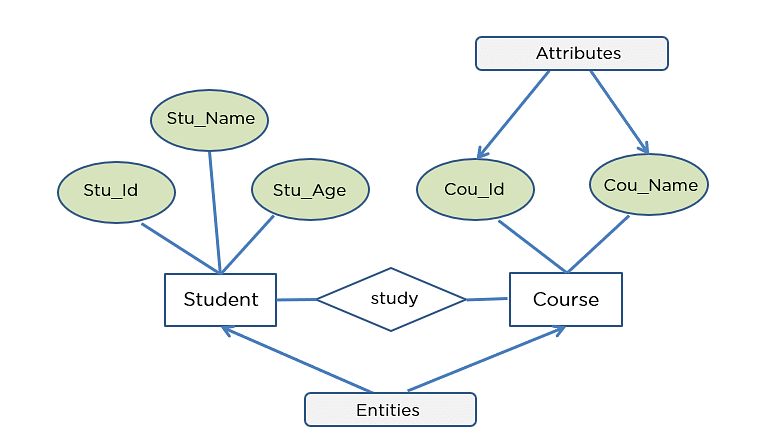
ER diagram is created based on three principal components: (Entities , attricbutes , Relationshhips)
-
A one must consider the good practice and spend lots of time in the planning and designing stage
-
Er Modeling (Entity-Relation Modeling) represents the structre of the database with the help pf diagram.
-
ER modeling is a systematic process to degign a database as it would require you to analze all data requiremenets before implementing your database.
-
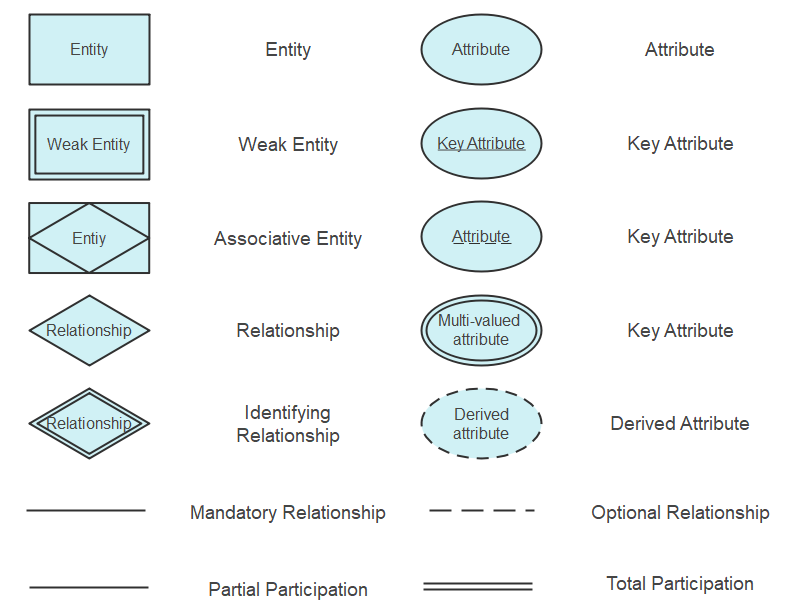
Entity = rectangle... strong Entity (Entity with primary key)
-
To identify the Entity , ask your self a question , do i need to store informations for that entity? if yes so it's a entity
-
The 2 nested 2 rectangles = weak Entity (it has no primary key , prefered not using it)
-
Relation = diamond and lines
-
the Ellipses = attribute.
- if the attribute has more than 1 type , ie. name (first , mid , last) = composite attribute.
- the 2 nested Ellipses = multivalued attribute ( prefered not to say)
-
the doted Ellipses = derived attribute (some attribute is optional , i can derive it fomr another data , like age , employees number...etc)
-
the underscore = primary key (key attribute)
- ER diagram is based on 3 basic concepts:
- Entitis:
- Entity (Strong)
- Weak
- Attributes:
- Attribute
- Key Attribute
- Composite Attribute
- Multivalued Attribute
- Derived Attribute
- Relationships:
- one-to-one
- one-to-many
- many-to-one
- many-to-many
- Entitis:
- An Entity = row or record
- ex , A student Enrolled in course [student]-------(Enrolled)----->[courses]
- You can acheive Entity Integrity by having only strong Entities in ur ER diagram
- Strong Entity does not require another entity in it's work ... it's independenant
- Weak Entity does require another entity to function
- attribues is represented in ERD like this:
-
A relationship has 3 charactristics:
- Degree
- unary(recursive / self-referential)
- Binary between 2 entities
- Ternary among 3 entities
- cardinality
- one-to-one
- one-to-many
- many-to-many
- participation
- total-participation (mandatory)
- partial-participation (optional)
- Degree
-
at first we need to understand how to define a relationship between tow entities , think in the following examples:
-
you have a university system , define the following relationship
[student] -----(?)--->[course]- as you might gussed a student can enroll in an course
[student] ----(enrolls in)--->[course]
- as you might gussed a student can enroll in an course
-
[student] ------(?)----->[id card]=>[student]-----(has an)---->[id card] -
[employee]-------(?)---->[project]=> this relation could be formated in more than 1 relation , you should consider drawing all possible relationships between entities ,[employee]-----(works on)---->[project]or[employee]----(manages)--->[project]
- some entities could have relations with themselfs such as employee , a manager can manage(employee) can manage other employees , so [employee]-----(manages)---->[employee] - imagine it just like this table. ``` |ID | Name | Salary | Manager | |---|---------|--------|---------| |--> | 1 | Ahmed | 5000 | NULL | | | 2 | Mohamed | 1300 | 1 |----| | | 3 | Ali | 1200 | 2 | | -------------------------------------------| ```- relationships are being assigned depends on buissenes requiremenets.
-
being written just like this in ERD diagram
[table1]--1--->(relationship)-----1--->[table2]ex: 1. student ----> id 2. Student ----> person 3. member ---> book (assuming that the buissenes requiremenets obligies me hat only one member can borrow only one book) 4. Traveler ----> seat 5. Employee ----> Desk 6. Employee ----> phone Extention 7. Employee -----> Task (said that the buissenes requirements obligies me that for each employee he takes only one task)
-
- when a single element of an entity is associated with more than one element of another entity , it's called a ont-to-many relationshipt.
- it's being wriiten like this
[table1]---1--->(relation)---M--->[table2]or vice-vercaex:
- customers --> order
[customer] ---- 1 --->(place) --- m--->[order] - order ---> customer
[order] ---- M --->(ordered by) --- 1--->[customer] - Employee --> project
[Employee] ---- M --->(works on) --- 1--->[project] - member ---> book
[member] ---- 1 --->(borrow) --- m--->[book] - cutomer ----> mobile line
[customer] --- 1--->(can have) --- m --->[mobile line]
- customers --> order
-
you might guess it.
-
-
- Cardinality:
- refers to the
Maximumnumber of times an instance in one entity can relate to instances of another entity - Cardinality is used to determine the relationships among entites (one-to-one , ont-to-many , many-to-many)
-
- Ordinality:
-
is the
Minimumnumber of times an instace in one entity can be associated with an instance in the related entity, in other words it specifies if it's optional or mandatory -
in ERD systems we can refere to the Cardinality and ordinalty as follwing
(ordinalty,Cardinality)
-
ex:
[student]--<0>--(Enrolled)---<0>->[cource], in this paper we refer to the ordinalty in <> tags this ERD means that a student could enroll in acource or not so the student entity is optional to the cource entity, a cource could have students or not so it's optional to the student entity.`[customer]----(1,1)---------<Place>--------(0,M)------>[order]` , a customer is required to place an order , but an order doesn't depend on a customer.
- crow-s-foot-notation.
see this
- min-max-notation.
- bachman-notaion.
- review ur course.
- total Participation = mandatory , Partial Participation = optional.
- note that the business requirements should be considered carefully.
-
- Entity Identification =>
Ask your self if this thing should have a data to be stored in the database? - Relationship Identification =>
what is the relation between entity A and entity B - Cardinality Identification =>
what is the cradinality and ordinalty (min ,max) - Identify Attributes.
- Create ERD
- Entity Identification =>
- this site is pretty good for designing ERD erdplus
-
-
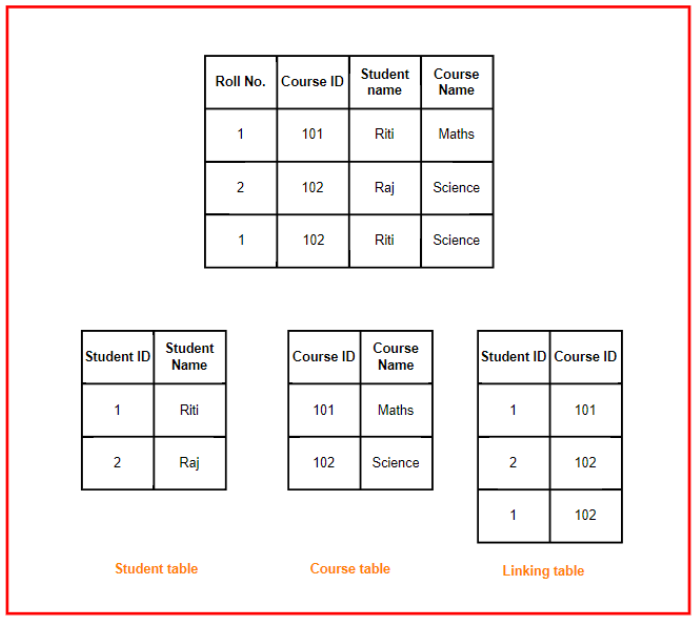
an entity that comes up from connecting a relation with another relation.
-
it's called
junction table,linking table,cross-reference table. -
by using Aggregation / associative-entity , we can represent complex relationships between entities in a structured and efficeint way , without having to duplicate data or create confusing relationships and avoid data redundancy , making it a useful concept om database design.
-
we call it Aggregation becouse when an entity has a relationship with another relationship , a relation with it's corresponding entities is Aggregated into a higher level entity. Aggregation is an abstract through which we can represent relationship as higher level entity set.




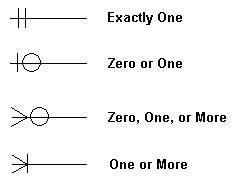
- when we have more than one entity that share many attributes , we can make another entity and make thos entities inherite the base entity usnig the
bottom-up approach - it's represented in ERD using this traingle:
| / \ / IS \ / A \ /---------\ - please note that the head must be at top and the base must be at bottom.
- just remember that Generalization is just like inhertance in OOP
- ex
from student with name and age related with employee with name and age ==> to person who relates with both student and employee - see me

-
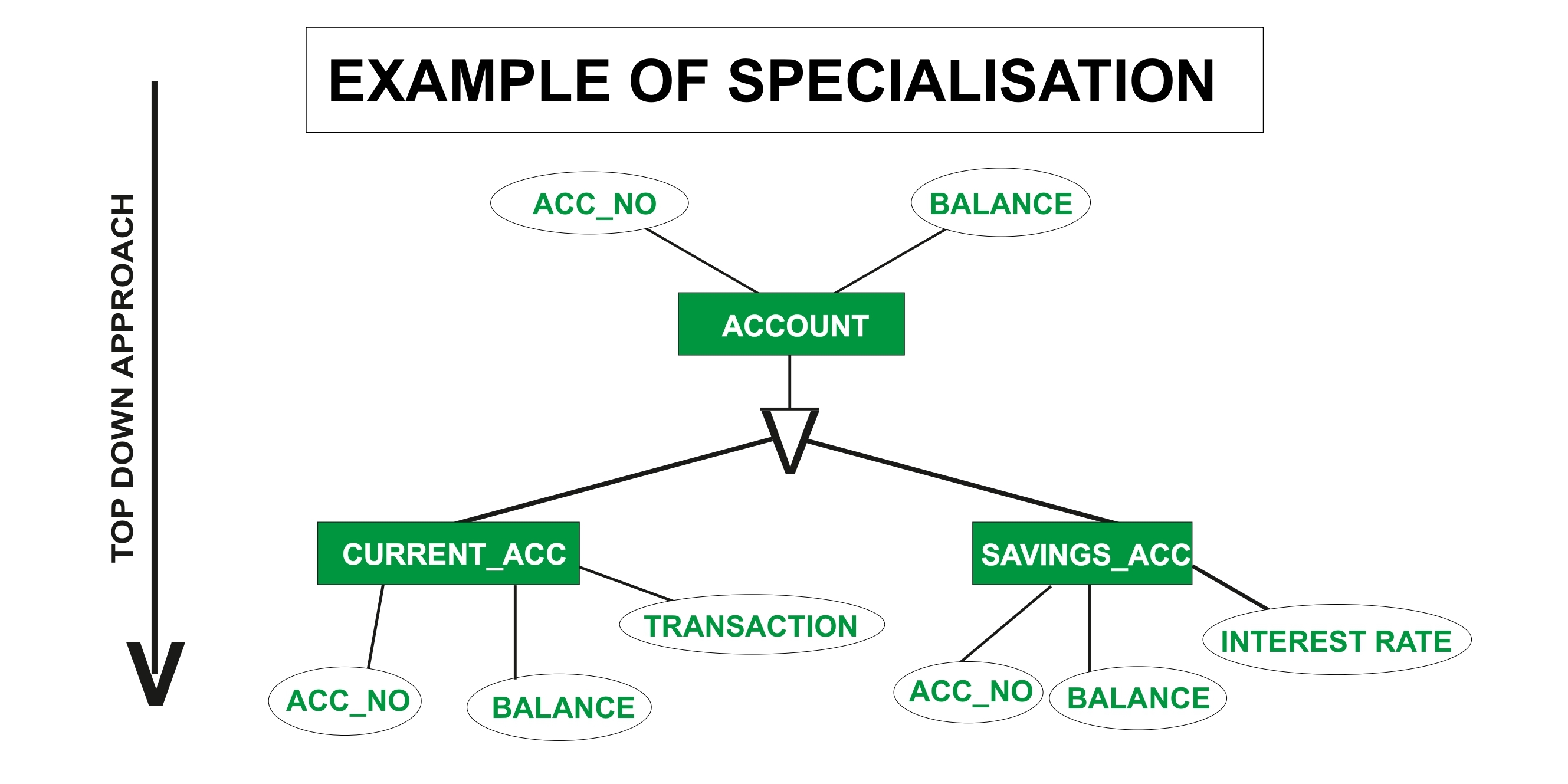
Specialization is a
top-down approachin which a higher-level entity is divided into multiple specialized lower-level entities -
an entity is devided into sub entities with same charactristics.
-
ex:
from employee to developer,from employee to teacher,...etc -
it's represented in ERD using this traingle:
\--------/ \ IS / \ A / \ / | |
-
an eerd is a simplification for the parent-child (superclass-subclass) relationship
-
eerd objects are used when there's data redundancy , which can be generalized / specialized into a superclass or subclass.
-
eerd objects are used when assigning too many attributes to an entity that have weak relation with this entity (typing speed for an employee) , while it has a strong relationship with a subset of that entites (Secretary should have typing speed).
-
there're 3 constrains that are used when dealing with superclass-subclass paradigm.
- when a suberclass is only one of it's subclasses
- when a suberclass could be one or more than it's subclasses.
- when a subclass is only one it's subclasses ,and couldn't be anything else.
- when a subclass could be anyone of it's sublasses or something else.
- a superclass could be one of it's subclasses (that has no relation wich each other , they are different subsets).
- when a suberclass is only one of it's subclasses
-
hence there're tow terms that came up.
-
Hierarchy: every subclass has only one superclass in a tree structure (single inheritance).
-
Lattice: a subclass can be inherite from more than one superclass (Multiple inheritance).
-
-
a set of relational tables and associateed items that are related to each other.
-
relation schema defines the design and structure of the relation like it consists of the relation name , set of attributes/fields , names/columns , every attribute would have an associated Domain
- if we though in the employee examble
(employee)------<manages>---->(employee) - we then design it as follows: in the same table we add a foreign key field to the primary key of the table.
Employee ----------------- PK | EmpID | Name | Salary FK | ManagerID ------------------- in composite attribute we take the roots of the tree ex , name-> firstname, lastname , we take firstname and lastname as attributes
- in derived attribute we ignore it.
- in mutlivalued attributes we make a new entity for it and the public key of the original entity has a foreign key to that table with the same name
ex:
(student) (<stdudentID>) , (name)->((firstname),(lastname)) , (/age/) , ((phone))- we have studentId as a primary key , name as a composite attribute , age as a derived ,, phone as mutlivalued - so this becomes this: ```Student Phone --------------------- ------------- PK | StudentId |---------- Pk | PhoneID | Firstname | | | Phone | LastName | |-----> FK | StudentID --------------------- --------------- ```- take one of the primary key of one entity and put it as a foriegn key in the second table or vice-versa
- ex:
Employee <-----> Acess-card- first solution
Employee AcessCard --------- ----------- PK | EmployeeID ---- PK | CardId | Name | | serial num ... -> FK | EmployeeID ------------ ------------------ - second solution (this is prefered)
Employee AcessCard ------------ --------- PK | EmpID ---- PK | cardID | Name | | Serial num FK | CardID <- ----------------
- first solution
- ex:
Employee <<<--(works in)---> Department
-
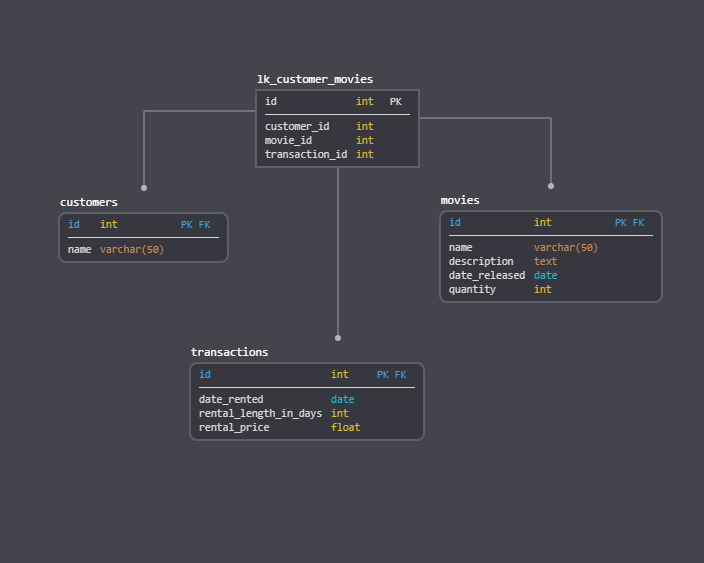
when deailing with many-to-many relationships , you must consider creating the
Bridge Table, that has the public keys of both other tables as a foreign keys -
the middle table is called
Bridge table / Bridge Entity -
note that in the bridge table the tow foriegn keys must be foriegn keys not primary keys , imagine the system when having a student can enroll in course , so we will end up with 3 tables (student , enrollment , course) , if we take the tow primary keys of the tow other tables and put them as a primary keys in the enrolmment table , an edge case will be ingored which is when a student fails in a course he can retake it , but with using the primary keys this will not be able to be achieved , as the primary key is unqiue.
- Take the Primary key from parent and put it in the child as a forign key.
- same as converting many-to-many , but here there will be another table related with the associative entity , we will take it's primary key and put it as a foreign key in the Bridge Entity.
- Self-Refrential One Entity that have a foriegn key that points to thye primary key
- Attributes ignore the derived attribute , take the childs of the composit attributes , create a new table for the mutlivalued attrivutes.
- Generalization , Specailization Take the Primary key of the parent and put it as a foreign key in the child.
- One-To-One take one of the primary key of one entity and put it as a foriegn key in the second table or vice-versa
- One-To-many / Many-To-One take the primary key of one side and put it as a forign key in the many side.
- many-to-many Create a Bridge Table , take the primary key of the tow talbes , put them as a foriegn key in the bridge table
- Assocative same as many-to-many , but now you have to add other tables to the bridge table.
- if we though in the employee examble
-
in this section we wil put our hands on SQL queires using SQL-Server-Managment-Studio
-
The System-databases in SSMS is used to makes you able to excute commands and some other internal stuff, don't fuck with it.
- DDL = Data Defineation language.
- on the databases section just write click and select new database , give it a name and press ok , this is the GUI way to create it
- another way is to use the DDL to create it , select "new Query" and type this query
CREATE DATABASE DB_NAME;, then hit excute button , and write click on the databases and refresh , it will appear.
- another way is to use the DDL to create it , select "new Query" and type this query
- checks if the databases is not exist if not so it will create it .
-
syntax :
IF NOT EXISTS(SELECT * FROM sys.databases WHERE name = 'db_name') BEGIN CREATE DATABASE db_name; END -
let's walk through every line
SELECT * FROM sys.databases WHERE name = 'db_name'this will get the information of database named db_name -
so if this database doesn't exist , create it.
-
to get the databases on the system we use
SELECT * FROM sys.databases;
-
- when we open new_query tab and write soem queries ... on which database it will run?
- it will run on the
masterdatabase , which is a built in system database. , you can switch them using the drop-down list. - syntax:
USE db_name;
- it will run on the
- when we want to delete a database.
- syntax:
DROP DATABASE db_name; - or just write click and delete the database.
- syntax:
- drop a database if and only if it's exists.
- syntax:
IF EXISTS(SELECT * FROM sys.databases WHERE name = 'Martell') begin drop database Martell; end
- creating a table in the database
- syntax:
CREATE TABLE Emploees( ID int NOT NULL, Name NVARCHAR(50) NOT NULL, Phone NVARCHAR(10) NULL, Salary SMALLMONEY NULL, primary key (ID) );
-
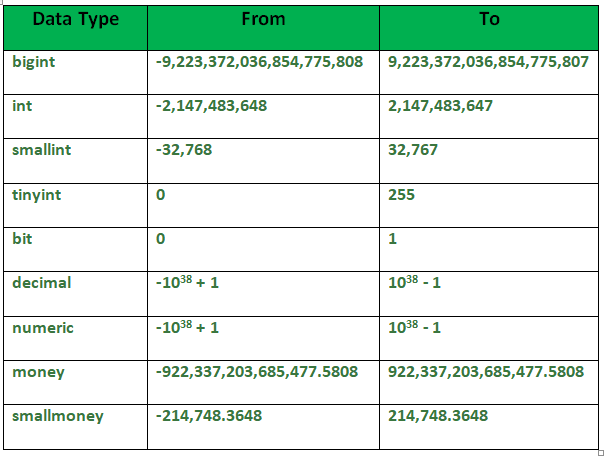
in SQL server there are 7 categories of data types
- Exact Numberics:
- store exact numbers such as integers , decimal...
- the int , bigint , smallint , tinyint stores integer values
- the money , smallmoney stores currency values
- the decimal and numeric stores numbers that have foxed percision and scale
- the bit stores 0,1, NULL
- Aproximate Numeric data types
- stores floating point numeric data , used in scientifc calculations
- float , real
- Character Strings data types
- allow you to store either fixed-length (char) or variable-length (varchar) , in non-unicode (english only)
- char , varchar , varchar(max), text
- Unicode charachter string data types
- allow you to store either fixed-length (char) or variable-length (varchar) , with unicode (english and all other language)
- nchar , nvarchar , ntext
- Date and Time:
- Stores data about date and time.
- datetime , smalldatetime , date , time , datetimeoffset , datetime2
.... and other , google them.
- Exact Numberics:
- delete tables
- syntax:
DROP TABLE table_name;
- syntax:
- this section is a part of DDL , is used to alternating columns and databasess.
- adding a new column with Alter_table
- syntax :
ALTER TABLE table_name ADD Gender data_type(size);
- syntax :
- renaming a column with alter table
- syntax :
- this syntax is used globaly in most of RDBMS , but ms-sql-server doesn't accept it
ALTER TABLE table_name RENAME COLUMN old_name to new_name - ms-sql-server syntax:
exec sp_rename `table.old_name` , `new_name` , 'COLUMN'; - this is a stored prosedure in ms-sql-server , which is like a built in function that takes 3 parameters as you can see in the snippet.
- syntax :
- renaming a table using a stored procedure and alter table.
- syntax:
- in most RDBMS
ALTER TABLE table_name RENAME to new_table_name; - sql-server syntax:
exec sp_rename 'table_name_old' , 'table_name_new';
- in most RDBMS
- syntax:
- modifying the data type and constrains (nullability) , this statmen varies from RDBMS to another
- syntax:
- in SQLserver & postgreSQL:
ALTER TABLE table_name ALTER COLUMN col_nam new_datatype(size) nulll/notnull ; -- note that if you didn't specify the nullability it will be null by default - in MySql & Oracle:
ALTER TABLE table_name MODIFY COLUMN col_name data_type(size);
- in SQLserver & postgreSQL:
- syntax:
- deleting a column in a table, using Alter_table
- syntax:
ALTER TABLE table_name DROP COLUMN col_name;
- syntax:
- adding a new column with Alter_table
- Backing-up database and full Backup
- remember to backup your database in different location as if the server dies , the backup doesn't die.
- fully backing-up your database - full backup is expensive in time and space. - syntax: ``` BACKUP DATABASE db_name TO DISK = 'path'; ```- backing up the changes between the last backup and the current database. - syntax: ``` BACKUP DATABSE DB1 TO DISK = `PATH` WITH DIFFERNTAIL; ```- restoring a database from a backup. - syntax: ``` restore database db_name from disk = 'path'; ``` - if you running a dokcer-container: - syntax: ``` RESTORE DATABASE HR FROM DISK = '/opt/databases/HR_Database.bak' -- could be any path WITH MOVE 'HR_DB' TO '/var/opt/mssql/data/HR_DB.mdf', -- check env vars to know where .mdf files stored MOVE 'HR_DB_log' TO '/var/opt/mssql/data/HR_DB_log.ldf'; -- check env vars. ```
-
this section will discuess DML
- inserting into columns;
- syntax:
INSERT INTO table_name VALUES (VAL1,VAL2,VALE,.....,VALN);- this line will insert one record in the table , where val1,val2,....,valn is the values of each column in the table = we can insert multiple values at a time
INSERT INTO table_name VALUES (VAL1,VAL2,VALE,.....,VALN), (VAL21,VAL22,VALE,.....,VALN), (VAL31,VAL32,VALE,.....,VALN)- please notice that the primary key must be unique and must not be null , if you inserted another column with the same Prmimary key
an error occures:
Violation of PRIMARY KEY constraint 'PK__EMP__3214EC27C8A93E8D'. Cannot insert duplicate key in object 'dbo.table_name'. The duplicate key value is (doblicate_primarykey). - and for null
Cannot insert the value NULL into column 'col_name', table 'DB1.dbo.employees'; column does not allow nulls. INSERT fails.
- you can also specify the columns you want to insert data in
- ex:
insert into employees(ID,Salary) values (415,20)- this will insert the values in only Id,Salary columns , be aware of the nullability of columns as if there's another column which doesn't accept null it will expect an error (null error);
- syntax:
- updating a record according to a condition
- syntax:
update table_name set attribute_name = new_value where (condition(s)) - ex:
update emp set Name = 'Marwan' Where ID = 4; update emp set Name = 'Mohamed' where ID = 7; update emp set Salary = Salary + 100 where Salary < 6000; - please note if you forgot the
wherecondition in this case the condition is true for all records in the database , so all records will be affected
- syntax:
- deleting a record according to a condition
- syntax:
delete from table_name where (condition) - ex:
delete from emp where Salary is null; delete from emp where ID=4; - please not if you forgot the
wherecondition in this case the condition is true for all records in the database , so all records will be affected and it will be deleted , so be aware.
- syntax:
- copying the table's data into another table , if i doesn't exist(the new table)
-
syntax:
select * into new_table from old_table where (condition) -
ex:
select * into empCOpy from emp;- this will copy all the data from emp to empCopy table with all it's data.
select ID into empCopy from emp;- this will copy only the ID column to the new table
select * into empCopy from emp where 1=0;- this will copy the schema (the skeleton) of the table to the new table.
- notice that the where condition in the last ex is false so it will not copy all the data , but it will copy only the schema
- select into , creates the new_table but if it's already exist it will error , if we want to copy the data to a table it already exist we use INSERT_INTO_SELECT_FROM Statment
-
- copying the table's data into an exist table.
- syntax:
insert into new_table select Col from old_table; - ex:
insert into person select * from old_person where age >=30;- this will inserting all the records from old_person table into the person table which it's age is >=30
- syntax:
- to use this statment the existing table's columns must matches the old_table's columns.
- in most of systems the primary key is set to be auto-incremented , in this section we will know how...
-
syntax:
create table EMP( ID int identity(1,1) not null, name nvarchar(50) not null, Primary key(ID) ); -
in the previous examble we created a new table with id and name attributes , the id is auto increamented using the
identityfunction which takes tow parametersidentity(increament,seed)increament is how much you want to increament the id , seed is the starting value. -
please notice that if you deleted the table
delete from EMPand tryed to insert new data ...the id will not start from the seed , insteadit will start from the last value it had hold before deleting -
ex:
delete from EMP; -- will delete the data from the table. insert into EMP Values ({any other columns except the id}); -- will insert some data select * from EMP; -- you will see that last id before deleting will be the first id in the new data -
please not if you insert the id column with insert into statment you will face this error
IDENTITY_INSERT is ON -
to know the last id inserted in the table , you shall use this statment
print @@identity;this is T-SQL will be discuesed later on.
-
- when deleting from a table it will delete the data from the table with a specific condition
whereand it will not reset the increment . - while in the truncate statment it will delete the data from the table with out condition
not whereand it will reset the increment.- syntax:
truncate table tbl_name; - if you excuted this statment
print @@identityit will be 0;
- syntax:
- in this section we will know how to connect tow tables with foreignkey-primarykey theory.
- syntax:
create table customers( id int identity(1,1) not null, first_name nvarchar(50), last_name nvarchar(50), age int, country varchar(40), primary key(id) ); create table orders( ordier_id int identity(1,1) not null, item varchar(40), amount int, customer_id int references customers(id), primary key(ordier_id) );-
in that exable we linked the orders table with constomers using the syntax
customer_id int REFERNCES customers(id), in more abstraction way -
we can use the following syntax as a general solution
id2 datatype references tables's_name(column) -
note that the foreign key constraint protects us against Referntial errors and satisfies the data integreity , as if you wished to delete the customer table you will not be able to do so , it's a violation of referential integreity constraint , as there's a table in our system debends on that table you want to remove , instead you should delete the order table first that's you're garantee that there's no tables in the system debends on customers.
-
you can also create a relation within existing tables using
alterstatment
use DB1; create table customers( id int identity(1,1) not null, first_name nvarchar(50), last_name nvarchar(50), age int, country varchar(40), primary key(id) ); create table orders( ordier_id int identity(1,1) not null, item varchar(40), amount int, customer_id int, primary key(ordier_id) ); alter table orders add foreign key (customer_id) references customers(id); -
- inserting into columns;
-
next we will study the queries of sql , and we will use simple database (link in the repo)
-
we need to restore it.
restore database HR from dist 'path'- if you encounterd anything when you need to veiw the diagrams use the following approach
- you will need to change the owner of the database to the owner that connected to the server (in my case the systemowner)
- code:
use HR; exec sp_changedbowner 'sa';
- selecting columns from tables.
- syntax:
select col1,col2,...coln from table_name; - ex:
select * from employyes;selecing all columns from employees tableselect employees.* from employees;sameselect ID,FirstName,LastName from employees;selecting ID,firstbane,LastName from employees table.
- syntax:
- selecting distinct data from columns.
- syntax:
select distinct col from table - ex:
select distinct FirstName from Employeesselecing the distinct names from Employees table.select distinct FirstName,DepartmentID from Employeesselecting the distinct row which contains firstname and depID;
- syntax:
- we will know how to filter the data with conditions.
- syntax:
[statment 1] where [condition] - ex:
select *from Employees where Gendor='F'; select * from Employees where not MonthlySalary <=500; select * from Employees where MonthlySalary <=500; select * from Employees where MonthlySalary <=500 and CountryID <>1; -- <> opertaor is not equal. select * from Employees where ExitDate is not null;
- syntax:
- used with where statment to search in a set of values.
- ex:
select * from Employees where DepartmentID in (1,2,7); -- will return the DepartmentID= 1 or 2 or 7; select * from Employees where FirstName in ('jacob','Brooks','Harper'); select Departments.Name from Departments where ID in (select DepartmentID from Employees where MonthlySalary <=210); -- this will select the department name which has employees with salary <=210 select Departments.Name from Departments where ID not in (select DepartmentID from Employees where MonthlySalary <=210);
- sorting the data with order_by statment
- ex:
select ID,FirstName,MonthlySalary from Employees where DepartmentID=1 Order By FirstName; => sorting the result with /FirstName(Ascedning order by default). select ID,FirstName,MonthlySalary from Employees where DepartmentID=1 Order By FirstName Desc; => sort them Desceding (Desc) keyword select ID,FirstName,MonthlySalary from Employees where DepartmentID=1 Order By MonthlySalary ASC; => sort them Ascedning (ASC) keyword select ID,FirstName,MonthlySalary from Employees where DepartmentID=1 Order By FirstName ASC,MonthlySalary desc; => sort the firstname Asc , salary desc;
-
selecting top n rows from a colmn or top n percent.
-
ex:
select top 3 * from employees; returng first 3 rows in the database. select top 10 percent * from employees; return first 10 percent of tows in the database. -
ex , write a query that shows the firstname , id , salary of the top 3 paid employees.
select distinct top 3 MonthlySalary from Employees Order By MonthlySalary DESC;- this query shows the top 3 paid employees
select Id,FirstName,LastName,MonthlySalary from Employees where MonthlySalary in( select distinct top 3 MonthlySalary from Employees Order By MonthlySalary DESC; ) Order By MonthlySalary DESC;- this is the answer for out task , we select the name , id , salary from the table , where salary is in the salary returned from the top 3 paid employees.
-
selecting a row and renames it in the output , creating new values and expressions
- syntax:
select col as new_col from table - ex:
select distinct author_id as id from Views where author_id = viewer_id;select A=5*4 , B =6/2 from Employees;select ID ,FirstName ,A = MonthlySalary/2 from Employeesselect ID , FirstName + ' ' + LastName as FullName From Employees;select ID , FullName = FirstName + ' ' + LastName ,MonthlySalary , YearlySalary = MonthlySalary*12 From Employees;select ID , FullName = FirstName + ' ' + LastName ,MonthlySalary , YearlySalary = MonthlySalary*12 , BonusAmount =BonusPerc * MonthlySalary From Employees;select ID , FullName = FirstName + ' ' + LastName , Age = DATEDIFF(year,DateOfBirth,GETDATE()) from Employees;- DATEDIFF , GETDATE functions are explained in SQL-Functions section.
- compined with select statment ro return values in a range
- syntax:
Between R and L;, such that R <= L - ex:
select * from Empoyees where MonthlySalary Between 500 and 1000;
- groups rows rows that have the same values into summary rows, like "find the number of customers in each country"
- syntax:
select col_name from tbl_name where condition group by(col_name); - ex:
select DepartmentID,TotalCount =COUNT(MonthlySalary) , TotalSum = SUM(MonthlySalary), Average = AVG(MonthlySalary), MinSalary=Min(MonthlySalary), MaxSalary=Max(MonthlySalary) from Employees Group BY(DepartmentID) order by (DepartmentID);-
the previous statment will select the DepartmentID , and the other columns and groups them by the DepartmentId
-
notice:
select DepartmentID, TotalCount =COUNT(MonthlySalary) , TotalSum = SUM(MonthlySalary), Average = AVG(MonthlySalary), MinSalary=Min(MonthlySalary), MaxSalary=Max(MonthlySalary) from Employees ;- the previous statment should fails as we select the totalcount , average , min,max .. for all departmenID in the database , so we can't then select the DepartmentId to be shown up.
-
the
Havingclause was added to SQL becuasewherekeyword cannot be used withaggregatefunctions in a direct way -
syntax:
select col from tabl where condition group by(col) HAVING condition; -
ex:
select DepartmentID,TotalCount =COUNT(MonthlySalary) , TotalSum = SUM(MonthlySalary), Average = AVG(MonthlySalary), MinSalary=Min(MonthlySalary), MaxSalary=Max(MonthlySalary) from Employees Group BY(DepartmentID) Having Count(MonthlySalary) > 100 order by (DepartmentID);-
the previous query will select the department , other columns and groups them by depID , with condition that the count of MonthlySalary > 100 (we can't use TotalCount in having as it's still doesn't exist) and order by the department id;
-
since the where statment can't work with aggregate functions (directly), however there's a way to use it (indirectly) by creating a virtual-table.
-
ex:
select * from ( select DepartmentID,TotalCount =COUNT(MonthlySalary) , TotalSum = SUM(MonthlySalary), Average = AVG(MonthlySalary), MinSalary=Min(MonthlySalary), MaxSalary=Max(MonthlySalary) from Employees Group BY(DepartmentID) ) R1 where TotalCount > 100 order by (DepartmentID);- notice that the R1 is a
virtual-tablecontains all the columns listed in the inner statment , so we can acess it and use where statment.
-
search and filter a specified pattern in a column.
-
there're tow WildCards used with Like statment:
- the
%sign represents zero , one , or multiple charachters - the
_sign represents one , single charachter
- the
-
note that MS-Acess uses
* instead of %and uses? instead of _ -
ex(s):
select Id , FirstName from Employees where FirstName like 'a%'; // select the FirstName,Id for those FirstNames statrs with a select Id , FirstName from Employees where FirstName like '%a'; // select the FirstName,Id for those FirstNames ends with a select Id , FirstName from Employees where FirstName like '%tell%'; // select the FirstName,Id for those FirstNames have the substring tell select Id , FirstName from Employees where FirstName like 'a%a'; // select the FirstName,Id for those FirstNames statrs,ends with a select Id , FirstName from Employees where FirstName like '_a%'; // select the FirstName,Id for those FirstNames the second letter is a select Id , FirstName from Employees where FirstName like '__a%'; // select the FirstName,Id for those FirstNames thee third letter is a select Id , FirstName from Employees where FirstName like 'a___%'; // select the FirstName,Id for those FirstNames statrs with a and have at least 3 charachters after a select Id , FirstName from Employees where FirstName like 'a%' or FirstName like 'b%'; // start with a or b
- used to substitute one or more charachter in a string.
- enhance the searchin process in sql
------------------------------------------------------------------------------------------------------- symbole | Description | example ------------------------------------------------------------------------------------------------------- % | Represents zero or more chars | bl% finds bl in the start -------------------------------------------------------------------------------------------------------- _ | Represents a single char | h_t the first is h , the third is t -------------------------------------------------------------------------------------------------------- [] | a single char within brackets or range | h[oa] h followed by o or a ----------------------------------------------------------------------------------------------------------- ^ | represents any char not in brackets or range | h[^oa] h followed by any chars but not a or o ------------------------------------------------------------------------------------------------------------- ex:
select ID, FirstName , LastName from Employees where FirstName not like 'Mohamm[ea]d'; select ID, FirstName , LastName from Employees where FirstName like '[abc]%' ORDER BY (FirstName)DESC ; select ID, FirstName , LastName from Employees where FirstName like '[a-l]%'; - syntax:
-
the following section will demonstart a set of built-in functions in (SQL) that helps getting things done.
-
all the following function works for
NOT NULLvalues.- returns the length of varcahr /nvarchar / string
- syntax
LEN(col) - ex
select tweet_id from Tweets where LEN(content) > 15;
- returns the cound of rows meet a specific criterion(condition).
- ex:
select TotalCont = Count(MonthlySalary) From Employees where MonthlySalary Between 500 and 1000; - returns the count of employees that thier pay is from 500 to 1000.
- returns the sum of a numeric column.
- ex
select TotalSum =Sum(MonthlySalary) From Employees; - returns the sum of all salaries.
- returns the average value in a numeric column.
- ex :
select Average= AVG(MonthlySalary) from Employees; - ana zahakt....
- returns the minimum value in a numeric column.
- ex:
select MinValue = Min(MonthlySalary) From Employees;
- returns the Maximum values in a numeric column.
- ex:
select MaxValue = Max(MonthlySalary) From Employees;
-
note that:
If you use an aggregate function and select other columns, you must use a GROUP BY clause to tell SQL how to group the non-aggregated columns.
- The EXISTS operator is used to test for the existence of any record in a subquery.
- The EXISTS operator returns TRUE if the subquery returns one or more records.
select X='yes' where exists ( select * from Orders where customerID= 3 and Amount < 600 ) select * from Customers T1 where exists ( select * from Orders where customerID= T1.CustomerID and Amount < 600 ) --More optimized and faster select * from Customers T1 where exists ( select top 1 * from Orders where customerID= T1.CustomerID and Amount < 600 ) --More optimized and faster select * from Customers T1 where exists ( select top 1 R='Y' from Orders where customerID= T1.CustomerID and Amount < 600 )- The UNION operator is used to combine the result-set of two or more SELECT statements.
- Every SELECT statement within UNION must have the same number of columns
- The columns must also have similar data types
- The columns in every SELECT statement must also be in the same order
- Union is selecting the distinct elements from each set.
select * from ActiveEmployees select * from ResignedEmployees select * from ActiveEmployees Union select * from ResignedEmployees --this will remove the redundancy from the resultset (distinct results only) select * from Departments union select * from Departments; --this will append data regardeless of any redundancy select * from Departments union ALL select * from Departments;- The CASE expression goes through conditions and returns a value when the first condition is met (like an if-then-else statement). So, once a condition is true, it will stop reading and return the result. If no conditions are true, it returns the value in the ELSE clause.
- If there is no ELSE part and no conditions are true, it returns NULL.
- syntax:
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 WHEN conditionN THEN resultN ELSE result END;- ex:
select ID , FirstName , LastName , GenderTitle = case when Gendor = 'f' then 'Female' when Gendor = 'm' then 'Male' else 'Unkown' end, Status= case when ExitDate is null then 'Active' when ExitDate is not null then 'Deacyive' end, NewSalary= case when Gendor = 'f' then MonthlySalary * 1.15 when Gendor = 'm' then MonthlySalary * 1.1 else MonthlySalary end from Employees-
how to manipulate the data from more than one table and compine them in one table.
-
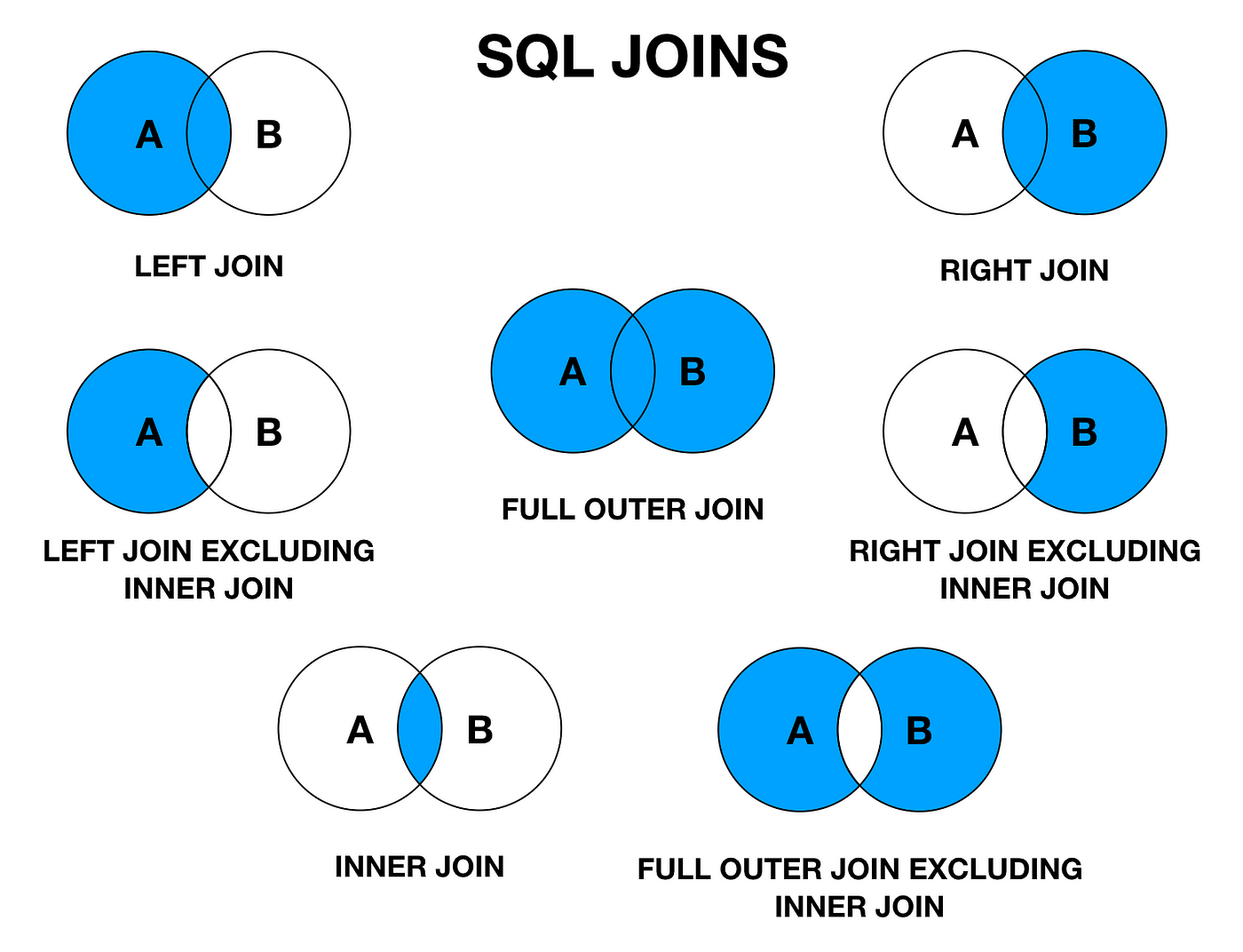
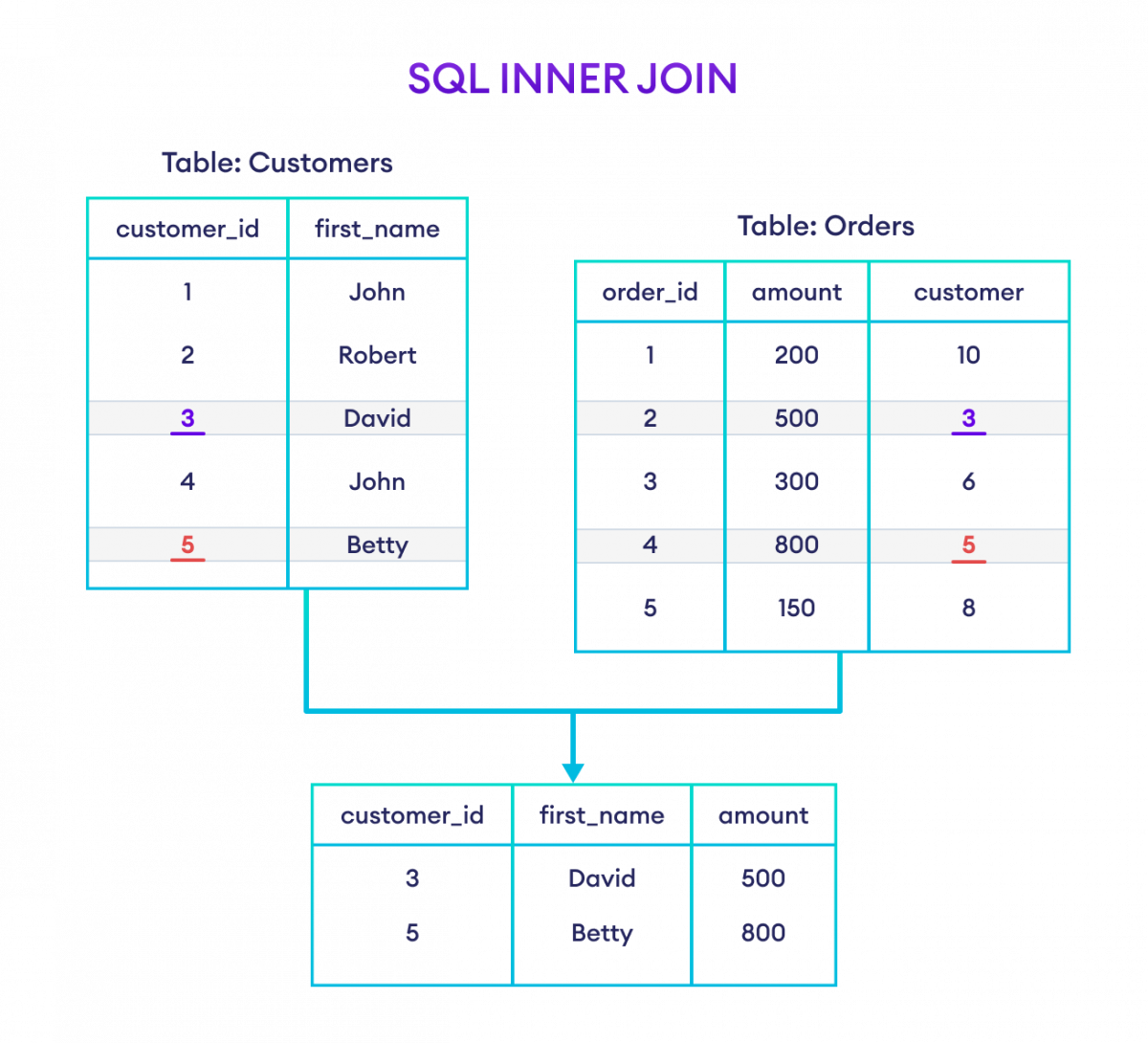
The SQL JOIN is a command clause that combines records from two or more tables in a database
-
Joins has 6 types , we will study the most important 4:
- Inner Join
- Left join
- Right join
- Full outer Join
-
This is the most common type of join. Inner joins combine records from two tables whenever there are matching values in a field common to both tables
-
syntax:
select columns from table1 INNER JOIN (or just JOIN) table2 on table1.colname = table2.colname; -
ex:
select Customers.CustomerID , Customers.Name , Orders.Amount from Customers Inner join Orders On Customers.CustomerID = Orders.CustomerID;- this query returns the result in the figure above.
select Employees.ID,Employees.FirstName,Employees.LastName , Departments.Name as DepartmentName, Countries.Name as CountryName from Employees JOIN Departments On Employees.DepartmentID = Departments.ID JOIN Countries On Employees.CountryID = Countries.ID;- in the above examble we have joined 3 tables , and we can do operations on them..
select Employees.ID,Employees.FirstName,Employees.LastName , Departments.Name as DepartmentName, Countries.Name as CountryName from Employees JOIN Departments On Employees.DepartmentID = Departments.ID JOIN Countries On Employees.CountryID = Countries.ID where Countries.Name = 'USA';
-
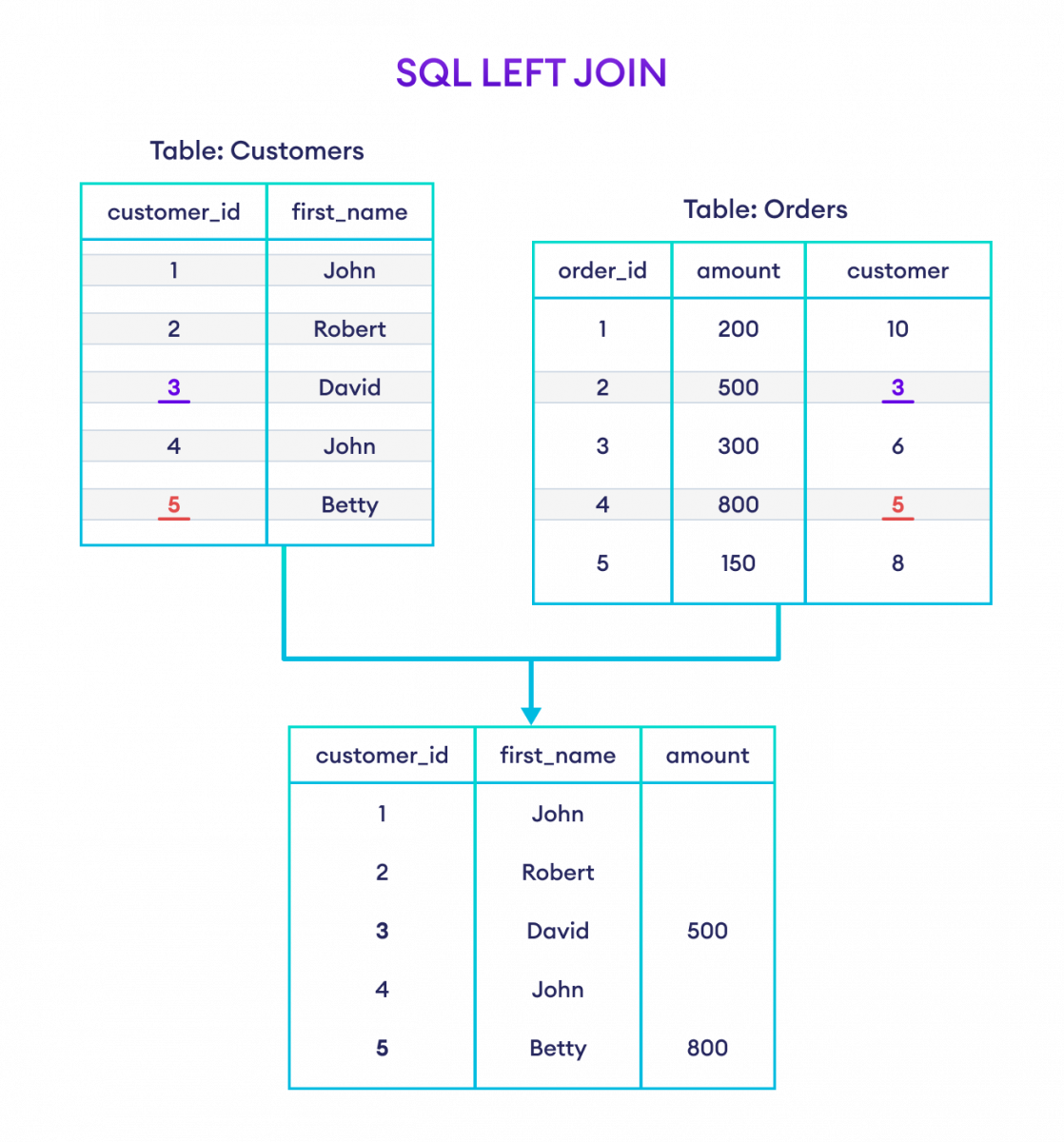
returns all records from the left table , and the matching records from the right table , the result is NULL records from the right side , if there's no match
-
ex:
select Customers.CustomerID ,Customers.Name ,Orders.Amount From Customers Left Join Orders ON Customers.CustomerID = Orders.CustomerID;
-
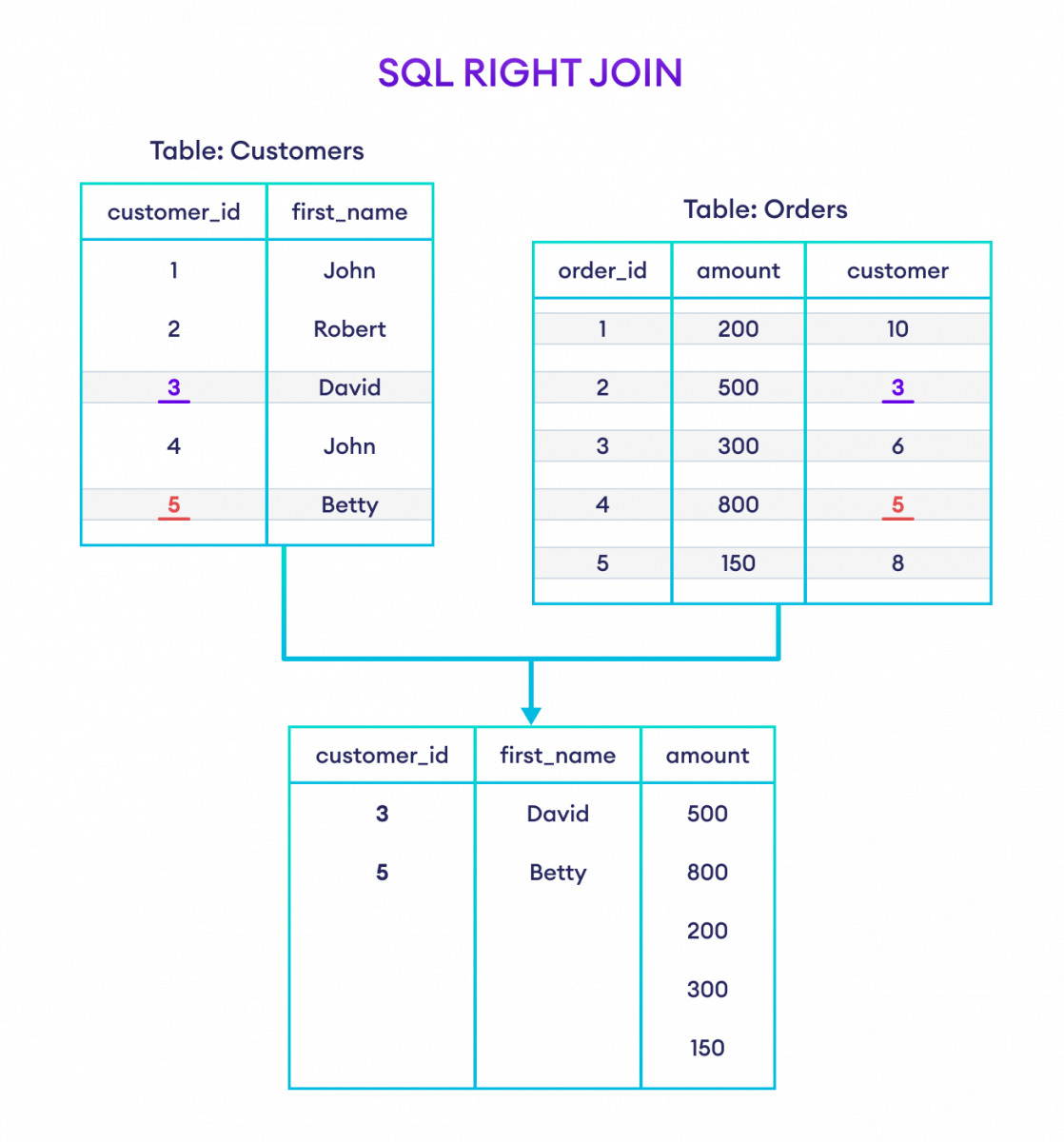
returns all records from the right table , and the matching records from the left table.
-
ex:
select Customers.CustomerID ,Customers.Name ,Orders.Amount From Customers right Join Orders ON Customers.CustomerID = Orders.CustomerID;
-
returns all data from both right and left tables.
-
ex:
select Customers.CustomerID ,Customers.Name ,Orders.Amount From Customers full Join Orders ON Customers.CustomerID = Orders.CustomerID;
-
In SQL, a view is a virtual table based on the result-set of an SQL statement.
-
A view contains rows and columns, just like a real table. The fields in a view are fields from one or more real tables in the database.
-
You can add SQL statements and functions to a view and present the data as if the data were coming from one single table.
-
A view always shows up-to-date data! The database engine recreates the view, every time a user queries it.
-
ex:
use HR; create view data1 as select * from Employees where ExitDate is null; select * from data1;
-
Constraints are used to limit the type of data that can go into a table. This ensures the accuracy and reliability of the data in the table. If there is any violation between the constraint and the data action, the action is aborted.
-
Constraints can be column level or table level. Column level constraints apply to a column, and table level constraints apply to the whole table.
-
NOT NULL - Ensures that a column cannot have a NULL value
-
UNIQUE - Ensures that all values in a column are different
-
PRIMARY KEY - A combination of a NOT NULL and UNIQUE. Uniquely identifies each row in a table
-
FOREIGN KEY - Prevents actions that would destroy links between tables
-
CHECK - Ensures that the values in a column satisfies a specific condition
-
DEFAULT - Sets a default value for a column if no value is specified
-
CREATE INDEX - Used to create and retrieve data from the database very quickly
-
Constraints can be specified when the table is created with the
CREATE TABLEstatement, or after the table is created with theALTER TABLEstatement. -
syntax:
CREATE TABLE table_name ( column1 datatype constraint, column2 datatype constraint, column3 datatype constraint, .... );-
Basic Info: The PRIMARY KEY constraint uniquely identifies each record in a table.
Primary keys must contain UNIQUE values, and cannot contain NULL values.
A table can have only ONE primary key; and in the table, this primary key can consist of single or multiple columns (fields).
-
Creating the Primary Key Constraint:
- Using Create Table:
- ex:
CREATE TABLE Persons ( ID int NOT NULL PRIMARY KEY, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int ); - To allow naming of a PRIMARY KEY constraint, and for defining a PRIMARY KEY constraint on multiple columns, use the following SQL syntax:
CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT PK_Person PRIMARY KEY (ID,LastName) ); - ex:
- Using Alter Table:
- To create a PRIMARY KEY constraint on the "ID" column when the table is already created, use the following SQL:
ALTER TABLE Persons ADD PRIMARY KEY (ID); - To allow naming of a PRIMARY KEY constraint, and for defining a PRIMARY KEY constraint on multiple columns, use the following SQL syntax:
alter table Persons Add constraint PK_Person Primary Key(ID,First); - Note: If you use ALTER TABLE to add a primary key, the primary key column(s) must have been declared to not contain NULL values (when the table was first created).
- Using Create Table:
-
Drop Primary Key Constraint:
- To drop a PRIMARY KEY constraint, use the following SQL:
ALTER TABLE Persons DROP CONSTRAINT PK_Person;
- To drop a PRIMARY KEY constraint, use the following SQL:
-
Basic Info:
- The FOREIGN KEY constraint is used to prevent actions that would destroy links between tables.
- A FOREIGN KEY is a field (or collection of fields) in one table, that refers to the PRIMARY KEY in another table.
-
Creating the Foreign Key Constraint.
- Using Create Table:
CREATE TABLE Orders ( OrderID int NOT NULL PRIMARY KEY, OrderNumber int NOT NULL, PersonID int FOREIGN KEY REFERENCES Persons(PersonID) );- To allow naming of a FOREIGN KEY constraint, and for defining a FOREIGN KEY constraint on multiple columns, use the following SQL syntax:
CREATE TABLE Orders ( OrderID int NOT NULL, OrderNumber int NOT NULL, PersonID int, PRIMARY KEY (OrderID), CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID) REFERENCES Persons(PersonID) );
- To allow naming of a FOREIGN KEY constraint, and for defining a FOREIGN KEY constraint on multiple columns, use the following SQL syntax:
- Using Create Table:
-
Using Alter Table:
- ex(s):
ALTER TABLE Orders ADD FOREIGN KEY (PersonID) REFERENCES Persons(PersonID); ALTER TABLE Orders ADD CONSTRAINT FK_PersonOrder FOREIGN KEY (PersonID) REFERENCES Persons(PersonID);
- ex(s):
-
Drop Foreign Key constraint:
ALTER TABLE Orders DROP CONSTRAINT FK_PersonOrder;
-
not null is a column level constraint
-
The following SQL ensures that the "ID", "LastName", and "FirstName" columns will NOT accept NULL values when the "Persons" table is created:
CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255) NOT NULL, Age int ); -
Alter Table:
ALTER TABLE Persons ALTER COLUMN Age int NOT NULL;
-
The DEFAULT constraint is used to set a default value for a column.
-
The default value will be added to all new records, if no other value is specified.
-
create default constraint using create table:
CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, City varchar(255) DEFAULT 'Amman' );- The DEFAULT constraint can also be used to insert system values, by using functions like
GETDATE():CREATE TABLE Orders ( ID int NOT NULL, OrderNumber int NOT NULL, OrderDate date DEFAULT GETDATE() );
- The DEFAULT constraint can also be used to insert system values, by using functions like
-
create using Alter table
alter table persons add constraints DF_city Default 'aman' for City -
droping it:
alter table Persons drop CONSTRAINT df_city;
-
The CHECK constraint is used to limit the value range that can be placed in a column.
-
If you define a CHECK constraint on a column it will allow only certain values for this column.
-
If you define a CHECK constraint on a table it can limit the values in certain columns based on values in other columns in the row.
-
creating it:
create table Persons( id int not null, lastname varchar(255) not null, firstname varchar(255) not null, age int , city varchar(255), constraint Chk_person check(age >=18 and city = 'aman') ); -
droping it , it's the same as the above examples mate2rfnash m3ak
-
The UNIQUE constraint ensures that all values in a column are different.
-
Both the UNIQUE and PRIMARY KEY constraints provide a guarantee for uniqueness for a column or set of columns.
-
A PRIMARY KEY constraint automatically has a UNIQUE constraint.
-
However, you can have many UNIQUE constraints per table, but only one PRIMARY KEY constraint per table.
-
create table:
CREATE TABLE Persons ( ID int NOT NULL UNIQUE, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int );CREATE TABLE Persons ( ID int NOT NULL, LastName varchar(255) NOT NULL, FirstName varchar(255), Age int, CONSTRAINT UC_Person UNIQUE (ID,LastName) ); -
using alter table:
ALTER TABLE Persons ADD UNIQUE (ID); -
droping:
ALTER TABLE Persons DROP CONSTRAINT UC_Person;
- Index = B-Tree (data structure)
- indexes are a way to make the data retrieval operations more faster than otherwise
- the indexes creates a hidden table that table sort the data by the attribute we want to make an index for it (non-clusterd index)
- a normal table has an existing index called (clusterd-index) it sortes the data by the primary key of the table
- note that updating operations takes time on the indexed table (as if we update the normal table we will need to update the indexed table) so make sure that the indexes are being applied to the attribues that i frequently searching for.
- the physical index (primarykey) is faster than the non-clusterd index.
create index idx1 on Person(FirstName);drop index Person.idx1;- The Normalization Process if the process of organizing data in database in a way to reduce data anamolies such as data redundancy and data inconsistency.
- We break down the the large database into smaller , managable pieces while ensuring the data is free from redundancies and consisntent.
- Normalization is Acheived By applying a set of rules Called normal forms , the higher normal form the more restrictions applyed.
-
A primary key: A unique identifier for each record in the table.
-
Atomic values: Each column should contain only a single value, and each value should be indivisible. • Note: Here, atomicity states that a single cell cannot hold multiple values. It must hold only a single-valued attribute. • The First normal form disallows the multi-valued attribute, composite attribute, and their combinations.
-
No repeating groups: Each column should have a distinct name, and there should be no repeating groups of columns.
-
to optain 2NF , 1NF must be hold.
- Second Normal Form (2NF) is a further level of database normalization that builds on the First Normal Form (1NF) rules.
- It requires that each non-key column in a table be functionally dependent on the entire primary key, not just a part of it.
- No partial dependencies: Each non-key column in the table must be fully dependent on the entire primary key.
- Third Normal Form (3NF) is a higher level of database normalization that builds on the rules of First Normal Form (1NF) and Second Normal Form (2NF). It requires that each nonkey column in a table be dependent only on the primary key, and not on any other non-key columns.
- No transitive dependencies: Each non-key column in the table must be dependent only on the primary key, and not on any other non-key columns.
- to be continued...


- To be continued....